
.png&w=3840&q=75)
GPT-5.4 Mini และ GPT-5.4 Nano คือรุ่นขนาดกะทัดรัดใหม่ของ OpenAI ในตระกูล GPT-5.4 ระดับ frontier: Mini มุ่งเน้นสมดุลที่ดีที่สุดในระดับเดียวกันระหว่างประสิทธิภาพและความหน่วงสำหรับงานเขียนโค้ด งาน UI แบบมัลติโหมด และเวิร์กโหลดซับเอเจนต์; Nano มุ่งเน้นต้นทุนและความหน่วงที่ต่ำมากสำหรับงานจัดประเภท การดึงข้อมูล การจัดอันดับ และซับเอเจนต์แบบขนานจำนวนมาก Mini ให้ความแม่นยำใกล้เคียงระดับ frontier บนเบนช์มาร์กสำหรับนักพัฒนาหลายรายการ ขณะทำงานได้เร็วกว่า mini รุ่นก่อนหน้ามากกว่า 2×; Nano มีราคาต่อโทเคนถูกลงอย่างมาก และเหมาะอย่างยิ่งเมื่อปริมาณงานและการตอบสนองเป็นปัจจัยสำคัญที่สุด โมเดลเหล่านี้เปิดให้ใช้งานแล้วผ่าน API (GPT 5.4 Mini และ Nano พร้อมใช้งานบน CometAPI).
GPT-5.4 Mini และ GPT-5.4 Nano คืออะไร?
คำจำกัดความสั้น ๆ: GPT-5.4 Mini และ GPT-5.4 Nano คือรุ่นย่อยที่ออกแบบทางวิศวกรรมให้มีขนาดกะทัดรัดของตระกูล GPT-5.4 ซึ่งถูกสร้างมาเพื่อนำจุดแข็งหลักของ GPT-5.4 รุ่นใหญ่ (การให้เหตุผล การเขียนโค้ด การรับรู้แบบมัลติโหมด การใช้เครื่องมือ) มาอยู่ในโมเดลที่เร็วขึ้นและต้นทุนต่ำลง โดยมุ่งเป้าไปที่เวิร์กโหลดปริมาณสูงและความหน่วงต่ำ โมเดลเหล่านี้ถูกประกาศโดย OpenAI ในฐานะส่วนหนึ่งของการเปิดตัว GPT-5.4
- GPT-5.4 Mini — โมเดลขนาดเล็กที่มีประสิทธิภาพสูง ซึ่ง “เข้าใกล้ประสิทธิภาพของ GPT-5.4 ในการประเมินหลายรายการ” ขณะเดียวกันก็ได้รับการปรับให้เหมาะกับความเร็วและต้นทุนที่ต่ำลง โดยถูกเน้นเป็นพิเศษสำหรับการเขียนโค้ด การให้เหตุผล การตีความ UI แบบมัลติโหมด (ภาพหน้าจอ) และการทำหน้าที่เป็นซับเอเจนต์ในระบบเอเจนต์ OpenAI รายงานว่ามันทำงานได้เร็วกว่า “mini” รุ่นก่อนหน้ามากกว่า 2×
- GPT-5.4 Nano — รุ่น GPT-5.4 ที่เล็กและถูกที่สุด; แนะนำสำหรับงานจัดประเภท การดึงข้อมูล การจัดอันดับ และซับเอเจนต์ “สนับสนุน” ที่จัดการงานแคบ ๆ ซ้ำ ๆ ด้วยปริมาณงานสูงมาก โดยแลกความสามารถด้านการให้เหตุผลเชิงลึกกับการประหยัดด้านความหน่วงและต้นทุน
