

Wan2.7-Image ของ Alibaba ที่เปิดตัวเมื่อวันที่ 1 เมษายน 2026 ถือเป็นก้าวกระโดดครั้งสำคัญของการสร้างภาพด้วย AI โมเดลแบบรวมนี้ผสานการสร้างภาพจากข้อความ การแก้ไขแบบโต้ตอบ การประกอบหลายภาพ และความเข้าใจเชิงความหมายไว้ในสถาปัตยกรรมเดียว แตกต่างจากสายงานที่แยกกันระหว่างการสร้างและการแก้ไขแบบดั้งเดิม จึงขจัดความไม่สอดคล้องอย่าง “ใบหน้า AI มาตรฐาน” ข้อความเพี้ยน และสีที่คาดเดาไม่ได้
ครีเอเตอร์ นักออกแบบ นักการตลาด และองค์กร สามารถได้ภาพถ่ายเสมือนจริงและตรงตามคำสั่งมากขึ้นด้วยรอบการลองผิดลองถูกที่น้อยลง โมเดลรองรับภาพต่อเนื่องสูงสุด 12 ภาพ การผสานอ้างอิงสูงสุด 9 ภาพ การเรนเดอร์ข้อความได้ 12 ภาษา (สูงสุด 3,000 โทเค็น) และการควบคุมในระดับพิกเซล
Wan2.7-Image คืออะไร?
Wan2.7-Image คือโมเดลภาพแบบรวมระดับเรือธงของ Tongyi Lab ภายใต้ซีรีส์ Wan (Tongyi Wanxiang) ของ Alibaba ที่รองรับเวิร์กโฟลว์ภาพแบบครบวงจร: สร้างภาพจากข้อความ แปลงภาพต่อภาพ แก้ไขตามคำสั่ง และปรับละเอียดแบบโต้ตอบระดับพิกเซล—ทั้งหมดนี้อยู่ใน latent space ร่วมเดียวกัน
เปิดตัวเมื่อวันที่ 1 เมษายน 2026 โมเดลนี้ต่อยอดจากโมเดลวิดีโอ Wan 2.x (ซึ่งเคยทำคะแนนสูงสุดใน VBench) โดยเปลี่ยนโฟกัสสู่ความแม่นยำด้านภาพโดยตรง มันจัดการกับ “ความเบื่อหน่ายทางสุนทรียะ” ที่เกิดจากใบหน้าซ้ำๆ สีไม่เสถียร และการเกาะคำสั่งที่อ่อนในเครื่องมือยุคก่อน สำหรับผู้ใช้ ชื่อที่สำคัญมีสองรุ่น: wan2.7-image และ wan2.7-image-pro รุ่นมาตรฐานปรับจูนเพื่อให้ สร้างผลลัพธ์ได้เร็วกว่า ส่วนรุ่น Pro มุ่งสู่ งานระดับมืออาชีพ พร้อม รองรับความละเอียด 4K
จุดต่างหลัก: สถาปัตยกรรมแบบรวม (unified architecture) โมเดลดั้งเดิมใช้ขั้นตอนที่แยกส่วน (encoder → diffusion → decoder) และต้องทำ inpainting แยกสำหรับงานแก้ไข Wan2.7-Image ทำแผนที่เชิงความหมายลงในพื้นที่ร่วมเดียว จึง “เข้าใจ” จริง ไม่ใช่แค่จับรูปแบบพิกเซล
ทำไม Wan2.7-Image จึงสำคัญ (บริบทอุตสาหกรรม)
เครื่องมือภาพ AI แบบดั้งเดิมเผชิญปัญหา:
