

การเริ่มต้นใช้งาน Gemini 2.5 Flash-Lite ผ่าน CometAPI ถือเป็นโอกาสอันน่าตื่นเต้นในการใช้ประโยชน์จากโมเดล AI เชิงสร้างสรรค์ที่มีประสิทธิภาพด้านต้นทุนและความล่าช้าต่ำที่สุดโมเดลหนึ่งในปัจจุบัน คู่มือนี้รวบรวมประกาศล่าสุดจาก Google DeepMind ข้อมูลจำเพาะโดยละเอียดจากเอกสารประกอบ Vertex AI และขั้นตอนการผสานรวมในทางปฏิบัติโดยใช้ CometAPI เพื่อช่วยให้คุณเริ่มต้นและใช้งานได้อย่างรวดเร็วและมีประสิทธิภาพ
Gemini 2.5 Flash-Lite คืออะไร และทำไมคุณจึงควรพิจารณา?
ภาพรวมของตระกูล Gemini 2.5
ในช่วงกลางเดือนมิถุนายน 2025 Google DeepMind ได้เปิดตัวซีรีส์ Gemini 2.5 อย่างเป็นทางการ ซึ่งรวมถึง Gemini 2.5 Pro และ Gemini 2.5 Flash เวอร์ชัน GA ที่เสถียรแล้ว ควบคู่ไปกับการเปิดตัวรุ่นใหม่ล่าสุดที่มีน้ำหนักเบา: Gemini 2.5 Flash-Lite ซีรีส์ 2.5 ได้รับการออกแบบมาเพื่อให้สมดุลระหว่างความเร็ว ต้นทุน และประสิทธิภาพ โดยแสดงให้เห็นถึงความพยายามของ Google ที่จะรองรับกรณีการใช้งานที่หลากหลาย ตั้งแต่เวิร์กโหลดการวิจัยหนักไปจนถึงการใช้งานขนาดใหญ่ที่คำนึงถึงต้นทุน
คุณสมบัติหลักของ Flash-Lite
Flash-Lite โดดเด่นด้วยความสามารถแบบมัลติโหมด (ข้อความ รูปภาพ เสียง วิดีโอ) ที่มีค่าความหน่วงต่ำมาก โดยมีหน้าต่างบริบทที่รองรับโทเค็นได้มากถึงหนึ่งล้านโทเค็นและการรวมเครื่องมือต่างๆ เช่น Google Search การรันโค้ด และการเรียกใช้ฟังก์ชัน ที่สำคัญ Flash-Lite นำเสนอการควบคุม "งบประมาณความคิด" ซึ่งช่วยให้นักพัฒนาสามารถแลกเปลี่ยนความลึกซึ้งของการใช้เหตุผลกับเวลาตอบสนองและต้นทุนได้โดยการปรับพารามิเตอร์งบประมาณโทเค็นภายใน
การวางตำแหน่งในกลุ่มผลิตภัณฑ์รุ่น
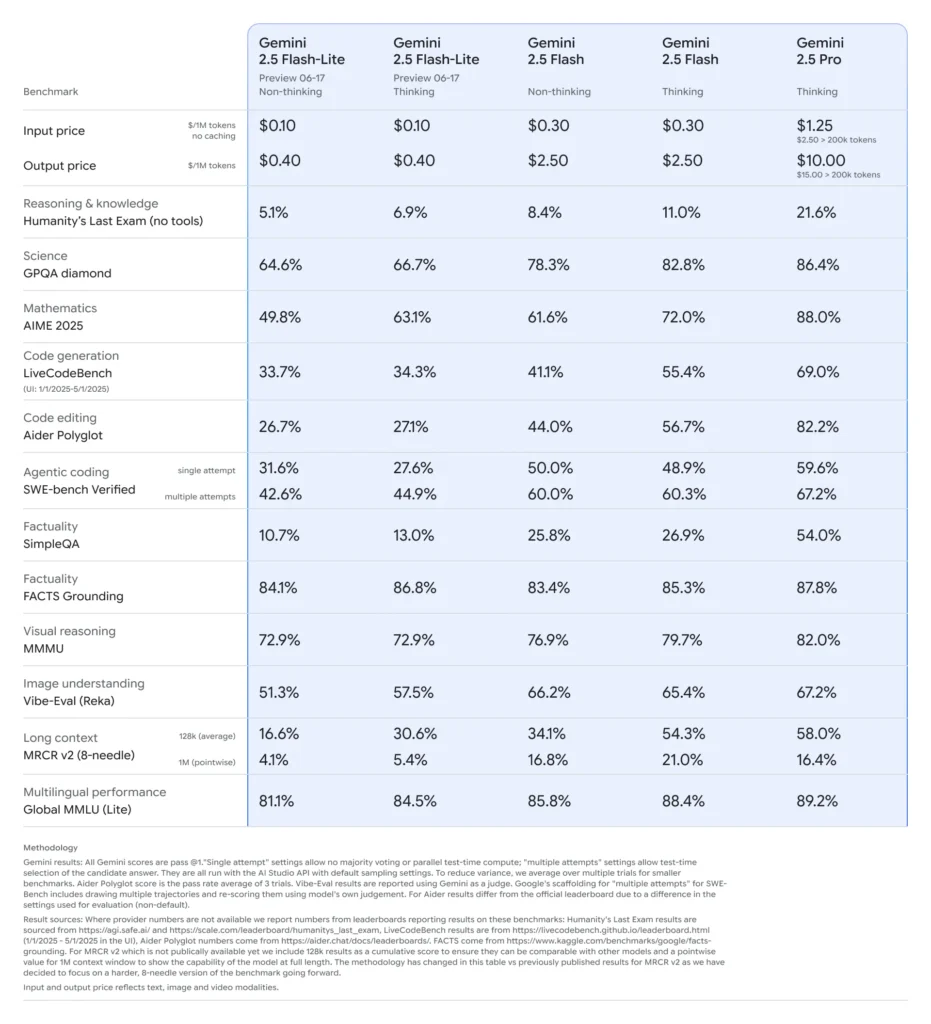
