

xAI خاموشی سے جاری کیا گیا۔ گروک 4.1 (نومبر 17-18، 2025) - گروک 4 میں ایک فوکسڈ اپ گریڈ جو ترجیح دیتا ہے جذباتی ذہانت، تخلیقی اظہار، اور کم فریب کاری Grok کی ابتدائی ریلیز کے استرا تیز استدلال کو برقرار رکھتے ہوئے یہ دو طریقوں (تھنکنگ / نان تھنکنگ) میں آتا ہے، نومبر کے اوائل میں خاموشی سے رول آؤٹ کیا گیا، LMArena پر لیڈر بورڈ کے اعلیٰ نتائج دکھاتا ہے، اور grok.com، Grok ایپس اور API کے ذریعے دستیاب ہے۔
Grok 4.1 کیا ہے؟
Grok 4.1 Grok 4 کا بڑھتا ہوا، پیداوار پر مرکوز جانشین ہے: ایک خاندانی رکن جس کو اسی بڑے پیمانے پر کمک سیکھنے کی بنیاد پر بنایا گیا تھا لیکن تربیت کے بعد کی بھاری اصلاح کے ساتھ عمدہ اور دوبارہ تربیت دی گئی ہے جس کا مقصد انداز، شخصیت، صف بندی، اور حقیقی دنیا کی وشوسنییتا ہے۔ اسے ایک عملی، "استعمال کے قابل" قدم آگے بڑھایا جا رہا ہے: نابینا انسانی ترجیحی ٹیسٹوں میں زیادہ ہوشیار، زیادہ جذباتی طور پر ذہین، تخلیقی تحریر میں بہتر، اور اس قسم کے پراعتماد لیکن غلط "فریب" کا خطرہ کم ہے جس نے پہلے اعلیٰ کارکردگی کا مظاہرہ کرنے والے LLMs کو جنم دیا ہے۔
Grok 4.1 درج ذیل چار جہتوں میں قابلیت کی تبدیلیاں حاصل کرتا ہے:
- تخلیقی صلاحیت: تحریری، کہانی سنانے، اور سماجی سیاق و سباق میں مضبوط زبان کے انداز اور تخیل کا مظاہرہ؛
- جذباتی ذہانت: لہجے اور جذباتی تبدیلیوں کو پہچانتا ہے، زیادہ انسانوں جیسی جذباتی منطق کے ساتھ جواب دیتا ہے اور تسلی بخش اور سمجھنے والے ردعمل پیدا کرتا ہے۔
- شخصیت کی ہم آہنگی: طویل گفتگو میں مستقل لہجے اور شخصیت کو برقرار رکھتا ہے، اب پہلے کے ماڈلز کے متضاد رویے کی نمائش نہیں کرتا۔
- تعاون پر مبنی: ملٹی ٹرن ڈائیلاگ یا ٹاسک تعاون میں ہم آہنگی اور مقصد کی آگاہی کو برقرار رکھتا ہے۔
xAI ایک جملے میں اپنی خصوصیات کا خلاصہ کرتا ہے: "یہ زیادہ ادراک، زیادہ ہمدرد، اور ایک مربوط شخص کی طرح ہے۔"
گروک 4.1 ہڈ کے نیچے کیسے کام کرتا ہے؟
Grok 4.1 کو اسی پہلے سے تربیت یافتہ بیک بون کے طور پر سمجھا جاتا ہے جو Grok 4 فیملی میں استعمال ہوتا ہے نیز ایک پرتوں والی پوسٹ ٹریننگ پائپ لائن جس پر توجہ مرکوز ہوتی ہے۔ ریوارڈ ماڈلنگ، اسٹائل الائنمنٹ، اور ایجنٹی جائزہ لینے والے.