| ปัญหา | คำอธิบาย |
|---|---|
| เวิร์กโฟลว์กระจัดกระจาย | แยกเครื่องมือระหว่างสร้าง แก้ไข และ inpainting |
| “AI face syndrome” | ใบหน้าคนที่ซ้ำซากและไม่สมจริง |
| การเกาะคำสั่งอ่อน | ไม่ปฏิบัติตามพรอมต์อย่างแม่นยำ |
| การเรนเดอร์ข้อความคุณภาพต่ำ | ตัวอักษรบิดเบี้ยวหรืออ่านไม่ออก |
| เอาต์พุตหลายภาพไม่สอดคล้อง | ตัวละครเปลี่ยนไปในแต่ละเฟรม |
Wan2.7-Image แก้ข้อจำกัดเหล่านี้โดยตรงด้วย สถาปัตยกรรมแบบรวม + เลเยอร์ความเข้าใจเชิงความหมาย
5 ฟีเจอร์หลักของ Wan2.7-Image
1. ปรับแต่งอวาตาร์ระดับโครงหน้า เพื่อใบหน้าที่ไม่ซ้ำจริงๆ
Wan2.7-Image โดดเด่นเรื่อง “หนึ่งคน หนึ่งใบหน้าเฉพาะตัว” รองรับการควบคุมละเอียดถึงระดับโครงหน้า ทรงตา (อัลมอนด์ ฟีนิกซ์ ตาลึก ตาบวม ตายิ้ม) เส้นกรอบหน้า และรายละเอียดละเมียดอื่นๆ จึงขจัดปัญหา “ใบหน้า AI มาตรฐาน” ที่รุ่นก่อนเผชิญ

ตัวอย่างพรอมต์: “ภาพพอร์ตเทรตเสมือนจริงของผู้หญิงเอเชียตะวันออกอายุ 28 ปี หน้ารูปไข่ ดวงตาทรงอัลมอนด์ รอยยิ้มบางๆ ผิวละเอียด แสงธรรมชาติ” ผลลัพธ์แสดงความหลากหลายสมจริง เหมาะกับอินฟลูเอนเซอร์เสมือนจริง ตัวละครเกม หรือการสร้างแบรนด์เฉพาะบุคคล
2. ควบคุมเฉดสีอย่างแม่นยำ
อีกฟีเจอร์ที่ใช้งานได้จริงคือการควบคุม พาเลตต์สี ผู้ใช้สามารถป้อนโค้ดสีและสัดส่วนเฉพาะ เพื่อทำซ้ำสไตล์ศิลป์หรือยึดสีแบรนด์ เอกสาร API กำหนดพารามิเตอร์ color_palette ให้รับสี 3 ถึง 10 สี โดย แนะนำ 8 สี สำหรับทีมแบรนด์ นี่คือฟีเจอร์องค์กรที่ชัดเจนที่สุดในรุ่นนี้ หมดยุคเฉดสีสุ่ม—ได้ความสอดคล้องข้ามแคมเปญอย่างสมบูรณ์
คำกล่าวอย่างเป็นทางการ: “บอกลาการสุ่มสี สร้างสัดส่วนสีอย่างแม่นยำและถ่ายทอดวิสัยทัศน์สร้างสรรค์ของคุณให้มีชีวิตจริง” — Tongyi Wanxiang
3. การเรนเดอร์ข้อความหลายภาษาขั้นสูง (12 ภาษา, 3,000 โทเค็น)
เรนเดอร์ข้อความยาวมาก ตาราง สูตร สมการ แผนภูมิ และอินโฟกราฟิกด้วยความคมชัดระดับงานพิมพ์ (เทียบเท่า A4) รองรับจีน อังกฤษ ญี่ปุ่น เกาหลี และอีก 8 ภาษา งานวิชาการ โปสเตอร์ ฉลากสินค้า และแบนเนอร์หลายภาษามีความคมชัดแทบไร้ที่ติ—แก้จุดอ่อนประวัติศาสตร์ของ AI
