

Uni-1 ของ Luma AI ไม่ได้เป็นเพียงโมเดลแปลงข้อความเป็นภาพรุ่นใหม่เท่านั้น ในกรอบความคิดของ Luma มันคือ “โมเดลให้เหตุผลแบบมัลติโหมดที่สามารถสร้างพิกเซลได้” ที่สร้างบน “Unified Intelligence” จึงสามารถเข้าใจเจตนา ตอบสนองต่อคำสั่ง และ “คิดไปพร้อมกับคุณ” รายงานทางเทคนิคของบริษัทระบุว่าโมเดลใช้ทรานส์ฟอร์เมอร์แบบอัตถอยกำเนิดที่เป็นดีโคเดอร์เท่านั้น โดยแทนข้อความและภาพในลำดับเดียวที่สลับกัน และ Uni-1 สามารถทำเหตุผลภายในเชิงโครงสร้างทั้งก่อนและระหว่างการสังเคราะห์ภาพ การผสมผสานนี้ทำให้ Uni-1 เป็นหนึ่งในการเปิดตัวโมเดลภาพที่น่าสนใจที่สุดของปี 2026
โมเดลภาพ UNI-1 คืออะไร?
Uni-1 คือโมเดลภาพรุ่นใหม่ของ Luma AI สำหรับงานที่ต้องการทั้งความเข้าใจและการสร้างอยู่ในระบบเดียว Luma นำเสนอว่ามันคือโมเดลให้เหตุผลแบบมัลติโหมด ไม่ใช่เพียงเอนจินสร้างภาพแบบ diffusion แบบคลาสสิก ซึ่งมีความสำคัญเพราะโมเดลนี้ถูกออกแบบให้ทำมากกว่าการสร้างภาพที่สวยงาม: มันถูกออกแบบมาให้ตีความคำสั่ง รักษาข้อจำกัดจากภาพอ้างอิง และให้เหตุผลตามตรรกะของฉากเป็นส่วนหนึ่งของกระบวนการสร้าง รายงานทางเทคนิคของบริษัทอธิบายว่า Uni-1 คือโมเดลแบบทำความเข้าใจและสร้างที่เป็นหนึ่งเดียวตัวแรกของบริษัทบนเส้นทางสู่ปัญญาทั่วไปแบบมัลติโหมด
ทำไม Uni-1 จึงแตกต่าง
สายงานแบบเดิมมีเพดาน: การสร้างภาพโดยไม่มีความเข้าใจไปได้แค่ระดับหนึ่งเท่านั้น Uni-1 ถูกนำเสนอว่าเป็นก้าวไปสู่ “ปัญญาแบบบูรณาการ” ที่ซึ่งภาษา การรับรู้ จินตนาการ การวางแผน และการปฏิบัติ ถูกจัดการภายในสถาปัตยกรรมเดียว นี่ไม่ใช่แค่การตั้งชื่อทางการตลาด Uni-1 สามารถขยับจาก “ความเหมือนทางสายตา” ไปสู่ “องค์ประกอบอย่างมีเจตนา ความสมเหตุสมผล และตรรกะของฉาก”
เรื่องใหญ่กว่านั้นคือ โมเดลภาพกำลังมีความเป็นเอเจนต์มากขึ้น สแต็กภาพรุ่นล่าสุดของ Google เน้นการแก้ไขเชิงสนทนา การยึดโยงกับการค้นหา การผสานภาพหลายใบ และความสม่ำเสมอของตัวละคร; ขณะที่ตระกูล GPT Image ของ OpenAI เน้นมัลติโหมดแบบเนทีฟและการทำตามคำสั่ง Uni-1 ร่วมอยู่ในแนวโน้มนี้ แต่โน้มเอียงไปที่แนวคิดซึ่งโมเดลควร “คิด” เกี่ยวกับภาพก่อนลงมือวาด นั่นทำให้ Uni-1 น่าสนใจเป็นพิเศษสำหรับเวิร์กโฟลว์ที่ความแม่นยำและการทำซ้ำได้สำคัญพอๆ กับลูกเล่นทางภาพ
Uni-1 ทำงานจริงๆ อย่างไร?