การใช้งานและราคา
OpenAI ให้ข้อมูลตัวเลขที่ชัดเจนสองจุดซึ่งคุณสามารถใช้เปรียบเทียบต้นทุนได้:
- ราคา API input ของ GPT-5.4 (เรือธงเต็มรูปแบบ): $2.50 / 1M tokens (และมีราคาสำหรับ output ที่สูงกว่าสำหรับรุ่นเรือธง)
- ราคา API input ของ GPT-5.4 mini: $0.75 / 1M tokens และ output $4.50 / 1M tokens
- ราคา API input ของ GPT-5.4 nano: $0.20 / 1M และ output $1.25 / 1M
เมื่อนำมาเทียบกันแบบข้างกัน: ราคาต่อ input token ของ mini (0.75) คิดเป็น 30% ของรุ่นเรือธง (2.50) หรือประมาณ หนึ่งในสาม ของต้นทุนฝั่ง input; ราคาฝั่ง output ของ mini (4.50) อยู่ที่ประมาณ 32% ของราคารุ่นเรือธงฝั่ง output ที่อ้างในตารางราคา API หรือประมาณหนึ่งในสามเช่นกัน Nano ถูกยิ่งกว่าอีก: ต้นทุนฝั่ง input อยู่ที่ประมาณ 8% ของต้นทุน input ของรุ่นเรือธง และต้นทุนฝั่ง output ต่ำกว่า 10% ของต้นทุน output ของรุ่นเรือธง สัดส่วนเหล่านี้เองที่ทำให้ OpenAI อธิบาย mini/nano ว่ามีต้นทุน “ประมาณหนึ่งในสาม” (mini) และ “เป็นเพียงเศษส่วนหนึ่งของ” (nano) เมื่อเทียบกับการใช้โมเดลที่ใหญ่ที่สุดสำหรับงานปริมาณสูง ราคาโทเคนของ nano เพิ่มจาก $0.05 เป็น $0.20 และราคาโทเคนของ mini เพิ่มจาก $0.25 เป็น $0.75 (สำหรับ input tokens)
บนแพลตฟอร์ม OpenAI
GPT-5.4 mini พร้อมใช้งานในสามที่: OpenAI API, Codex (IDE/แพลตฟอร์มแอปสำหรับนักพัฒนาของ OpenAI) และ ChatGPT (พร้อมให้ผู้ใช้ Free และ Go ใช้งานผ่านตัวเลือก “Thinking” และเป็นตัวสำรองเมื่อถึง rate limit สำหรับแพ็กเกจแบบชำระเงิน) ใน API มันรองรับอินพุตแบบข้อความและรูปภาพ การใช้เครื่องมือ (function calling) การค้นหาเว็บ/ไฟล์ การใช้งานคอมพิวเตอร์ และ skills — อีกทั้งยังมีหน้าต่างบริบทขนาดใหญ่มาก (400k tokens) เพื่อรองรับเวิร์กโฟลว์ที่ใช้เอกสารจำนวนมากและภาพหน้าจอหลายภาพ ราคา API คือ $0.75 ต่อ 1M input tokens และ $4.50 ต่อ 1M output tokens