4. แก้ไขแบบโต้ตอบแม่นยำระดับพิกเซลด้วยเครื่องมือ Marquee
ใช้กรอบกำหนดขอบเขต (editRegions) หรือเครื่องมือ marquee เพื่อปรับเฉพาะส่วน อัปโหลดอ้างอิงได้สูงสุด 9 ภาพ แล้วสั่งแก้ไข เช่น “เปลี่ยนฉากหลังเป็นชายหาดยามพระอาทิตย์ตก โดยยังคงใบหน้า โพส และเสื้อผ้าเดิม” ความแม่นยำระดับพิกเซลช่วยรักษาเอกลักษณ์บุคคล
5. การสร้างเชิงประกอบหลายภาพ (สูงสุด 12 ภาพต่อชุด)
โมเดลนี้ออกแบบให้มากกว่าการสร้างภาพจากพรอมต์เดียว Alibaba ระบุว่าสามารถใช้อ้างอิงได้ สูงสุด 9 ภาพ และสร้าง ได้สูงสุด 12 ภาพพร้อมกัน เหมาะสำหรับสตอรีบอร์ด สถาปัตยกรรม และชุดภาพอีคอมเมิร์ซ โฟลว์ “คลิกเพื่อแก้ไข” ให้เลือกพื้นที่เฉพาะและปรับด้วย ความแม่นยำระดับพิกเซล และเอกสาร API ยังเพิ่มการแก้ไขเชิงโต้ตอบแม่นยำผ่านพารามิเตอร์ bounding-box สำหรับงานแก้ไขเฉพาะจุด
Wan2.7-Image ทำงานอย่างไร? (เชิงเทคนิค)
Alibaba อธิบายว่า Wan2.7-Image เป็นกรอบงานที่เชื่อมภาษากับภาพด้วยการเทรนบนชุดข้อมูลที่ใหญ่มากและหลากหลาย พูดง่ายๆ โมเดลไม่ได้แค่ “วาดภาพ” แต่ยังเรียนรู้ความเชื่อมโยงระหว่างพรอมต์กับโครงสร้างภาพ องค์ประกอบ แสง และตำแหน่งข้อความ นี่เองที่ทำให้ตีความเจตนาผู้ใช้ได้แม่นยำกว่าระบบ text-to-image พื้นฐาน
API ยังชี้ว่าโมเดลรองรับอินพุตหลายโมดัลจริงๆ ในการใช้งานจริง คำขอถูกส่งผ่านโครงสร้างข้อความแบบรอบเดียว โดยคอนเทนต์รวมทั้งรายการข้อความและภาพ สำหรับการแก้ไข ผู้ใช้ส่งภาพหลายใบพร้อมคำสั่ง เช่น “ย้าย” “แทนที่” หรือ “blend” เพื่อกำหนดผลลัพธ์ได้ ชัดเจนว่า Wan2.7 ถูกออกแบบเป็นระบบ prompt-and-reference ไม่ใช่ตัวสร้างแบบยิงครั้งเดียว
เอกสารยังเปิดเผยการตั้งค่าโหมดคิด (thinking mode) ซึ่งเปิดโดยค่าเริ่มต้นและช่วยเพิ่มคุณภาพเอาต์พุต แต่จะเพิ่มเวลาในการสร้าง นี่เป็นเบาะแสสำคัญของเวิร์กโฟลว์: เอาต์พุตคุณภาพสูงอาจต้องใช้เวลา inference ภายในมากขึ้น โดยเฉพาะเมื่อคำขอยาวหรือซับซ้อนทางภาพ