🔬 กระบวนการแปลงเป็นโทเคน
- ข้อความ → ลำดับโทเคน
- ภาพ → แพตช์ที่ทำเป็นโทเคน
- รวมเป็น ลำดับเดียวที่สลับกัน
🔁 กระบวนการสร้าง
- อินพุตพรอมป์ต + อ้างอิง
- โมเดลทำ เหตุผลภายใน
- วางแผนองค์ประกอบ
- สร้างโทเคนทีละลำดับ
เชิงคณิตศาสตร์: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 ชั้นการให้เหตุผลภายใน
Uni-1:
- แยกส่วนคำสั่ง
- แก้ข้อจำกัด
- วางแผนเลย์เอาต์ก่อนเรนเดอร์
👉 นี่คือก้าวกระโดดครั้งใหญ่เมื่อเทียบกับโมเดลแบบ diffusion
การสร้างแบบอัตถอยกำเนิดด้วยดีโคเดอร์เท่านั้น
รายละเอียดเทคนิคที่สำคัญที่สุดคือ Uni-1 เป็นแบบอัตถอยกำเนิด ไม่ใช่แบบ diffusion รายงานของ Luma ระบุว่าเป็นทรานส์ฟอร์เมอร์แบบอัตถอยกำเนิดที่เป็นดีโคเดอร์เท่านั้น และเข้ารหัสข้อความกับภาพไว้ในลำดับเดียวที่สลับกัน กล่าวอย่างง่าย โมเดลไม่ได้เริ่มจาก noise แล้วค่อยๆ “ขจัดสัญญาณรบกวน” ไปเป็นภาพ แต่จะสร้างโทเคนไปทีละขั้น ทำให้โมเดลสามารถให้เหตุผลตามพรอมป์ต แก้ข้อจำกัด และวางแผนองค์ประกอบทั้งก่อนและระหว่างการเรนเดอร์
🔬 กระบวนการแปลงเป็นโทเคน
- ข้อความ → ลำดับโทเคน
- ภาพ → แพตช์ที่ทำเป็นโทเคน
- รวมเป็น ลำดับเดียวที่สลับกัน
Diffusion vs Autoregressive
| คุณลักษณะ | โมเดล Diffusion | Uni-1 (Autoregressive) |
|---|---|---|
| การสร้าง | จาก noise → ภาพ | ทีละโทเคน |
| การให้เหตุผล | จำกัด | แข็งแกร่ง |
| การแก้ไข | อ่อน | หลายเทิร์น |
| การเรนเดอร์ข้อความ | ไม่ดี | แข็งแกร่ง |
| การควบคุม | ต่ำ | สูง |
สถาปัตยกรรมหลัก
Uni-1 คือ:
- ทรานส์ฟอร์เมอร์แบบอัตถอยกำเนิดที่เป็นดีโคเดอร์เท่านั้น
- พื้นที่โทเคนร่วมสำหรับข้อความ + ภาพ
สถาปัตยกรรมนี้สำคัญเพราะช่วยให้โมเดลรักษาความสอดคล้องเมื่อพรอมป์ตซับซ้อน Luma ระบุว่า Uni-1 สามารถแยกคำสั่ง แก้ข้อจำกัดที่ขัดแย้งกัน และวางแผนภาพก่อนเริ่มเรนเดอร์ ซึ่งมีประโยชน์อย่างยิ่งสำหรับงานอย่างเติมฉากเชิงโครงสร้าง การวางตัวแบบหลายตัว การปรับแต่งหลายรอบ และการแก้ไขที่ต้องให้ผลลัพธ์ซื่อสัตย์ต่อภาพอ้างอิงขณะเดียวกันก็ทำตามคำสั่งใหม่
สิ่งที่โมเดลดูเหมือนถูกออกแบบมาให้ทำได้ดีกว่า
การเรียนรู้เพื่อสร้างภาพช่วยปรับปรุงความเข้าใจ Luma ระบุว่าการฝึกโมเดลให้สร้างภาพช่วยเพิ่มการทำความเข้าใจเชิงภาพแบบละเอียด โดยเฉพาะระดับบริเวณ วัตถุ และเลย์เอาต์ นั่นคือเหตุผลที่มอง Uni-1 ไม่ใช่ตัวสร้างทางเดียว แต่เป็นระบบหนึ่งเดียวที่การสร้างและการทำความเข้าใจเสริมกันและกัน ในเชิงอนุมาน นั่นหมายความว่า Uni-1 พยายามลดช่องว่างระหว่าง “การมองเห็น” กับ “การสร้าง” นี่คือก้าวกระโดดครั้งใหญ่เมื่อเทียบกับโมเดลแบบ diffusion
กระบวนการสร้าง:
- อินพุตพรอมป์ต + อ้างอิง
- โมเดลทำ เหตุผลภายใน
- วางแผนองค์ประกอบ
- สร้างโทเคนทีละลำดับ
เชิงคณิตศาสตร์: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Uni-1 มีฟีเจอร์และข้อได้เปรียบหลักอะไรบ้าง?