เมื่อเปรียบเทียบกับโปรแกรมอื่นๆ Flash-Lite ถือเป็นโปรแกรมที่คุ้มต้นทุนที่สุด โดยมีราคาอยู่ที่ประมาณ 0.10 ดอลลาร์ต่อโทเค็นอินพุต 0.40 ล้านโทเค็น และ 0.30 ดอลลาร์ต่อโทเค็นเอาท์พุต 2.50 ล้านโทเค็นในช่วงพรีวิว โดยโปรแกรมนี้มีราคาต่ำกว่าทั้ง Flash (ที่ 1.25 ดอลลาร์/10 ดอลลาร์) และ Pro (ที่ XNUMX ดอลลาร์/XNUMX ดอลลาร์) ขณะที่ยังคงความสามารถด้านมัลติโหมดและการรองรับการเรียกใช้ฟังก์ชันเอาไว้ได้เกือบทั้งหมด ซึ่งทำให้ Flash-Lite เหมาะอย่างยิ่งสำหรับงานที่มีปริมาณมากและมีความซับซ้อนต่ำ เช่น การสรุป การจำแนกประเภท และตัวแทนการสนทนาแบบเบา
เหตุใดนักพัฒนาจึงควรพิจารณาใช้ Gemini 2.5 Flash-Lite?
เกณฑ์มาตรฐานประสิทธิภาพและการทดสอบในโลกแห่งความเป็นจริง
ในการเปรียบเทียบแบบตัวต่อตัว Flash-Lite ได้แสดงให้เห็น:
- ส่งข้อมูลได้เร็วขึ้น 2 เท่า กว่า Gemini 2.5 Flash ในงานการจำแนกประเภท
- ประหยัดต้นทุน 3 เท่า สำหรับกระบวนการสรุปข้อมูลในระดับองค์กร
- ความแม่นยำในการแข่งขัน เกี่ยวกับเกณฑ์มาตรฐานด้านตรรกะ คณิตศาสตร์ และโค้ด ที่ตรงกันหรือดีกว่า Flash-Lite รุ่นก่อนๆ
กรณีการใช้งานที่เหมาะสม
- แชทบอทที่มีปริมาณมาก:มอบประสบการณ์การสนทนาที่สอดคล้องและมีความหน่วงต่ำให้กับผู้ใช้หลายล้านคน
- การสร้างเนื้อหาอัตโนมัติ:การสรุปเอกสารตามขนาด การแปล และการสร้างสำเนาขนาดเล็ก
- ท่อค้นหาและคำแนะนำ:ใช้ประโยชน์จากการอนุมานอย่างรวดเร็วเพื่อการปรับแต่งตามเวลาจริง
- การประมวลผลข้อมูลแบบแบตช์:ใส่คำอธิบายลงในชุดข้อมูลขนาดใหญ่ด้วยต้นทุนการประมวลผลที่น้อยที่สุด
คุณจะได้รับและจัดการการเข้าถึง API สำหรับ Gemini 2.5 Flash-Lite ผ่าน CometAPI ได้อย่างไร
เหตุใดจึงต้องใช้ CometAPI เป็นเกตเวย์ของคุณ?