GPT-5.4 nano ใช้งานได้ผ่าน API เท่านั้น ราคาประกาศคือ $0.20 ต่อ 1M input tokens และ $1.25 ต่อ 1M output tokens — วางตำแหน่งให้เป็นตัวเลือกต้นทุนต่ำที่สุดในตระกูล GPT-5.4 โมเดล nano ตั้งใจแลกความสามารถบางส่วนกับต้นทุนและความเร็ว
บนแพลตฟอร์มภายนอก
CometAPI เป็นแพลตฟอร์มรวม API AI แบบมัลติโหมดที่ได้เปิดตัว GPT 5.4 Series API แล้ว ซึ่งรวมถึง GPT 5.4 Mini และ GPT 5.4 Nano โดยมีราคาถูกกว่าราคา OpenAI 20%
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.16/M; Output:$1/M | Input:$0.2/M; Output:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| Input:$0.6/M; Output:$3.6/M | Input:$0.75/M; Output:$4.5/M |
คุณสมบัติหลักและสิ่งใหม่
ด้านล่างนี้คือความสามารถเด่น ๆ — เหตุผลที่วิศวกรและทีมผลิตภัณฑ์ควรให้ความสนใจ
การเข้ารหัสและการรองรับบริบทยาว
หน้าต่างบริบท: GPT-5.4 mini รองรับหน้าต่างบริบทขนาด 400k token (OpenAI ระบุอย่างชัดเจนว่า mini มีบริบท 400k) ซึ่งมากพอสำหรับโค้ดเบสหลายไฟล์ เอกสารยาว หรือเซสชันเอเจนต์หลายรอบที่บริบทมีความสำคัญ บริบทของ Nano มีขนาดเล็กกว่ารุ่น GPT-5.4 เต็มรูปแบบ แต่ก็ยังมากพอสำหรับงานสั้น ๆ ที่ต้องการความเร็ว
การให้เหตุผล
ระดับการให้เหตุผล: OpenAI เปิดให้ตั้งค่า reasoning_effort ได้ (none → xhigh); mini และ nano สามารถทำงานด้วยระดับ effort ที่หลากหลาย แต่ mini ลดช่องว่างเมื่อเทียบกับ GPT-5.4 เต็มรูปแบบได้มากบนเบนช์มาร์กด้านการให้เหตุผลหลายรายการเมื่อใช้ effort สูง ในเบนช์มาร์กด้านสติปัญญาหลายรายการ (เช่น GPQA Diamond) mini ทำคะแนนได้ 88.0% เทียบกับ 93.0% ของ GPT-5.4 และ nano ทำได้ 82.8% ซึ่งสะท้อนถึงความสามารถด้านการให้เหตุผลที่น่านับถือสำหรับโมเดลขนาดเล็ก ตัวเลขเหล่านี้มาจากที่ OpenAI เผยแพร่ในโพสต์เปิดตัว
ความเข้าใจแบบมัลติโหมด (ภาพและ UI)
การรับรู้ภาพและงาน UI: GPT-5.4 mini แสดงประสิทธิภาพแบบมัลติโหมดที่แข็งแกร่งมากสำหรับงาน UI (ภาพหน้าจอ ภาพเอกสารหนาแน่น) บน OSWorld-Verified (เบนช์มาร์กด้านการใช้งานคอมพิวเตอร์) mini ทำคะแนนได้ 72.1% ซึ่งใกล้กับ 75.0% ของ GPT-5.4 มาก และสูงกว่า mini รุ่นก่อนหน้าอย่างชัดเจน นี่คือเหตุผลที่ mini ถูกวางตำแหน่งสำหรับงานอัตโนมัติที่ขับเคลื่อนด้วยภาพหน้าจอและผู้ช่วยมัลติโหมดที่ตอบสนองรวดเร็ว Nano มีผลลัพธ์บนเบนช์มาร์กด้านภาพต่ำกว่า แต่ยังมีประโยชน์สำหรับงานภาพที่ง่ายกว่า