การทำตามคำสั่งที่แข็งแกร่งและควบคุมทิศทางได้
จุดขายที่แข็งแกร่งที่สุดของ Uni-1 คือการควบคุม โมเดลถูกสร้างมาสำหรับการแก้ไขอย่างแม่นยำ การใช้อ้างอิงแบบมีโครงสร้าง และเวิร์กโฟลว์ที่ทำซ้ำได้ สำหรับครีเอเตอร์ นั่นหมายถึงลดการเสี่ยงกับพรอมป์ตและได้ผลลัพธ์ที่ทำซ้ำได้มากขึ้น
ข้อได้เปรียบเชิงปฏิบัติอย่างหนึ่งคือถูกสร้างมาสำหรับการวนทำแบบควบคุมได้ seed ทำให้ผู้ใช้ทำซ้ำผลลัพธ์ได้ ขณะที่บทบาทของภาพอ้างอิงช่วยให้โมเดลรู้ว่าภาพควรนำทางอัตลักษณ์ตัวละคร อารมณ์ โทนสี หรือองค์ประกอบใด ทำให้ Uni-1 ควบคุมได้ง่ายกว่าโมเดลที่ขับเคลื่อนด้วยพรอมป์ตล้วน โดยเฉพาะสำหรับทีมที่ผลิตโฆษณา สตอรีบอร์ด ม็อกอัปสินค้า หรือแอสเซ็ตแบรนด์ที่ต้องการความสม่ำเสมอ
การสร้างจากอ้างอิงที่คงเอกลักษณ์ไว้
ข้อได้เปรียบหลักคือการจัดการอ้างอิง Luma ระบุอย่างชัดเจนว่า Uni-1 ใช้การควบคุมที่ยึดโยงกับแหล่งอ้างอิง และสามารถคงอัตลักษณ์ องค์ประกอบ และข้อจำกัดภาพสำคัญจากอ้างอิงหนึ่งหรือหลายแหล่งได้ ทำให้มันน่าดึงดูดสำหรับเวิร์กโฟลว์เชิงพาณิชย์ เช่น ตัวละครแบรนด์ ม็อกอัปสินค้า แอสเซ็ตแคมเปญ และงานใดๆ ที่ต้องให้ตัวแบบยังจดจำได้ผ่านหลายเวอร์ชัน นี่เป็นความแตกต่างที่ชัดเจนที่สุดอย่างหนึ่งจากระบบภาพที่มุ่งความสวยงามเพียงอย่างเดียว
ความคล่องแคล่วทางวัฒนธรรมและความกว้างของสไตล์
Luma ยังเน้นการสร้างภาพที่เข้าใจบริบทวัฒนธรรม ส่วน “Cultured” แสดงให้เห็นมีม มังงะ ลุคภาพยนตร์ ภาพถ่ายทั่วไป กีฬา และภาพสัตว์ แสดงว่าโมเดลตั้งใจทำงานข้าม “ภาษาทางภาพ” มากกว่าหนึ่งสไตล์ทั่วไป ซึ่งสำคัญเพราะโมเดลภาพยุคใหม่ที่ดีไม่ได้แค่เรนเดอร์ฉากสมจริง แต่ต้องเข้าใจขนบภาพของวัฒนธรรมอินเทอร์เน็ต งานบรรณาธิการ ภาพประกอบสไตล์ และคอนเทนต์โซเชียลด้วย
การคิดแบบมัลติโหมดในฐานะทางเลือกการออกแบบ