CometAPI รวบรวมโมเดล AI มากกว่า 500 โมเดล รวมถึงซีรีส์ Gemini ของ Google ภายใต้จุดสิ้นสุด REST ที่เป็นหนึ่งเดียว ช่วยลดความซับซ้อนของการตรวจสอบสิทธิ์ การจำกัดอัตรา และการเรียกเก็บเงินระหว่างผู้ให้บริการต่างๆ แทนที่จะต้องจัดการ URL ฐานและคีย์ API หลายรายการ คุณส่งคำขอทั้งหมดไปที่ https://api.cometapi.com/v1ระบุโมเดลเป้าหมายในเพย์โหลด และจัดการการใช้งานผ่านแดชบอร์ดเดียว
ข้อกำหนดเบื้องต้นและการสมัคร
- เข้าสู่ระบบเพื่อ โคเมตาปิดอทคอม. หากคุณยังไม่ได้เป็นผู้ใช้ของเรา กรุณาลงทะเบียนก่อน
- รับรหัส API ของข้อมูลรับรองการเข้าถึงของอินเทอร์เฟซ คลิก "เพิ่มโทเค็น" ที่โทเค็น API ในศูนย์ส่วนบุคคล รับรหัสโทเค็น: sk-xxxxx และส่ง
- รับ url ของเว็บไซต์นี้: https://api.cometapi.com/
การจัดการโทเค็นและโควตาของคุณ
แดชบอร์ดของ CometAPI มอบโควตาโทเค็นรวมที่สามารถแชร์ได้ระหว่าง Google, OpenAI, Anthropic และโมเดลอื่นๆ ใช้เครื่องมือตรวจสอบในตัวเพื่อตั้งค่าการแจ้งเตือนการใช้งานและขีดจำกัดอัตราเพื่อให้คุณไม่เกินงบประมาณที่กำหนดไว้หรือเกิดค่าใช้จ่ายที่ไม่คาดคิด
คุณกำหนดค่าสภาพแวดล้อมการพัฒนาของคุณสำหรับการรวม CometAPI ได้อย่างไร?
การติดตั้งส่วนที่ต้องมี
สำหรับการรวม Python ให้ติดตั้งแพ็กเกจต่อไปนี้:
pip install openai requests pillow
- openai:SDK ที่เข้ากันได้สำหรับการสื่อสารกับ CometAPI
- การร้องขอ:สำหรับการดำเนินการ HTTP เช่นการดาวน์โหลดรูปภาพ
- หมอน:สำหรับการจัดการภาพเมื่อส่งอินพุตแบบหลายโหมด
การเริ่มต้นไคลเอนต์ CometAPI
ใช้ตัวแปรสภาพแวดล้อมเพื่อไม่ให้คีย์ API ของคุณเข้าไปอยู่ในโค้ดต้นฉบับ:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
ตอนนี้อินสแตนซ์ไคลเอนต์นี้สามารถกำหนดเป้าหมายไปยังโมเดลที่รองรับใดๆ ได้โดยระบุ ID ของโมเดลนั้น (เช่น gemini-2.5-flash-lite-preview-06-17) ในคำขอของคุณ
การกำหนดค่างบประมาณความคิดและพารามิเตอร์อื่น ๆ
เมื่อคุณส่งคำขอ คุณสามารถรวมพารามิเตอร์เสริมได้:
- อุณหภูมิ/หน้าบน: ควบคุมความสุ่มในการสร้าง
- จำนวนผู้สมัคร: จำนวนผลลัพธ์ทางเลือก
- max_tokens: เอาท์พุตโทเค็นแคป
- งบประมาณความคิด:พารามิเตอร์ที่กำหนดเองสำหรับ Flash-Lite เพื่อแลกเปลี่ยนความลึกกับความเร็วและต้นทุน
คำขอพื้นฐานไปยัง Gemini 2.5 Flash-Lite ผ่านทาง CometAPI มีลักษณะอย่างไร
ตัวอย่างข้อความอย่างเดียว
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
การโทรนี้จะส่งคืนข้อมูลสรุปสั้นๆ ภายในเวลาไม่ถึง 200 มิลลิวินาที เหมาะสำหรับแชทบอทหรือไปป์ไลน์การวิเคราะห์แบบเรียลไทม์