تربیت اور صف بندی کے مراحل کیا ہیں؟
Grok 4.1 جدید فرنٹیئر LLMs کی ایک ملٹی سٹیج پائپ لائن پر کام کرتا ہے، جو 4.1 کے لیے دو اہم شفٹوں کے ساتھ ڈھال لیا گیا ہے:
- پری ٹریننگ + درمیانی تربیت: ویب ڈیٹا پر بڑے کارپس پری ٹریننگ + ڈومین کے علم اور ملٹی موڈل صلاحیتوں کو بڑھانے کے لیے ٹارگٹڈ مڈ ٹریننگ۔
- زیر نگرانی فائن ٹیوننگ (SFT): مطلوبہ طرز عمل کے لیے انسانی مظاہرے (جواب، انکار کی حکمت عملی)۔
- ریوارڈ ماڈلنگ (ناول ایپلی کیشن): xAI نے نہ صرف انسانی ترجیحی لیبلز پر تربیت یافتہ انعامی ماڈلز بلکہ استعمال بھی کیے ہیں۔ فرنٹیئر ایجنٹ استدلال کے ماڈل انعامی گریڈرز کے طور پر - مؤثر طریقے سے اعلی صلاحیت، ماڈل پر مبنی تشخیص کار امیدواروں کے نتائج کو پیمانے پر اسکور کرنے دیتے ہیں۔ اس نے غیر قابل تصدیق صفات کی اصلاح کو فعال کیا جیسے انداز، شخصیت کی ہم آہنگی، ہمدردی اور مددگار ایک ناممکن طور پر بڑے انسانی لیبلنگ بجٹ کی ضرورت کے بغیر۔
- پالیسی کی اصلاح (آر ایل ایچ ایف / آر ایل ماڈل انعامات سے): معیاری پالیسی آپٹیمائزیشن سیکھے ہوئے انعامی سگنلز کا استعمال کرتے ہوئے تعینات پالیسی (ماڈل صارفین کے ساتھ تعامل کرتے ہیں) تیار کرنے کے لیے۔
ریوارڈ ماڈلنگ اپروچ میں نیا کیا ہے؟
روایتی RLHF میں آپ انسانی ترجیحی لیبلز (A/B) جمع کرتے ہیں، ان لیبلز کی پیشن گوئی کرنے کے لیے ایک انعامی ماڈل کو تربیت دیتے ہیں، اور پھر اس سیکھے ہوئے انعام کے مقابلے میں RL (یا مسترد کرنے کے نمونے لینے) کے ساتھ بیس ماڈل کو بہتر بناتے ہیں۔ لیکن دو عملی اختراعات xAI نمایاں کرتی ہیں:
- ایجنٹی انعام کے ماڈل: خالصتاً انسانی ججوں کے بجائے، xAI نے لطیف خصوصیات (لہجہ، جذباتی نزاکت، تخلیقی صلاحیت) کا جائزہ لینے کے لیے اسکوررز کے طور پر قابل "ایجنٹک" استدلال کے ماڈلز کا استعمال کیا۔ گریڈر جوڑے کے لحاظ سے ہزاروں موازنہ تیزی سے چلا سکتے ہیں، جس سے انجینئرز کو تیزی سے اعادہ کر سکتے ہیں۔ یہ انداز اور جذباتی ذہانت میں بڑی بہتری کا طریقہ کار ہے۔
- غیر تصدیق شدہ سگنلز کے لیے پوسٹ ٹریننگ سیدھ: ان اوصاف کے لیے جن کی آپ تعییناتی میٹرک سے پیمائش نہیں کر سکتے ہیں (مثال کے طور پر، "گرمیت" یا "مربوط شخصیت") انہوں نے خصوصی انعامی مقاصد اور اسکیلنگ نصاب متعارف کرایا تاکہ ماڈل سیکھے سٹائل بنیادی حقائق کی درستگی کی قربانی کے بغیر آؤٹ پٹس۔