ตัวแบ่งที่แท้จริงไม่ใช่แค่ว่า Uni-1 สร้างภาพได้ แต่ Luma กำหนดกรอบการสร้างภาพว่าเป็นงานให้เหตุผล Uni-1 สามารถทำเหตุผลภายในแบบมีโครงสร้าง และการเรียนรู้เพื่อสร้างภาพช่วยเพิ่มความเข้าใจเชิงภาพละเอียดในระดับบริเวณ วัตถุ และเลย์เอาต์ ซึ่งบ่งชี้ว่าโมเดลถูกออกแบบมาให้ “เข้าใจฉากก่อนเรนเดอร์” มากกว่าแค่ประมาณพรอมป์ตแบบสถิติ
ตัวชี้วัดประสิทธิภาพ
ผลลัพธ์ความชอบของมนุษย์จาก Luma เอง
Uni-1 อยู่ในอันดับหนึ่งตาม Elo ความชอบของมนุษย์ด้านคุณภาพโดยรวม สไตล์และการแก้ไข และการสร้างแบบอ้างอิง และอยู่อันดับสองในข้อความเป็นภาพ นั่นเป็นผลลัพธ์ที่มีนัยสำคัญ เพราะชี้ว่าโมเดลแข็งแกร่งเป็นพิเศษในงานที่ทีมโปรดักชันให้ความสำคัญ: การแก้ไข ความสม่ำเสมอ และการแปลงแบบมีไกด์ และยังชี้ว่าเคสใช้งานที่ดีที่สุดอาจไม่ใช่การสร้างภาพจากข้อความแบบยิงครั้งเดียวเท่านั้น
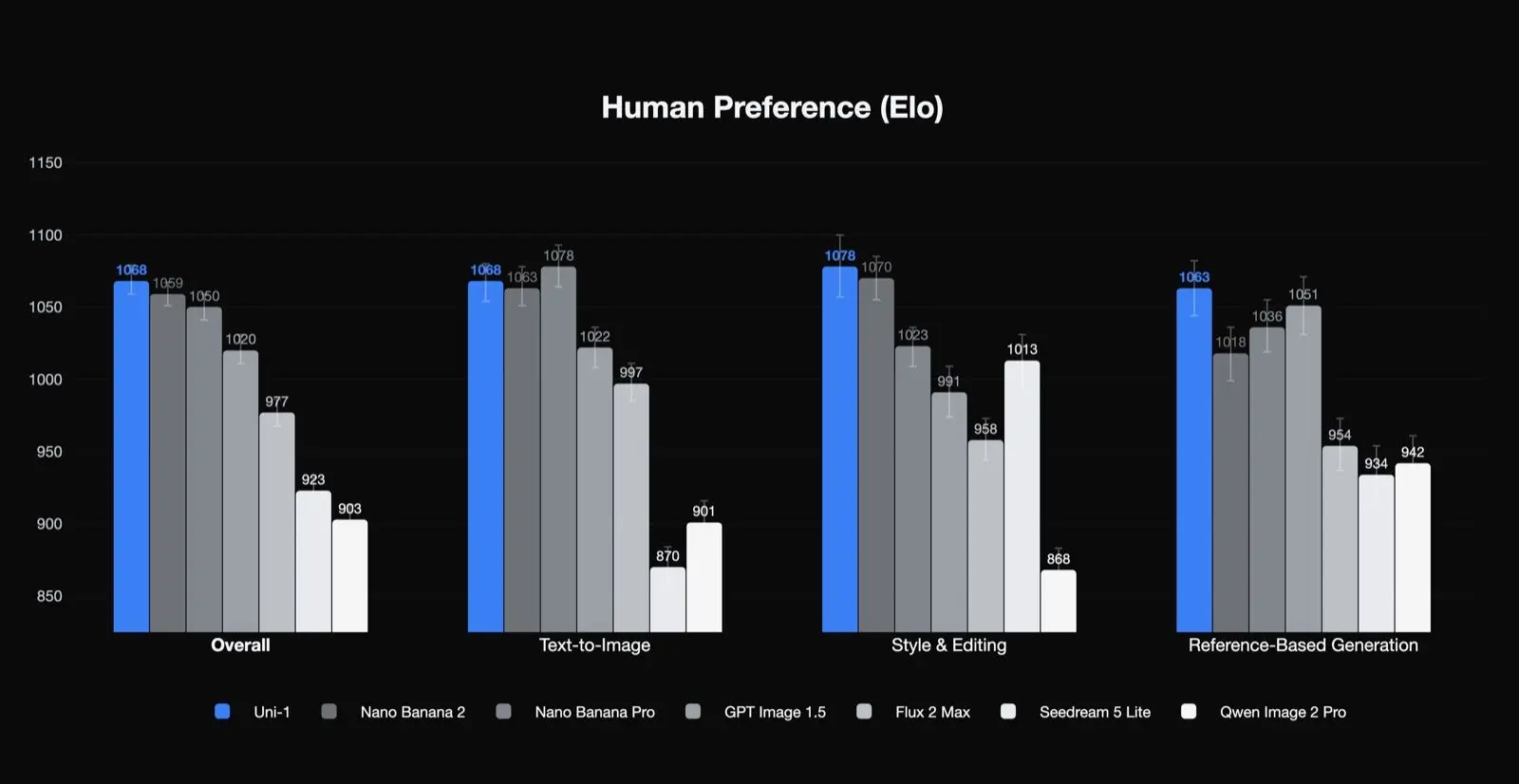
RISEBench: การแก้ไขภาพโดยใช้เหตุผลกำกับ
เบนช์มาร์กที่สะดุดตาที่สุดคือ RISEBench ซึ่งประเมินการแก้ไขภาพโดยใช้เหตุผลกำกับทั้งด้านเวลา เหตุและผล พื้นที่ และตรรกะ รายงานจากบุคคลที่สามเกี่ยวกับการเปิดตัวของ Luma ระบุว่า Uni-1 ได้คะแนนรวม 0.51 บน RISEBench เหนือ Google’s Nano Banana 2 ที่ 0.50, Nano Banana Pro ที่ 0.49 และ OpenAI’s GPT Image 1.5 ที่ 0.46 ในด้านเหตุผลเชิงพื้นที่ Uni-1 รายงานที่ 0.58 เทียบกับ Nano Banana 2 ที่ 0.47 ส่วนด้านเหตุผลเชิงตรรกะ Uni-1 รายงานที่ 0.32 มากกว่า GPT Image 1.5 ที่ 0.15 กว่าเท่าตัว ส่วนต่างโดยรวมไม่มากนัก แต่ใหญ่ในหมวดเหตุผลที่ยากที่สุด

ODinW-13 และข้ออ้างว่า “การสร้างช่วยเพิ่มความเข้าใจ”
Uni-1 ทำได้ดีมากบน ODinW-13 ซึ่งเป็นเบนช์มาร์กการตรวจจับแบบหนาแน่นที่ใช้คำเปิด โดยรายงานข้อมูลเทคนิคของ Luma ระบุว่าโมเดลเต็มได้ 46.2 mAP ใกล้เคียงกับ Gemini 3 Pro ของ Google ที่ 46.3 ขณะที่รุ่นที่เน้น “ความเข้าใจเท่านั้น” ได้ 43.9 mAP ซึ่งหมายความว่าการฝึกให้สร้างช่วยเพิ่มความเข้าใจ 2.3 คะแนน นี่เป็นข้อค้นพบที่น่าจับตาเพราะสนับสนุนวิทยานิพนธ์หลักของ Luma: การสร้างภาพและการทำความเข้าใจภาพอาจเสริมกัน ไม่ได้เป็นเป้าหมายที่ขัดกัน