Wan2.7-Image ใช้ กรอบงานสร้าง-แก้ไขแบบรวม ใน latent space ร่วมเดียว:
- ขั้นอินพุต: ข้อความพรอมต์ (สูงสุด 3,000 โทเค็น) + ภาพอ้างอิงทางเลือก (สูงสุด 9 ภาพ)
- การวิเคราะห์เชิงความหมาย & โหมดคิด (ยกระดับใน Pro): ใช้การให้เหตุผลแบบ chain-of-thought วิเคราะห์องค์ประกอบ ความสัมพันธ์เชิงพื้นที่ แสง และตรรกะ “ก่อน” การสร้างพิกเซล
- การแมปสู่ latent space ร่วม: เชิงความหมายถูกแมปตรงสู่คุณลักษณะภาพ—ไม่เกิดช่องว่าง encoder/decoder แบบแยกส่วน
- การอนุมานแบบรวม: การสร้างหรือแก้ไขเกิดในโฟลว์เดียวที่ปรับแต่งแล้ว พื้นที่แก้ไขใช้กรอบกำหนดขอบเขต และพาเลตต์สีกำหนดสัดส่วน
- เอาต์พุต: ภาพความคมชัดสูง (มาตรฐาน 768–2048×2048; 4K ใน Pro) มีตัวเลือก JPG/PNG/WEBP มี seed เพื่อทำซ้ำได้ และมีระบบตรวจความปลอดภัย
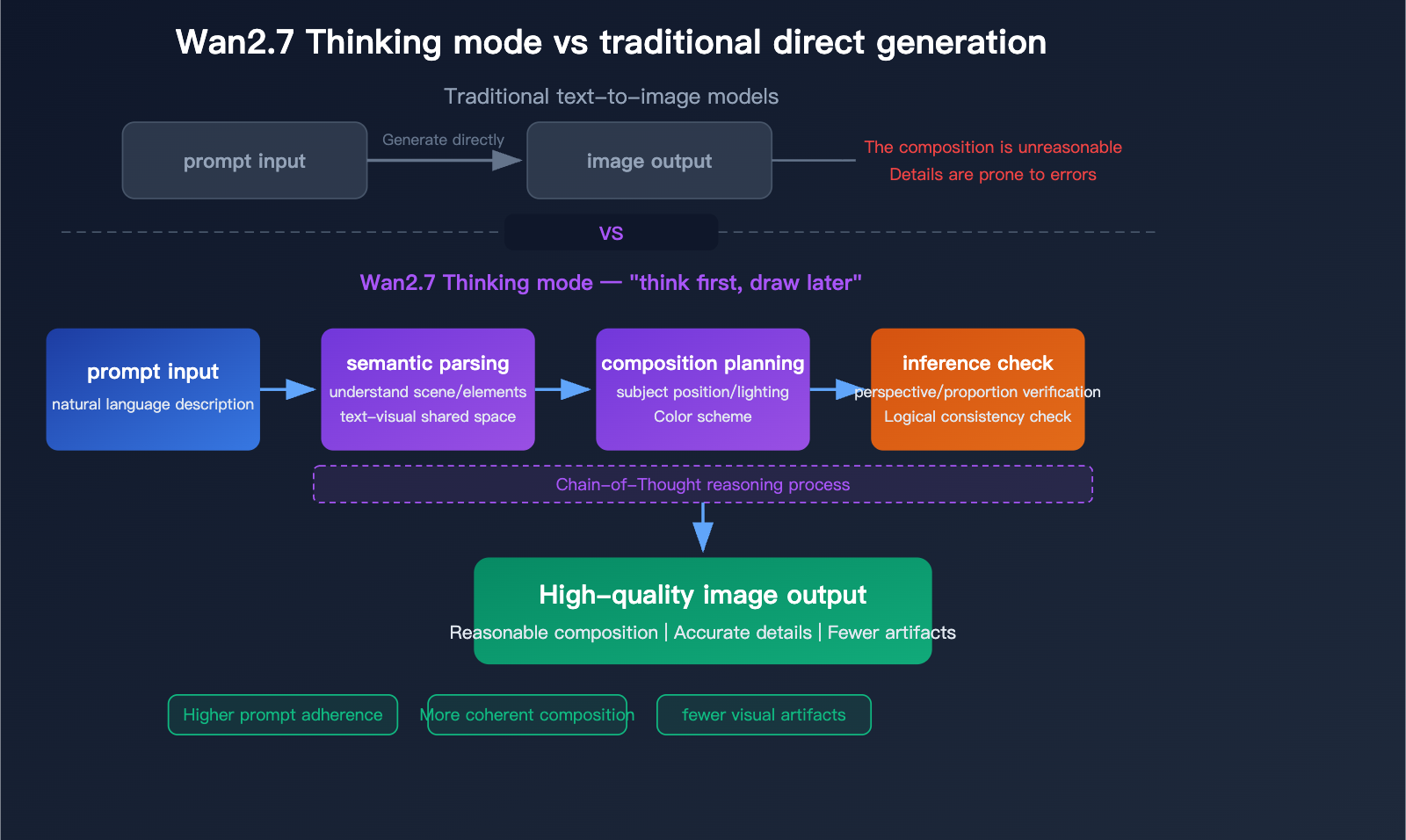
การวิเคราะห์เชิงลึกของ Wan2.7-Image-Pro: มาตรฐานใหม่ในการสร้างภาพด้วย AI ความละเอียด 4K โหมดให้เหตุผล และการเรนเดอร์ข้อความ 12 ภาษา - บล็อก Apiyi.com
แผนภาพโฟลว์ของโหมดคิด (Pro) แสดงการวิเคราะห์เชิงความหมาย → วางแผนองค์ประกอบ → ตรวจสอบก่อนอนุมาน ส่งผลให้สิ่งเพี้ยนลดลงและยึดตามพรอมต์มากขึ้นเมื่อเทียบกับการสร้างตรง
การฝึกบนชุดข้อมูลที่หลากหลายช่วยให้เข้าใจเจตนา แสง และเลย์เอาต์ได้ลึกซึ้ง การเรียนรู้บริบทยาว (อ้างอิงงานบน arXiv) ช่วยรองรับการจัดการข้อความยาว
Wan2.7-Image vs Wan2.7-Image-Pro: ความแตกต่างหลัก
ทั้งสองรุ่นเปิดตัวพร้อมกัน แต่รุ่น Pro มุ่งงานมืออาชีพ
| ฟีเจอร์ | Wan2.7-Image (มาตรฐาน) | Wan2.7-Image-Pro | เหมาะสำหรับ |
|---|---|---|---|
| ความละเอียดสูงสุด | 2048×2048 | 4096×4096 (4K) | งานพิมพ์/โปรดักชัน (Pro) |
| โหมดคิด | มีให้ใช้ (ดีฟอลต์เร็วกว่า) | ยกระดับ/ดีฟอลต์ด้วยเหตุผลลึกกว่า | ฉากซับซ้อน (Pro) |
| เสถียรภาพองค์ประกอบ | แข็งแกร่ง | ความเข้าใจเชิงความหมายเหนือกว่า | โครงการเชิงพาณิชย์ (Pro) |