"سوچ" بمقابلہ "غیر سوچنا" تکنیکی طور پر کیسے کام کرتا ہے؟
- گروک 4.1 سوچنا (کوڈ نام
quasarflux) - حتمی جواب تیار کرنے سے پہلے واضح استدلال کے اقدامات (سوچ ٹوکن) کو ظاہر کرتا ہے۔ LMArena میں پیچیدہ کاموں اور اعلی Elo کے لیے موزوں ہے۔ اضافی ٹوکن کا تخمینہ لگانے کا وقت لگتا ہے لیکن کثیر مرحلہ استدلال کے کاموں، ڈیبگنگ، اور وضاحت کی اہلیت میں مدد ملتی ہے۔ - گروک 4.1 نان تھنکنگ (کوڈ نام
tensor) ایک واحد، فوری حتمی جواب کے لیے واضح انٹرمیڈیٹ ٹوکنز کو نظرانداز کرتا ہے۔ یہ لیٹنسی اور ٹوکن لاگت کو کم کرتا ہے جبکہ ابھی بھی اسی بہتر پالیسی وزن سے فائدہ اٹھا رہا ہے۔ نان تھنکنگ موڈ کو انتہائی کم تاخیر اور اب بھی انتہائی قابل ہونے کے لیے بہتر بنایا گیا تھا۔
جذبات اور انداز کی سیدھ میں اصلاح
سادہ "سچائی" کے اشاروں سے ہٹ کر، Grok 4.1 میں جذبات، لہجے اور باہمی انداز کے لیے ٹارگٹ الائنمنٹ آپٹیمائزیشن شامل ہے۔ اس کا مطلب ہے کہ ٹریننگ پائپ لائن میں انعام یا نقصان کے اجزاء شامل ہوتے ہیں جو واضح طور پر غیر مماثل لہجے کو سزا دیتے ہیں (مثال کے طور پر، جب ہمدردی مناسب ہو تو بلا ضرورت کٹ جانا) اور انعامی ردعمل جو مطلوبہ انداز یا جذباتی پروفائل سے میل کھاتا ہے۔ Grok 4.1 میں، AI نے سب سے پہلے "Personality Alignment" کا اصلاحی مقصد متعارف کرایا۔
اس کا مقصد ماڈل کی شناخت کے مستقل اور مستحکم احساس کو برقرار رکھنے میں مدد کرنا ہے۔ Grok 4 کے مقابلے میں، 4.1 تربیت کے مقاصد میں درج ذیل کو شامل کرتا ہے:
- جذباتی اظہار کے طول و عرض کے لیے مثبت انعامات (جذباتی صف بندی کا انعام)؛
- شخصیت کی ہم آہنگی کا میٹرک۔
Grok 4.1 کا جائزہ کیسے لیا گیا - اور اس نے کیسے کارکردگی کا مظاہرہ کیا؟
نابینا انسانی ترجیحات کے ٹیسٹ نے کیا دکھایا؟
ایک خاموش رول آؤٹ کے دوران، Grok 4.1 کو لائیو ٹریفک میں پچھلے پروڈکشن ماڈل کے مقابلے میں 64.78% وقت ترجیح دی گئی تھی - ایک مضبوط انسانی ترجیحی سگنل جو جنگلی میں بہتر بات چیت کے نتائج کی نشاندہی کرتا ہے۔
کیا گروک 4.1 ٹاپ لیڈر بورڈز ہے؟
xAI نے رپورٹ کیا ہے کہ Grok 4.1's سوچنا موڈ پر بیٹھتا ہے LMArena کے ٹیکسٹ ایرینا پر #1کی اطلاع دی گئی Elo کے ساتھ 1483، اور اس کا غیر معقول (تیز) موڈ 1465 Elo کے ساتھ نمبر 2 پر ہے — درستگی اور پیشکش دونوں کے لیے مضبوط عوامی لیڈر بورڈ پلیسمنٹ (اسٹائل کنٹرول ایک کردار ادا کرتا ہے)۔