ราคา Uni-1 API
| ราคาขาเข้า (ข้อความ) | $0.50 |
|---|---|
| ราคาขาเข้า (ภาพ) | $1.20 |
| ราคาขาออก (ข้อความและการคิด) | $3.00 |
| ราคาขาออก (ภาพ) | $45.45 |
ฝั่งผู้บริโภค หน้าราคาของ Luma ระบุ Plus ที่ $30/เดือน, Pro ที่ $90/เดือน, และ Ultra ที่ $300/เดือน พร้อมเครดิตทดลองฟรีในทุกแพ็กเกจ นั่นหมายความว่ามีชั้นราคาสองชั้นให้พิจารณา: สมาชิกแพลตฟอร์มสำหรับผู้บริโภค และราคา API ระดับโมเดลสำหรับการใช้งานโปรดักชัน
สำหรับตอนนี้ Uni-1 API ของ CometAPI จะ Available Soon โดยสัญญาส่วนลดในวันเปิดตัว ปัจจุบัน CometAPI ยังมีโมเดลภาพแบบ raw ที่ยอดเยี่ยม เช่น Midjourney และ Nano Banana 2
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 เทียบกับ Google’s Nano Banana 2
Nano Banana 2 ดูแข็งแกร่งกว่าในด้านความกว้างของการจัดการอ้างอิงและการผสานกับระบบนิเวศ Google เน้นการยึดโยงกับการค้นหารูปภาพ การวนแก้ไขแบบสนทนา และเวิร์กโฟลว์ที่ใช้อ้างอิงจำนวนมากได้สูงสุดถึง 14 รายการ ตรงกันข้าม Uni-1 ถูกวางกรอบชัดเจนขึ้นรอบๆ การให้เหตุผล ความสมเหตุสมผลของฉาก และการแก้ไขอย่างแม่นยำในสถาปัตยกรรมโมเดลหนึ่งเดียว ในเชิงปฏิบัติ Google ดูเหมาะกับความเร็ว ขนาดการผลิตหลัก และการยึดโยงกับระบบของ Google โดยเนทีฟ; ส่วน Luma ดูเหมาะกับการให้เหตุผลเชิงภาพแบบมีโครงสร้างและการแก้ไขภาพที่สั่งการได้
ในการเปรียบเทียบสาธารณะเกี่ยวกับ Uni-1 ข้อแลกเปลี่ยนชัดเจน: Nano Banana 2 ยังแข็งแกร่งมากสำหรับคุณภาพและความเร็วของข้อความเป็นภาพล้วน ขณะที่ Uni-1 ดันหนักไปที่การแก้ไขที่ต้องให้เหตุผล การคุมอ้างอิง และความซื่อสัตย์ต่อคำสั่ง