การเรียกใช้เครื่องมือและการใช้งานคอมพิวเตอร์
ความสามารถด้านเครื่องมือ/การคลิกแบบเนทีฟ: GPT-5.4 นำเสนอและต่อยอดเครื่องมือการใช้งานคอมพิวเตอร์แบบเนทีฟ; mini สืบทอดความสามารถในการเรียกใช้เครื่องมือ ทำ function call ตีความภาพหน้าจอ และประสานงานซับเอเจนต์ เบนช์มาร์กด้านการเรียกใช้เครื่องมือ (Toolathlon, MCP Atlas) แสดงให้เห็นว่า mini และ nano ทำคะแนนได้ดีพอสมควร (Toolathlon: mini 42.9%, nano 35.5%) — ซึ่งเป็นการวัดความสามารถในการเรียกและประสานงานเครื่องมือภายนอก ตัวชี้วัดเหล่านี้มาจากประกาศของ OpenAI
อาการหลอน / ความถูกต้องตามข้อเท็จจริง / อัตราความผิดพลาด
OpenAI รายงานว่า GPT-5.4 เป็น “โมเดลที่ยึดข้อเท็จจริงมากที่สุดเท่าที่เคยมีมา” และแสดงให้เห็นว่ามีอาการหลอนลดลงเมื่อเทียบกับ GPT-5.2; mini และ nano มีความถูกต้องตามข้อเท็จจริงโดยรวมต่ำกว่ารุ่นเต็ม (เช่น HLE w/ tools: GPT-5.4 52.1%, mini 41.5%, nano 37.7%) ซึ่งบ่งชี้ว่าจำเป็นต้องมีการตรวจสอบเพิ่มขึ้นเมื่อใช้โมเดลขนาดเล็กกับงานที่ต้องการความถูกต้องสูง ใช้การตรวจสอบผ่านเครื่องมือ (tool calls, citation recall) เมื่อต้องการความถูกต้องเป็นสำคัญ
ความเร็ว
OpenAI รายงานว่า GPT-5.4 mini ทำงานได้ เร็วกว่า GPT-5 mini รุ่นก่อนหน้ามากกว่า 2× บนการประเมินความหน่วงแบบลักษณะการใช้งานจริงทั่วไป (อิงจากพฤติกรรมการใช้งานจริงแบบจำลองที่รวมระยะเวลาการเรียกเครื่องมือและโทเคนที่สุ่มตัวอย่างแล้ว) การเพิ่มความเร็วนี้เป็นข้ออ้างหลักสำคัญของตระกูลใหม่นี้ และเป็นสิ่งที่ทำให้ mini สามารถถูกใช้เป็นซับเอเจนต์ที่ตอบสนองไวภายในแอปเชิงโต้ตอบ เช่น ผู้ช่วยเขียนโค้ด
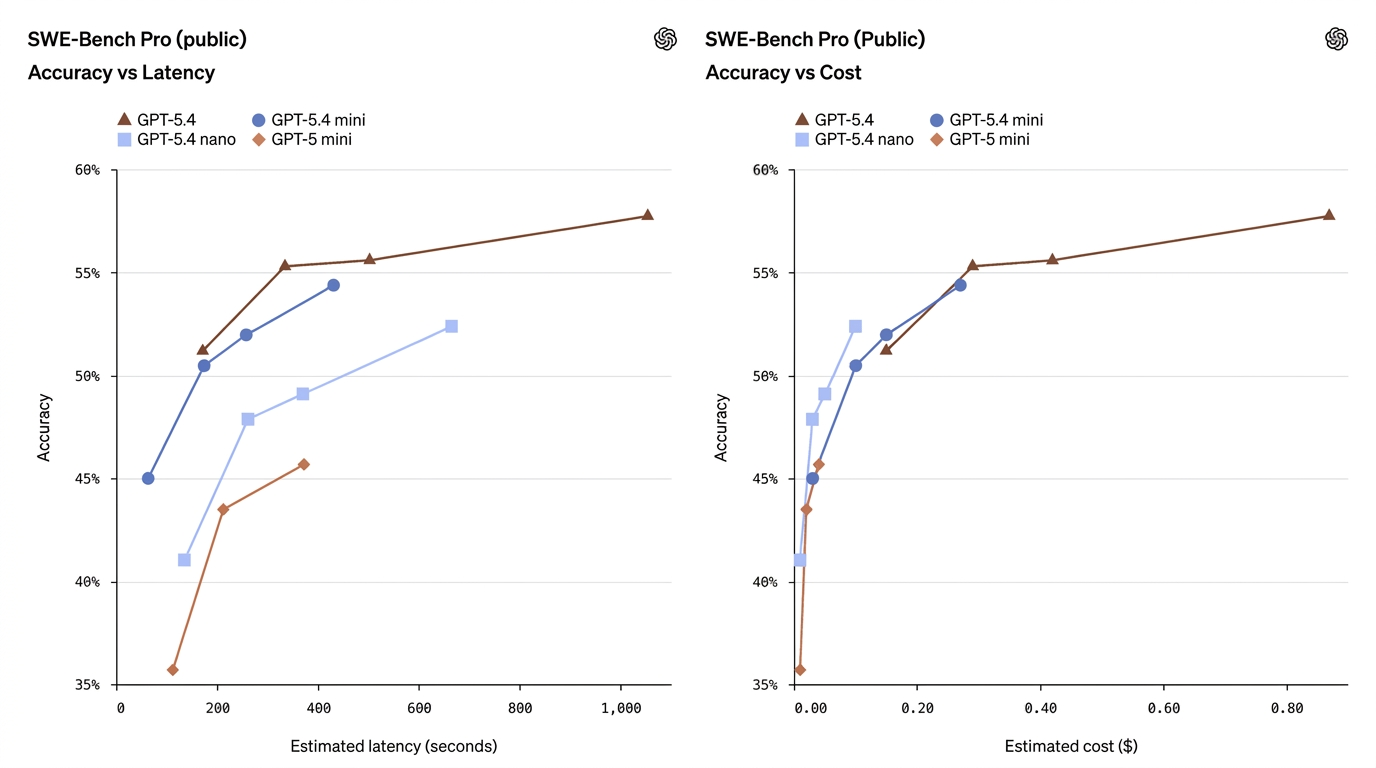
mini และ nano มีประสิทธิภาพอย่างไร — พวกมัน “เข้าใกล้” GPT-5.4 เต็มรูปแบบหรือไม่?