ตัวอย่างอินพุตแบบหลายโหมด
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite ประมวลผลรูปภาพได้สูงสุด 7 MB และส่งคืนคำอธิบายบริบท ทำให้เหมาะสำหรับการทำความเข้าใจเอกสาร การวิเคราะห์ UI และการรายงานอัตโนมัติ
คุณจะใช้ประโยชน์จากคุณลักษณะขั้นสูง เช่น การสตรีมและฟังก์ชันการโทรได้อย่างไร
การตอบสนองแบบสตรีมมิ่งสำหรับแอปพลิเคชันแบบเรียลไทม์
สำหรับอินเทอร์เฟซแชทบอทหรือคำบรรยายสด ให้ใช้ API สตรีมมิ่ง:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
การดำเนินการนี้จะส่งมอบผลลัพธ์บางส่วนเมื่อพร้อมใช้งาน โดยลดความล่าช้าที่รับรู้ได้ใน UI แบบโต้ตอบ
ฟังก์ชันการเรียกข้อมูลที่มีโครงสร้างเพื่อส่งออก
กำหนดรูปแบบ JSON เพื่อบังคับใช้การตอบสนองที่มีโครงสร้าง:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
แนวทางนี้รับประกันผลลัพธ์ที่สอดคล้องกับ JSON และช่วยลดความซับซ้อนของกระบวนการและการบูรณาการข้อมูลปลายทาง
คุณจะเพิ่มประสิทธิภาพ ต้นทุน และความน่าเชื่อถือได้อย่างไรเมื่อใช้ Gemini 2.5 Flash-Lite
คิดปรับงบประมาณ
พารามิเตอร์งบประมาณความคิดของ Flash-Lite ช่วยให้คุณกำหนดปริมาณ "ความพยายามทางปัญญา" ที่โมเดลใช้ งบประมาณต่ำ (เช่น 0) จะให้ความสำคัญกับความเร็วและต้นทุน ในขณะที่ค่าที่สูงกว่าจะให้เหตุผลที่ลึกซึ้งกว่าโดยแลกมากับเวลาแฝงและโทเค็น
การจัดการขีดจำกัดโทเค็นและปริมาณงาน
- โทเค็นอินพุต:สูงสุด 1,048,576 โทเค็นต่อคำขอ
- โทเค็นเอาท์พุต:ขีดจำกัดเริ่มต้นที่ 65,536 โทเค็น
- อินพุตแบบหลายโหมด:สูงสุด 500MB สำหรับไฟล์ภาพ เสียง และวิดีโอ
นำการทำงานแบบแบตช์ด้านไคลเอนต์มาใช้กับเวิร์กโหลดที่มีปริมาณมากและใช้ประโยชน์จากการปรับขนาดอัตโนมัติของ CometAPI เพื่อจัดการกับปริมาณการรับส่งข้อมูลที่เพิ่มขึ้นโดยไม่ต้องมีการแทรกแซงด้วยตนเอง
กลยุทธ์การประหยัดต้นทุน
- รวมงานที่มีความซับซ้อนต่ำไว้บน Flash-Lite ในขณะที่สำรอง Pro หรือ Flash มาตรฐานไว้สำหรับงานหนัก
- ใช้ขีดจำกัดอัตราและการแจ้งเตือนงบประมาณในแดชบอร์ด CometAPI เพื่อป้องกันการใช้จ่ายเกินตัว
- ตรวจสอบการใช้งานตาม ID รุ่นเพื่อเปรียบเทียบต้นทุนต่อคำขอและปรับตรรกะการกำหนดเส้นทางของคุณให้เหมาะสม
แนวทางปฏิบัติที่ดีที่สุดและขั้นตอนต่อไปหลังจากการบูรณาการครั้งแรกคืออะไร
การตรวจสอบ การบันทึก และการรักษาความปลอดภัย
- เข้าสู่ระบบ:บันทึกข้อมูลเมตาของคำขอ/การตอบสนอง (วันที่และเวลา ความหน่วง การใช้โทเค็น) สำหรับการตรวจสอบประสิทธิภาพ