Uni-1 เทียบกับ OpenAI’s GPT Image
ในการรายงานเบนช์มาร์ก Uni-1 เฉือน GPT Image 1.5 บน RISEBench โดยรวม และชัดเจนยิ่งขึ้นในเหตุผลเชิงตรรกะ เมื่อเทียบกับตระกูล GPT Image ของ OpenAI แล้ว Uni-1 ถูกวางตำแหน่งแคบและดุดันกว่ารอบๆ การให้เหตุผลเชิงภาพและการแก้ไขที่ควบคุมได้ เอกสารของ OpenAI เน้นความรู้เกี่ยวกับโลก ความเข้าใจมัลติโหมด และบริบท; เอกสารของ Luma เน้นเหตุผลภายในแบบมีโครงสร้าง การควบคุมโดยยึดโยงอ้างอิง และทักษะการแก้ไขภาพที่ผ่านการทดสอบ ดังนั้นแม้ทั้งคู่จะเป็นมัลติโหมด Uni-1 ก็เป็น “โมเดลเชี่ยวชาญภาพที่ให้เหตุผล” อย่างชัดเจนกว่า ในขณะที่ GPT Image ดูเหมือนระบบมัลติโหมดทั่วไปที่ “บังเอิญ” สร้างภาพได้ดีมาก
การเปรียบเทียบราคาในทั้งสาม
ด้านราคา การเปรียบเทียบขึ้นอยู่กับขนาดผลลัพธ์และระดับผลิตภัณฑ์ จึงไม่เทียบกันตรงๆ Uni-1 ที่เทียบเท่า 2048px อยู่ราว $0.0909 ต่อภาพ หน้าราคาโมเดลภาพล่าสุดของ Google ระบุ $0.134 ต่อภาพ 1K/2K และ $0.24 ต่อภาพ 4K สำหรับพรีวิวโมเดลภาพ Gemini ล่าสุด ขณะที่หน้าราคาของ OpenAI สำหรับ GPT Image ระบุราคาต่อภาพ $0.011 สำหรับคุณภาพต่ำที่ 1024x1024, $0.042 สำหรับคุณภาพกลาง และ $0.167 สำหรับคุณภาพสูง โดยภาพขนาดใหญ่คุณภาพสูงอยู่ที่ $0.25 กล่าวอีกนัยหนึ่ง OpenAI อาจถูกกว่ามากในช่วงล่าง Google ดุดันที่ความเร็วและสเกลการผลิต และ Uni-1 อยู่กลางๆ ด้วยโปรไฟล์ราคา/ประสิทธิภาพที่เน้น 2K อย่างแข็งแรง
ความแตกต่างเชิงแนวคิด
| โมเดล | แนวทาง |
|---|---|
| Uni-1 | ปัญญาแบบมัลติโหมดที่บูรณาการ |
| GPT Image | LLM + การสร้างภาพ |
| Nano Banana 2 | Diffusion เพื่อการผลิตที่ปรับแต่งเหมาะสม |
ตารางเปรียบเทียบรายละเอียด
| คุณลักษณะ | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| สถาปัตยกรรม | อัตถอยกำเนิด | ไฮบริด | Diffusion |