OpenAI เผยแพร่ชุดการเปรียบเทียบเบนช์มาร์กที่ครอบคลุมในด้านการเขียนโค้ด การใช้เครื่องมือ งานคอมพิวเตอร์แบบมัลติโหมด การทดสอบสติปัญญา และการประเมินบริบทยาว ตัวเลขสำคัญ (reasoning effort ระดับ xhigh เมื่อเกี่ยวข้อง) มีดังนี้:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | Notes |
|---|---|---|---|---|---|
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini approaches full model coding performance |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Strong real-time coding ability for Mini |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | Measures orchestration & tool-calling |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | Intelligence & reasoning benchmark |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | UI/computer-use capability |
ตัวเลขเหล่านี้แสดงให้เห็นว่า mini มักจะลดช่องว่างลงได้มาก — โดยเฉพาะอย่างยิ่งในงานเขียนโค้ดและงานใช้งานคอมพิวเตอร์ — ในขณะที่ nano อยู่ตรงจุดสมดุลที่มีประโยชน์ระหว่างความสามารถและต้นทุน
ตัวเลขเหล่านี้หมายความว่าอะไรในภาษาง่าย ๆ?
- GPT-5.4 Mini ≈ “เกือบระดับเรือธง” ในหลายงานการใช้งานจริง บน SWE-Bench Pro (ตัวชี้วัดอัตราผ่านด้านการเขียนโค้ด) mini ทำได้ 54.4% เทียบกับ 57.7% ของรุ่นเรือธง — เป็นช่องว่างเชิงสัมพัทธ์ที่เล็กสำหรับงานเขียนโค้ดจริงจำนวนมาก โดยเฉพาะเมื่อความหน่วงมีความสำคัญ บน OSWorld (การใช้งานคอมพิวเตอร์) mini ได้ 72.1% เทียบกับ 75.0% ของรุ่นเรือธง — ใกล้เคียงกันมากอีกครั้งสำหรับงาน UI/ภาพหน้าจอ
- GPT-5.4 Nano แลกความสามารถมากขึ้นเพื่อความเร็ว/ต้นทุน คะแนนด้านการเขียนโค้ดของ Nano (52.4% บน SWE-Bench Pro) ถือว่าน่านับถือเมื่อเทียบกับ mini รุ่นเก่า แต่คะแนน OSWorld ลดลงเหลือ 39.0% แสดงให้เห็นว่าสำหรับงานที่ต้องการความเข้าใจ UI แบบหลายขั้นตอนที่ซับซ้อน หรือการใช้เครื่องมือแบบเอเจนต์ Nano เหมาะน้อยกว่า Nano โดดเด่นในงานจัดประเภทแบบรอบเดียว การดึงข้อมูล และงานผู้ช่วยขนาดเล็ก