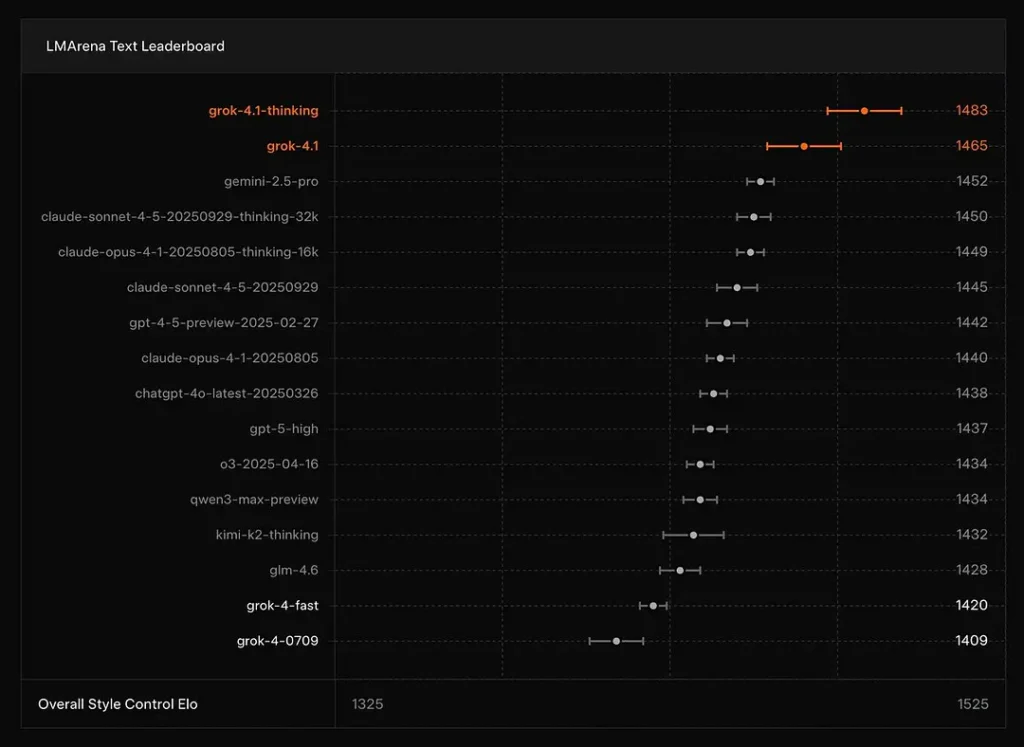
نتیجہ: Grok 4.1 مرکزی دھارے کے GPT-4.5 اور کلاڈ سیریز کے ماڈلز کو متن کی سمجھ، جنریشن اور مجموعی معیار میں پیچھے چھوڑتا ہے، GPT-5 ایڈوانسڈ پیش نظارہ ورژن کے بعد دوسرے نمبر پر ہے۔
جذباتی انٹیلی جنس
xAI نے EQ-Bench3 چلایا، جذباتی ذہانت کے لیے ایک خصوصی ٹیسٹ جس میں 45 چیلنجنگ رول پلے منظرنامے شامل ہیں، اور رپورٹ کرتی ہے کہ Grok 4.1 ہمدردی، رفتار اور باہمی بصیرت میں مضبوط فوائد کو ظاہر کرتا ہے۔ گروک 4.1 نے اداسی، سکون، ہمدردی کے سیاق و سباق کو سمجھنے میں سب سے زیادہ اسکور کیا۔

تخلیقی تحریر - کیا یہ حقیقت میں زیادہ تخیلاتی ہے؟
گروک 4.1 کا جائزہ لیا گیا۔ تخلیقی تحریر v3 (روبرک + ایلو اسکورنگ کے ساتھ 3 تکرار پر 32 اشارے)۔ xAI کا کہنا ہے کہ 4.1 کے تحریری انداز، آواز کی مستقل مزاجی، اور بیانیہ کی تخلیقی صلاحیتوں میں خاطر خواہ اضافہ ہوا، جو اسے تخلیقی کاموں کے لیے حالیہ لیڈر بورڈز کے اوپری حصے کے قریب رکھتا ہے (مثال کے طور پر اشارے ریلیز میں شامل ہیں)۔ آزاد رپورٹنگ نے ان نتائج کی عکاسی کی: جائزہ لینے والوں نے خاص طور پر زیادہ "مخصوص آواز" اور طویل شکل میں بہتر ہم آہنگی دیکھی۔ تحریری معیار کے لحاظ سے، Grok 4.1 GPT-5 سیریز کے ماڈلز کے بعد دوسرے نمبر پر ہے اور Claude، Gemini اور Kimi کی پوری پروڈکٹ لائنوں کو پیچھے چھوڑ دیتا ہے۔

کم فریب / ایمانداری
xAI نے فریب کاری کی شرح میں قابل ذکر کمی کا دعویٰ کیا: انہوں نے اطلاع دی (اعلان اور سماجی پوسٹس میں) گروک 4.1 ہے ~3× فریب ہونے کا امکان کم ہے۔ پہلے کے Grok ماڈلز کے مقابلے، پروڈکشن ٹریفک کے تجزیوں اور FActScore طرز کے جائزوں کا حوالہ دیتے ہوئے (مثال کے طور پر، جیو/بایوگرافی کے سوالوں کے سیٹ، کم بہتر ہے)۔ خاص طور پر "غیر معقول موڈ" میں جہاں بیرونی تلاش کے اوزار دستیاب ہیں، حقائق کی مستقل مزاجی زیادہ مستحکم ہے۔

گروک 4.1 دوسرے ماڈلز کو کیوں "کرش" کرتا ہے - کیا یہ ہائپربل ہے؟
"کرشز" مارکیٹنگ سے متعلق ہے، لیکن دعوے کے پیچھے معروضی دعوے ہیں:
- لیڈر بورڈز: Grok 4.1 ٹیکسٹ جنریشن کے لیے پبلک LMArena لیڈر بورڈز (1483 Elo for Thinking mode) اور مضبوط تخلیقی اور EQ- بنچ شوز فی xAI کی ریلیز پر اعلیٰ پوزیشنز پر فائز ہے۔ وہ سیب سے سیب کے مسابقتی میٹرکس ہیں جو پوری کمیونٹی میں استعمال ہوتے ہیں۔