| การบูรณาการมัลติโหมด | ✅ โดยกำเนิด | บางส่วน | ❌ |
| ความสามารถในการให้เหตุผล | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| คุณภาพภาพ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| การเรนเดอร์ข้อความ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| เวิร์กโฟลว์การแก้ไข | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| ความเร็ว | ปานกลาง | เร็ว | เร็ว |
| การควบคุม | สูง | ปานกลาง | ปานกลาง |
CometAPI มีภาพแบบ raw เชิงโต้ตอบสำหรับ GPT Image 1.5, Nano Banana 2, และ Uni-1 ที่กำลังจะมา รวมถึงการเขียนโปรแกรม API ตัวเลือกราคาลดและจ่ายตามการใช้งานทำให้เป็นตัวเลือกยอดนิยมสำหรับนักพัฒนา
Uni-1 เหมาะกับอะไรที่สุด
Uni-1 ดูแข็งแกร่งเป็นพิเศษสำหรับกรณีที่ต้องการความสามารถในการทำซ้ำ ความสม่ำเสมอของตัวละคร หรือการควบคุมหลายอ้างอิง ซึ่งรวมถึงแคมเปญแบรนด์ ม็อกอัปสินค้า ไอเดียงานบรรณาธิการ สตอรีบอร์ด เวอร์ชันสำหรับโลคัลไลเซชัน และการแก้ไขภาพที่ต้องคงองค์ประกอบเดิมไว้แต่เปลี่ยนสไตล์หรือสภาพแวดล้อม ตัวอย่างของ Luma เองเน้นเคสเหล่านี้อย่างมาก และการแบ่ง “Create vs Modify” ของโมเดลก็แทบจะตอบปัญหาเวิร์กโฟลว์โปรดักชันทั่วไปโดยตรง
หากงานของคุณส่วนใหญ่คือ “ทำให้สวยจากพรอมป์ตเดียว” ตัวแบ่งอาจดูไม่ดราม่ามาก แต่ถ้าเวิร์กโฟลว์ของคุณคือ “ทำ 5 เวอร์ชันที่เกี่ยวข้องกัน คงตัวละครเดิมไว้ รักษากรอบภาพ เปลี่ยนแสง และทำให้ทำซ้ำได้สัปดาห์หน้า” การออกแบบของ Uni-1 จะเริ่มมีเหตุผลมากขึ้น นี่เป็นข้อสรุปเชิงอนุมาน แต่ไหลตามธรรมชาติจากฟีเจอร์การควบคุมที่ Luma เน้น
แนวปฏิบัติที่ดีที่สุดเพื่อผลลัพธ์ที่ดีกับ Uni-1
เริ่มจากการใช้โหมดที่ถูกต้อง คำแนะนำของ Luma เรียบง่าย: ใช้ Create เมื่ออยากสร้างฉากใหม่ ใช้ Modify เมื่ออยากคงฉากเดิมไว้ การผสมเจตนาเหล่านี้ทำให้ผลลัพธ์แกว่ง