- การใช้เครื่องมือดีขึ้น แต่ยังคงอ่อนไหว Toolathlon และเมตริกด้านการใช้เครื่องมืออื่น ๆ เพิ่มขึ้นอย่างชัดเจนเมื่อเปลี่ยนจาก GPT-5 mini ไปเป็น GPT-5.4 mini/nano แสดงให้เห็นว่าวิศวกรรมของ OpenAI ปรับปรุงความน่าเชื่อถือในการเรียกใช้เครื่องมือในโมเดลขนาดเล็กได้ดีขึ้น — แต่รุ่นเต็มยังคงนำในด้านการประสานงานเครื่องมือที่ซับซ้อน
พวกมันทำงานอย่างไรในการใช้งานจริง
การบีบอัด การกลั่นความรู้ และการเพิ่มประสิทธิภาพทางวิศวกรรม
โมเดลขนาดกะทัดรัดอย่าง mini/nano โดยทั่วไปมักใช้การผสมผสานของ model distillation, quantization และ architectural pruning เพื่อคงความสามารถที่มีมูลค่าสูงไว้ (ฮิวริสติกด้านการเขียนโค้ด การรับรู้ภาพ) ขณะลดต้นทุนการประมวลผลในการอนุมาน ถ้อยคำของ OpenAI บ่งชี้ถึงการออกแบบทางวิศวกรรมที่มุ่งรักษาชุดทักษะเฉพาะ (การเขียนโค้ด ความเข้าใจ UI แบบมัลติโหมด) เอาไว้ในโมเดลขนาดเล็กลง
รูปแบบที่แนะนำ
- รูปแบบ orchestrator + subagent: ใช้ GPT-5.4 (รุ่นใหญ่) เป็นตัววางแผน/ผู้ตัดสิน และกระจายงานไปยังซับเอเจนต์ GPT-5.4 mini / nano เพื่อดำเนินการอย่างรวดเร็ว (ค้นหา แยกวิเคราะห์ แก้ไข) วิธีนี้ช่วยลดต้นทุนรวมและลดความหน่วงสำหรับผู้ใช้ OpenAI สนับสนุนรูปแบบการออกแบบนี้อย่างชัดเจน
- Fallback และการจัดการ rate limit: เปิดให้ mini เป็นตัวสำรองเมื่อถึง rate limit ใน ChatGPT หรือ Codex เพื่อให้คำถามที่ไวต่อเวลายังคงได้รับคำตอบที่มีความสามารถเมื่อโมเดลเต็มไม่พร้อมใช้งาน
- สถาปัตยกรรมแบบแบ่งชั้นเพื่อควบคุมต้นทุน: ไปป์ไลน์แบบจำนวนมาก (การทำดัชนี การดึงข้อมูล) → GPT-5.4 nano; องค์ประกอบ UI แบบโต้ตอบ → GPT-5.4 mini; การตัดสินเชิงบรรณาธิการขั้นสุดท้าย / เชนที่ซับซ้อน → GPT-5.4 full วิธีหลายชั้นนี้ช่วยสร้างสมดุลระหว่างต้นทุนและความสามารถ
ความหน่วงและการประมวลผลแบบขนาน
Mini และ nano ได้รับการปรับให้เหมาะกับ ซับเอเจนต์แบบขนาน ซึ่งเป็นสถานการณ์ที่มีตัวทำงานขนาดเล็กจำนวนมากทำงานพร้อมกัน — เช่น การสแกน PDF หลายพันไฟล์พร้อมกัน แนวคิด “tool yields” ของ OpenAI วัดว่าการเรียกใช้เครื่องมือแบบขนานช่วยลด wall-clock latency ได้อย่างไร; mini/nano ถูกออกแบบมาเพื่อทำให้รูปแบบเหล่านี้คุ้มค่าด้านต้นทุน
ในทางปฏิบัติฉันจะใช้ mini และ nano อย่างไร
ฉันควรแทนที่การเรียกใช้รุ่นเรือธงทั้งหมดด้วย mini/nano หรือไม่?