- การแจ้งเตือน:ตั้งค่าการแจ้งเตือนเกณฑ์สำหรับอัตราข้อผิดพลาดหรือต้นทุนเกินใน CometAPI
- ความปลอดภัย:หมุนเวียนคีย์ API เป็นประจำและจัดเก็บไว้ในห้องนิรภัยที่ปลอดภัยหรือตัวแปรสภาพแวดล้อม
รูปแบบการใช้งานทั่วไป
- chatbots:ใช้ Flash-Lite สำหรับการสอบถามผู้ใช้อย่างรวดเร็วและกลับมาใช้ Pro เพื่อการติดตามที่ซับซ้อน
- การประมวลผลเอกสาร:วิเคราะห์ PDF หรือภาพเป็นชุดในช่วงกลางคืนด้วยงบประมาณที่น้อยลง
- การวิเคราะห์แบบเรียลไทม์สตรีมข้อมูลทางการเงินหรือการปฏิบัติการเพื่อรับข้อมูลเชิงลึกทันทีผ่านทาง API สตรีมมิ่ง
สำรวจเพิ่มเติม
- ทดลองใช้การแจ้งเตือนแบบไฮบริด: รวมอินพุตข้อความและรูปภาพเพื่อสร้างบริบทที่สมบูรณ์ยิ่งขึ้น
- ต้นแบบ RAG (Retrieval-Augmented Generation) โดยการรวมเครื่องมือค้นหาเวกเตอร์กับ Gemini 2.5 Flash-Lite
- เปรียบเทียบกับข้อเสนอของคู่แข่ง (เช่น GPT-4.1, Claude Sonnet 4) เพื่อยืนยันการแลกเปลี่ยนระหว่างต้นทุนและประสิทธิภาพ
การปรับขนาดในการผลิต
- ใช้ประโยชน์จากระดับองค์กรของ CometAPI สำหรับกลุ่มโควตาเฉพาะและการรับประกัน SLA
- นำกลยุทธ์การปรับใช้สีน้ำเงิน-เขียวมาใช้เพื่อทดสอบคำเตือนหรืองบประมาณใหม่โดยไม่รบกวนผู้ใช้งานจริง
- ตรวจสอบเมตริกการใช้งานโมเดลเป็นประจำเพื่อระบุโอกาสในการลดต้นทุนเพิ่มเติมหรือปรับปรุงคุณภาพ
เริ่มต้นใช้งาน
CometAPI มอบอินเทอร์เฟซ REST แบบรวมที่รวบรวมโมเดล AI หลายร้อยโมเดลภายใต้จุดสิ้นสุดที่สอดคล้องกัน พร้อมด้วยการจัดการคีย์ API ในตัว โควตาการใช้งาน และแดชบอร์ดการเรียกเก็บเงิน แทนที่จะต้องจัดการ URL และข้อมูลรับรองของผู้ขายหลายราย
นักพัฒนาสามารถเข้าถึงได้ API Gemini 2.5 Flash-Lite (ตัวอย่าง)(แบบอย่าง: gemini-2.5-flash-lite-preview-06-17) ผ่าน โคเมทเอพีไอรุ่นล่าสุดที่แสดงไว้เป็นข้อมูล ณ วันที่เผยแพร่บทความ ในการเริ่มต้น ให้สำรวจความสามารถของรุ่นใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว โคเมทเอพีไอ เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยคุณบูรณาการ
เพียงไม่กี่ขั้นตอน คุณก็สามารถผสานรวม Gemini 2.5 Flash-Lite ผ่าน CometAPI เข้ากับแอปพลิเคชันของคุณได้ ซึ่งจะปลดล็อกการผสมผสานอันทรงพลังระหว่างความเร็ว ความคุ้มราคา และความชาญฉลาดแบบหลายโหมด โดยปฏิบัติตามแนวทางด้านบน ซึ่งครอบคลุมถึงการตั้งค่า คำขอพื้นฐาน คุณสมบัติขั้นสูง และการเพิ่มประสิทธิภาพ คุณจะสามารถมอบประสบการณ์ AI รุ่นถัดไปให้กับผู้ใช้ของคุณได้ อนาคตของ AI ที่คุ้มต้นทุนและมีปริมาณงานสูงมาถึงแล้ว เริ่มต้นใช้งาน Gemini 2.5 Flash-Lite วันนี้