| ความเร็วเทียบคุณภาพ | ทดสอบไอเดียได้เร็ว | ความคมชัดสูง ใช้เวลานานขึ้นเล็กน้อย | ต้นแบบเร็ว (มาตรฐาน) |
| การใช้งาน | ครีเอเตอร์ทั่วไป คอนเทนต์โซเชียล | ดีไซน์องค์กร งานวิชาการ/สิ่งพิมพ์ | ปริมาณ vs ความแม่นยำ |
รุ่นมาตรฐานเหมาะกับการทำต้นแบบรวดเร็ว; รุ่น Pro ให้เอาต์พุต 4K พร้อมความสม่ำเสมอเหนือกว่า เหมาะกับงานพิมพ์
วิธีใช้ Wan2.7-Image (ทีละขั้น)
1. เข้าใช้งานแพลตฟอร์ม
มีให้ใช้ผ่าน:
- Alibaba Cloud (แพลตฟอร์ม BaiLian)
- เครื่องมือทางการ Wanxiang
- CometAPI
2. เลือกโหมดเวิร์กโฟลว์
โหมด A: สร้างภาพจากข้อความ
ตัวอย่างพรอมต์:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
โหมด B: แก้ไขภาพ
- อัปโหลดภาพ
- เลือกพื้นที่
- ป้อนคำสั่ง
ตัวอย่าง:
Replace background with a futuristic city
โหมด C: การประกอบภาพหลายภาพ
- อัปโหลดภาพอ้างอิงหลายภาพ
- กำหนดกฎการจัดองค์ประกอบ
3. ปรับแต่งพารามิเตอร์
- พาเลตต์สี
- ความสม่ำเสมอของสไตล์
- การเรนเดอร์ข้อความ
4. ส่งออกผลลัพธ์
- ภาพความละเอียดสูง
- แอสเซ็ตพร้อมใช้งานเชิงพาณิชย์
ประสิทธิภาพ Benchmarks และการเทียบคู่แข่ง
จากการทดสอบความชอบของมนุษย์แบบปิด Wan2.7-Image เหนือกว่า GPT-Image-1.5 ในคุณภาพ text-to-image และทัดเทียมหรือดีกว่า Nano Banana Pro ในการเรนเดอร์ข้อความ ความเสมือนจริง และความรู้เกี่ยวกับโลก
ตารางเปรียบเทียบ:
| รุ่น | การเรนเดอร์ข้อความ | การทำตามคำสั่ง | ปรับแต่งอวาตาร์ | อ้างอิงหลายภาพ | สร้าง/แก้ไขแบบรวม | ความละเอียด | โอเพนซอร์ส/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | เยี่ยมมาก (12 ภาษา) | เหนือกว่า (โหมดคิด) | ระดับโครงหน้า | 9 | ใช่ | 2K–4K | ใช่/API |
| Midjourney V8 | ดี | ปานกลาง | เชิงศิลป์โดดเด่น | จำกัด | ไม่ | สูง | เฉพาะ Discord |
| FLUX | ดี | แข็งแกร่ง (กรณีง่าย) | ดี | จำกัด | ไม่ | สูง | ใช่ |
| DALL-E 3 | ปานกลาง | ดี | ปานกลาง | ไม่มี | ไม่ | 2K | API |