ไม่ใช่อัตโนมัติ รูปแบบที่ถูกต้องที่ OpenAI แนะนำอย่างชัดเจนคือ delegation: ใช้โมเดลที่ใหญ่กว่าสำหรับการวางแผน การตัดสินที่ซับซ้อน หรือการตรวจสอบขั้นสุดท้าย และมอบหมายงานย่อยที่สนับสนุนจำนวนมากซึ่งสั้นกว่าไปยังซับเอเจนต์ mini หรือ nano รูปแบบนี้ช่วยลดต้นทุนและความหน่วง ในขณะที่ยังคงรักษา guardrails ของโมเดลใหญ่ไว้ในจุดที่สำคัญที่สุด ตัวอย่างการใช้งาน:
- ผู้ช่วยเขียนโค้ดแบบโต้ตอบ: รุ่นเรือธงวางแผนและรีวิว; mini จัดการการค้นหาโค้ดอย่างรวดเร็ว การแก้ไข และยูนิตเทสต์สั้น ๆ
- เอเจนต์ “computer use” ที่ขับเคลื่อนด้วยภาพหน้าจอ: mini สามารถแยกวิเคราะห์อินเทอร์เฟซที่ซับซ้อนได้อย่างรวดเร็ว; รุ่นเรือธงใช้แก้ปัญหาการวางแผนหลายขั้นตอนที่คลุมเครือ
- ไปป์ไลน์การดึงข้อมูลและการจัดประเภทปริมาณสูง: nano ประมวลผลอินพุตแบบแบตช์จำนวนมหาศาล (ฟอร์ม ล็อก) และส่งคืนผลลัพธ์แบบมีโครงสร้าง; รุ่นเรือธงจัดการข้อยกเว้นและกรณีขอบที่ซับซ้อน
mini หรือ nano ใช้กับงานมัลติโหมดหรือรูปภาพได้หรือไม่?
ได้ — mini รองรับอินพุตรูปภาพและทำผลงานได้ดีบนเบนช์มาร์กที่ขับเคลื่อนด้วยมัลติโหมด/ภาพ (MMMUPro/OmniDocBench) โดยเข้าใกล้รุ่นเรือธงในบางการทดสอบ ความแข็งแกร่งด้านมัลติโหมดของ Nano มีข้อจำกัดมากกว่า: แม้ว่าจะดีขึ้นจาก nano รุ่นก่อน แต่ก็ไม่ใช่ตัวเลือกที่ดีที่สุดสำหรับการให้เหตุผลเชิงมัลติโหมดเชิงลึกหรืองานเอเจนต์ที่อิงภาพ
การแข่งขันด้านความสามารถของโมเดลขนาดเล็กกำลังเข้มข้นขึ้น
เมื่อสามเดือนก่อน โมเดลขนาดเล็กถูกมองว่า “ดีพอใช้” ตอนนี้ GPT-5.4 mini กำลังเข้าใกล้โมเดลเรือธงบนเบนช์มาร์กด้านการเขียนโปรแกรม และเกือบตามทันในประสิทธิภาพเชิงคำนวณ
แนวโน้มเบื้องหลังเรื่องนี้ชัดเจน: ความสามารถของโมเดลเรือธงกำลังถูกถ่ายทอดไปยังโมเดลขนาดเล็กอย่างรวดเร็ว OpenAI, Google และ Anthropic ต่างก็ทำสิ่งเดียวกัน: กลั่นความสามารถหลักของโมเดลขนาดใหญ่ให้กลายเป็นเวอร์ชันที่เล็กกว่า เร็วกว่า และถูกกว่า
บทสรุป
การเปิดตัวของสองโมเดลนี้สะท้อนให้เห็นถึงการเปลี่ยนผ่านของแอปพลิเคชัน AI จากการมุ่งเน้นที่ขนาด ไปสู่การมุ่งเน้นที่ประสิทธิภาพเชิงปฏิบัติ ผ่านความสามารถในการตอบสนองอย่างรวดเร็ว พวกมันมอบโครงสร้างพื้นฐานที่เชื่อถือได้มากขึ้นสำหรับการโต้ตอบกับ AI แบบเรียลไทม์และการแตกงานที่ซับซ้อนออกเป็นลำดับขั้น
สำหรับนักพัฒนา นี่หมายความว่าโครงสร้างต้นทุนของระบบเอเจนต์กำลังถูกนิยามใหม่ เมื่อต้นทุนลดลงมาถึงระดับนี้ สถานการณ์เอเจนต์จำนวนมากที่ก่อนหน้านี้ “เป็นไปได้ในทางทฤษฎีแต่ไม่คุ้มค่าในทางเศรษฐกิจ” ก็เริ่มใช้งานได้จริง
นักพัฒนาสามารถเข้าถึง GPT 5.4 Mini และ GPT-5.4 Nano ผ่าน CometAPI ได้แล้วตอนนี้ ก่อนเข้าใช้งาน โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับ API key แล้ว CometAPI เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยให้คุณผสานรวมได้
พร้อมใช้งานหรือยัง?