ใช้ป้ายกำกับอ้างอิงให้เป็นมืออาชีพ Luma แนะนำวลีอย่าง “Use IMAGE1 as a STYLE reference” หรือ “Use IMAGE2 as LIGHTING.” โมเดลทำได้ดีกว่าเมื่อแต่ละอ้างอิงมีหน้าที่ แทนที่จะเป็น “แรงบันดาลใจ” แบบคลุมเครือ
ล็อก seed เมื่อคุณเจอผลลัพธ์ที่ใช่ Luma แนะนำให้สำรวจโดยยังไม่ตั้ง seed ก่อน จากนั้นบันทึก seed เมื่อได้ผลลัพธ์ที่ดี แล้วค่อยเปลี่ยนตัวแปรครั้งละหนึ่งอย่าง นั่นเป็นหนทางง่ายที่สุดในการเปลี่ยนการสร้างให้กลายเป็นระบบโปรดักชันที่ควบคุมได้
เฉพาะเจาะจง และเป็นรูปธรรม Luma เตือนให้เลี่ยงคำกำกวมอย่าง “สวย” หรือ “สุดยอด” และสนับสนุนสุนทรียศัพท์แบบมีชื่อ เช่น “โปสเตอร์หนังอิตาเลียนยุค 1970s แนว giallo” หรือคิวสไตล์กล้องที่แน่นอน ในทางปฏิบัติ พรอมป์ตที่เฉพาะมักชนะพรอมป์ตกวี เพราะโมเดลยึดกับโครงจริงได้
ใช้สายโซ่ Create → Modify Luma ระบุชัดว่าเป็นหนึ่งในเวิร์กโฟลว์ที่ทรงพลังที่สุด: สำรวจใน Create แล้วเกลาใน Modify นี่คือจุดหวานสำหรับงานโปรดักชันจริง เพราะลดการย้อนกลับและคงส่วนดีขององค์ประกอบไว้ขณะรัดกุมรายละเอียด
บทสรุปสุดท้าย
Uni-1 คือคำประกาศที่ชัดที่สุดของ Luma ว่าการสร้างภาพกำลังก้าวจาก “ใส่พรอมป์ตแล้วได้ภาพ” ไปสู่การสร้างภาพที่ขับเคลื่อนด้วยการให้เหตุผล จุดแข็งที่เปิดเผยคือการควบคุม การจัดการอ้างอิง การทำซ้ำได้ และสถาปัตยกรรมโมเดลที่ทำให้ภาษาและพิกเซลอยู่ในระบบเดียวกัน
สำหรับครีเอเตอร์และทีมที่ใส่ใจผลลัพธ์ภาพที่คลิกสูง ตัวละครที่สม่ำเสมอ การแก้ไขที่แม่นยำ และความชัดเจนด้านราคาในความละเอียดสูง Uni-1 เป็นโมเดลที่น่าจับตาอย่างยิ่ง หากการเปิดตัว API เป็นไปอย่างราบรื่น มันอาจกลายเป็นหนึ่งในทางเลือกที่น่าสนใจที่สุดแทน Google’s Nano Banana 2 และ OpenAI’s GPT Image 1.5 ในปี 2026
กำลังวางแผนเริ่มสร้างภาพแบบ raw อยู่หรือไม่? CometAPI แพลตฟอร์มรวม API โมเดลมัลติโหมดครบวงจร ยินดีต้อนรับคุณ!