| Nano Banana Pro | แข็งแกร่ง | การแก้ไขแข็งแกร่ง | ดี | แข็งแกร่ง | บางส่วน | สูง | ปิด |
Wan2.7-Image นำในเวิร์กโฟลว์แบบรวม การรองรับข้อความหลายภาษา และการควบคุมแม่นยำ—มีคุณค่าสำหรับตลาดที่ไม่ใช่อังกฤษและสายงานมืออาชีพ
CometAPI เป็นแพลตฟอร์มรวม API โมเดลขนาดใหญ่แบบครบวงจร ช่วยผสานและจัดการบริการ API ได้อย่างไร้รอยต่อ รองรับ API สร้างภาพหลายค่าย เช่น GPT-image-1.5, Nano Banana series, Midjourney และ Qwen Image Series เป็นต้น โดยมีราคาถูกกว่าทางการ
ใครควรใช้ Wan2.7-Image
Wan2.7-Image เหมาะอย่างยิ่งกับทีมที่ต้องการความเร็วและความยืดหยุ่น มากกว่าการสร้างชิ้นงานแบบครั้งเดียวจบ ได้แก่ นักการตลาดสาย performance นักออกแบบผลิตภัณฑ์ สตูดิโออีคอมเมิร์ซ ทีมคอนเทนต์โซเชียล และเอเจนซี่ที่ต้องผลิตหลายเวอร์ชันจากบรีฟเดียว การรองรับอินพุตหลายภาพ สร้างผลลัพธ์หลายภาพ และการแก้ไขตามคำสั่ง ทำให้โดดเด่นในเวิร์กโฟลว์ที่ต้องการความสม่ำเสมอ ความเร็ว และการควบคุมพรอมต์
กรณีใช้งานจริง
- เกม/บันเทิง: สร้าง NPC ไม่ซ้ำ 100 ตัวภายในไม่กี่นาที
- การตลาด/อีคอมเมิร์ซ: คารูเซลที่ยึดสีแบรนด์เป๊ะตามพาเลตต์
- การศึกษา/วงวิชาการ: โปสเตอร์พร้อมพิมพ์ พร้อมสูตรและตาราง
- เอเจนซี่ออกแบบ: สตอรีบอร์ดและงานรีวิชันลูกค้าผ่านการแก้ไขเชิงโต้ตอบ
ประสิทธิภาพเพิ่มขึ้นจากรอบแก้ไขที่น้อยลงและการผสานอ้างอิงที่ไหลลื่น
บทสรุป:
Alibaba Wan2.7-Image กำหนดนิยามใหม่ให้กับความคิดสร้างสรรค์ด้วย AI โดยรวมการสร้าง การแก้ไข และการทำความเข้าใจไว้ด้วยกัน 5 ฟีเจอร์หลัก latent space ร่วม และการยกระดับในรุ่น Pro ส่งมอบผลลัพธ์ระดับมืออาชีพที่คู่แข่งยังตามไม่ทัน ไม่ว่าจะทำต้นแบบคอนเทนต์โซเชียล หรือผลิตงานภาพวิชาการพร้อมพิมพ์ ก็ให้ความแม่นยำและประสิทธิภาพที่เหนือกว่า
เริ่มต้นได้วันนี้ที่ wan.video หรือผ่าน API ใน CometAPI สำหรับนักพัฒนาและองค์กร การผสานพลัง ความเข้าถึงง่าย และหลักฐานเชิงข้อมูล ทำให้ Wan2.7-Image เป็นผู้นำที่ชัดเจนในบรรดาโมเดลภาพ AI แบบรวมสำหรับปี 2026 และต่อไป