- حقیقی ٹریفک ترجیح جیت: xAI لائیو ٹریفک پر خاموش رول آؤٹ سے اندھے موازنہ میں انسانی ترجیحات کی جیت کی اطلاع دیتا ہے (~65% ترجیح بمقابلہ پروڈکشن ماڈل)۔ یہ حقیقی صارف کی بہتری کی عکاسی کرتا ہے، نہ صرف کاغذی معیارات۔
- عملی نئی صلاحیت: ماڈل گریڈرز، غیر تصدیق شدہ سگنلز پر RL، اور سخت ان پٹ فلٹرز کا امتزاج ایک عملی انجینئرنگ قدم ہے جو بات چیت، ہمدردانہ اور تخلیقی کاموں میں صارف کے تجربے کو براہ راست بہتر بناتا ہے جہاں حریف تاریخی طور پر کم کارکردگی کا مظاہرہ کرتے ہیں۔
لہذا، جبکہ "کرشز" یہ کہنے کا ایک رنگین طریقہ ہے کہ "متعدد عوامی اور داخلی جائزوں میں رہنمائی کرتا ہے"، بنیادی عوامی میٹرکس xAI نے اس نتیجے کو واپس شائع کیا۔
Grok 4.1 تک کیسے رسائی حاصل کریں۔
صارف / ایپ تک رسائی
xAI نے وقتاً فوقتاً Grok 4.1 کو "آٹو" موڈ میں مفت یا پروموشنل ونڈو کے طور پر قابل رسائی بنایا ہے، لیکن اعلیٰ درجے (SuperGrok، SuperGrok Heavy) اور اعلیٰ کوٹے کے ساتھ API رسائی موجود ہے اور ادا شدہ پیشکشوں کے طور پر برقرار ہے۔
Grok 4.1 تمام صارفین کے لیے دستیاب ہے۔ on grok.com, X (سابقہ ٹویٹر)، اور iOS اور Android Grok ایپس، فوری طور پر آٹو موڈ میں رول آؤٹ ہو رہی ہیں جبکہ ماڈل چننے والے میں واضح طور پر "Grok 4.1" کے طور پر بھی قابل انتخاب ہیں۔
API تک رسائی اور ڈویلپر کے منصوبے
Grok 4.1 اینڈ پوائنٹس xAI API کے ذریعے دستیاب ہیں۔ اس مضمون کی اشاعت کی تاریخ تک، سرکاری GPT 4.1 API جاری نہیں کیا گیا ہے۔
CometAPI بشمول جدید ترین ماڈل ڈائنامکس پر نظر رکھنے کا وعدہ کرتا ہے۔ گروک 4.1 APIجو کہ باضابطہ ریلیز کے ساتھ ساتھ جاری کیا جائے گا۔ براہ کرم اس کا انتظار کریں اور CometAPI پر توجہ دینا جاری رکھیں۔ انتظار کرتے وقت، آپ گروک کے دوسرے ماڈلز پر توجہ دے سکتے ہیں جیسے Grok-code-fast-1 اور گروک 4کھیل کے میدان میں ان کی صلاحیتوں کو دریافت کریں اور کال کرنے کے لیے تفصیلی ہدایات کے لیے API گائیڈ سے رجوع کریں۔ رسائی کرنے سے پہلے، براہ کرم یقینی بنائیں کہ آپ نے CometAPI میں لاگ ان کیا ہے اور API کلید حاصل کر لی ہے۔
Grok 4.1 کو پیداوار میں استعمال کرنے کے لیے عملی نکات
فریب کاری کے خطرے کو کیسے کم کیا جائے۔
- لائیو تلاش کو فعال کریں۔ یا معلومات کے حصول کے سوالات کے لیے تصدیق شدہ ٹول چین۔
- تصدیقی اقدامات فراہم کریں۔: ماڈل سے حقائق پر مبنی دعووں کے ذرائع اور ثبوت واپس کرنے کو کہیں۔ کا استعمال کریں
responseحوالہ جات کا معائنہ کرنے کے لیے میٹا ڈیٹا (اگر دستیاب ہو)۔ - ڈیٹرمنسٹک چیکس چلائیں۔ (حقیقت کی جانچ پڑتال کرنے والے LLMs، سٹرکچرڈ ڈیٹا کی توثیق کرنے والے) اعلی اسٹیک آؤٹ پٹس کے لیے پوسٹ پروسیسنگ قدم کے طور پر۔
لہجے اور انداز کو کیسے کنٹرول کریں۔
- آواز کو ٹھیک کرنے کے لیے واضح سسٹم پرامپٹس استعمال کریں ("آپ رسمی اور ہمدرد ہیں۔")۔
- تمام ایپلیکیشنز میں مستقل آواز کے لیے زیر نگرانی پرامپٹس اور چھوٹے مقامی ٹیمپلیٹس کا استعمال کریں۔
- جہاں دستیاب ہو، xAI کے اسٹائل کنٹرول آپشن اور انعام سے چلنے والے اسٹیئرنگ نوبس کا فائدہ اٹھائیں۔
حتمی فیصلہ: کیا گروک 4.1 ایک سمندری تبدیلی ہے؟
گروک 4.1 ہے۔ نوٹ ایک بالکل نیا فن تعمیر؛ بلکہ، یہ ایک نفیس اور سوچنے والا ہے۔ پوسٹ ٹریننگ / سیدھ ریلیز جو اس بات پر فوکس کرتی ہے کہ چیٹ میں انسان اصل میں کیا خیال رکھتے ہیں: شخصیت، جذباتی ذہانت، تخلیقی صلاحیت، اور کم حقائق پر مبنی غلطیاں. لیڈر بورڈز پر قابل پیمائش فوائد، بڑے پیمانے پر حقیقی ٹریفک کی ترجیحات، اور بہتر حفاظتی ٹولنگ۔ ایسی ایپلی کیشنز کے لیے جو اعلیٰ معیار کی گفتگو، تخلیقی تعاون، یا لہجے میں حساس مدد پر انحصار کرتی ہیں، Grok 4.1 ایک بڑا قدم ہے اور، کئی کمیونٹی بینچ مارکس میں، ریلیز کے وقت سرفہرست ہے۔
CometAPI ایک تجارتی API-جمع کرنے والا پلیٹ فارم ہے جو ڈویلپرز کو ایک سے زیادہ وینڈرز کے سیکڑوں AI ماڈلز - متن LLMs، امیج/ویڈیو جنریٹرز، ایمبیڈنگز، اور مزید - ایک سنگل، مستقل انٹرفیس کے ذریعے متحد، OpenAI طرز کے REST تک رسائی فراہم کرتا ہے۔ OpenAI، Anthropic، Google، Meta، یا چھوٹے خصوصی ماڈل فراہم کنندگان کے لیے علیحدہ SDKs یا bespoke endpoints کی وائرنگ کرنے کے بجائے، CometAPI آپ کو ماڈل کے تاروں اور چند پیرامیٹرز کو تبدیل کر کے مختلف ماڈلز کو کال کرنے دیتا ہے۔
کوشش کرنے کے لیے تیار ہیں؟→ CometAPI کے لیے آج ہی سائن اپ کریں۔ !
اگر آپ AI پر مزید ٹپس، گائیڈز اور خبریں جاننا چاہتے ہیں تو ہمیں فالو کریں۔ VK, X اور Discord!