

Google và cánh tay nghiên cứu DeepMind đã âm thầm (rồi không còn âm thầm nữa) thúc đẩy thêm một bước quan trọng trong lộ trình Gemini: Gemini 3.1 Pro. Bản phát hành này, được triển khai trên các bề mặt hướng người dùng CometAPI, được định vị là một nâng cấp về hiệu năng và suy luận cho dòng Gemini 3 — hứa hẹn khả năng suy luận dạng dài mạnh mẽ hơn, hiểu đa phương thức tốt hơn và khả năng mở rộng cao hơn cho các ứng dụng thực tế.
Mô hình mới nhất của Google — Gemini 3.1 Pro là gì?
Gemini 3.1 Pro là bản cập nhật gia tăng đầu tiên trong gia đình Gemini 3, được định vị là mô hình suy luận “năng lực cao nhất” tối ưu cho các tác vụ nhiều bước, đa phương thức và mang tính tác nhân. Được phát hành bản xem trước công khai vào giữa tháng 2 năm 2026 (thông báo xem trước vào 19–20/02/2026), mô hình này nhắm rõ vào các kịch bản đòi hỏi chuỗi suy luận kéo dài, sử dụng công cụ và hiểu ngữ cảnh dài — ví dụ: tổng hợp nghiên cứu quy mô lớn, tác nhân kỹ thuật phối hợp công cụ và hệ thống, và phân tích đa phương thức các tài liệu trộn văn bản, hình ảnh, âm thanh và video.
Ở mức độ khái quát, Gemini 3.1 Pro được các nhà phát triển mô tả là:
- Đa phương thức gốc — có thể tiếp nhận và suy luận trên văn bản, hình ảnh, âm thanh và video.
- Thiết kế cho ngữ cảnh dài — hỗ trợ cửa sổ ngữ cảnh rất lớn, phù hợp với toàn bộ codebase, hồ sơ nhiều tài liệu hoặc bản chép lời dài.
- Tối ưu cho suy luận đáng tin cậy và quy trình tác nhân, nghĩa là được tinh chỉnh để lập kế hoạch, gọi công cụ và kiểm chứng đầu ra qua các tác vụ nhiều bước.
Vì sao điều này quan trọng lúc này: các tổ chức và nhà phát triển đang chuyển từ “trợ lý hội thoại tốt” sang “tác nhân hỗ trợ quyết định và nghiên cứu rủi ro cao” (soạn thảo pháp lý, tổng hợp R&D, hiểu tài liệu đa phương thức). Gemini 3.1 Pro được thiết kế rõ cho “hành lang” đó — nhằm giảm ảo giác, tạo suy luận có thể truy vết và tích hợp với CometAPI cho cả thử nghiệm lẫn sản xuất.
Những điểm nổi bật kỹ thuật và tính năng của Gemini 3.1 Pro là gì?
Đa phương thức gốc và cửa sổ ngữ cảnh cực lớn
Gemini 3.1 Pro tiếp nối trọng tâm đa phương thức của dòng Gemini. Theo thẻ mô hình và ghi chú sản phẩm, mô hình tiếp nhận và suy luận trên văn bản, hình ảnh, âm thanh và video trong cùng một pipeline — năng lực này đơn giản hóa quy trình khi dữ liệu trộn lẫn nhiều kiểu (ví dụ: bản cung lời pháp lý kèm âm thanh + bản chép + bản quét). Đáng chú ý, mô hình hỗ trợ cửa sổ ngữ cảnh 1,000,000-token và có thể tạo đầu ra dài (ghi chú công bố cho biết giới hạn đầu ra ở mức rất lớn, phù hợp các nhiệm vụ dạng dài). Quy mô này phù hợp các trường hợp như phân tích toàn bộ kho mã, tài liệu nhiều chương hoặc bản chép lời dài mà không cần chia nhỏ.
“Tư duy động”: cải thiện suy luận và lập kế hoạch theo từng bước
Google mô tả 3.1 Pro có “tư duy” cải thiện — tức là xử lý chuỗi suy luận nội bộ tốt hơn và chọn động chiến lược suy luận tùy theo độ phức tạp của tác vụ. Mô hình được tinh chỉnh để kích hoạt lập kế hoạch nhiều bước khi cần, đồng thời tiết kiệm token. Trên thực tế, điều này chuyển hóa thành ít ảo giác hơn cho các vấn đề nhiều bước phức tạp và nhất quán thực tế hơn trên các điểm chuẩn suy luận nhiều bước.
Quy trình tác nhân & sử dụng công cụ
Trọng tâm thiết kế lớn của 3.1 Pro là hiệu năng tác nhân: phối hợp công cụ, gọi neo web hoặc tìm kiếm, viết và thực thi đoạn mã, và kiểm chứng đầu ra qua các lượt rà soát thứ cấp. Google đã tích hợp 3.1 Pro vào các sản phẩm ưu tiên tác nhân (ví dụ: môi trường phát triển Antigravity) để cho phép mô hình chạy tác vụ liên quan đến trình soạn thảo, terminal và trình duyệt — và ghi lại hiện vật như ảnh chụp màn hình và bản ghi duyệt web để xác thực tiến độ. Những tính năng này nhằm thu hẹp khoảng cách giữa mô hình “đưa lời khuyên” và mô hình thật sự thực hiện quy trình đa công cụ một cách đáng tin cậy.
Chế độ chuyên biệt (Deep Research, Deep Think)
Google ghép 3.1 Pro với “Deep Research” và đề cập biến thể “Deep Think” sẽ ra mắt. Các chế độ phụ này lần lượt nhắm tới — các tác vụ nghiên cứu ưu tiên truy hồi cao và độ sâu suy luận tối đa (đổi lại chi phí tính toán và độ trễ cao hơn). Chúng phục vụ nhà phân tích, nhà nghiên cứu và nhà phát triển cần đầu ra cẩn trọng, chất lượng cao hơn thay vì phản hồi nhanh nhất, rẻ nhất.
Gemini 3.1 Pro thể hiện thế nào trên các điểm chuẩn?
Gemini 3.1 Pro đạt mức tăng mạnh so với Gemini 3 Pro trước đó, thường dẫn đầu trên tập rộng các thước đo suy luận nhiều bước và đa phương thức — nhưng tụt sau một số đối thủ ở các tác vụ chuyên biệt (đáng chú ý là một số bài mã hóa nâng cao hoặc bộ câu hỏi trình độ chuyên gia). Tóm lại: cải thiện rộng khắp với những khoảng đối thủ nhỉnh hơn ở các điểm chuẩn chuyên môn hẹp.
Các tuyên bố điểm chuẩn và con số tiêu đề
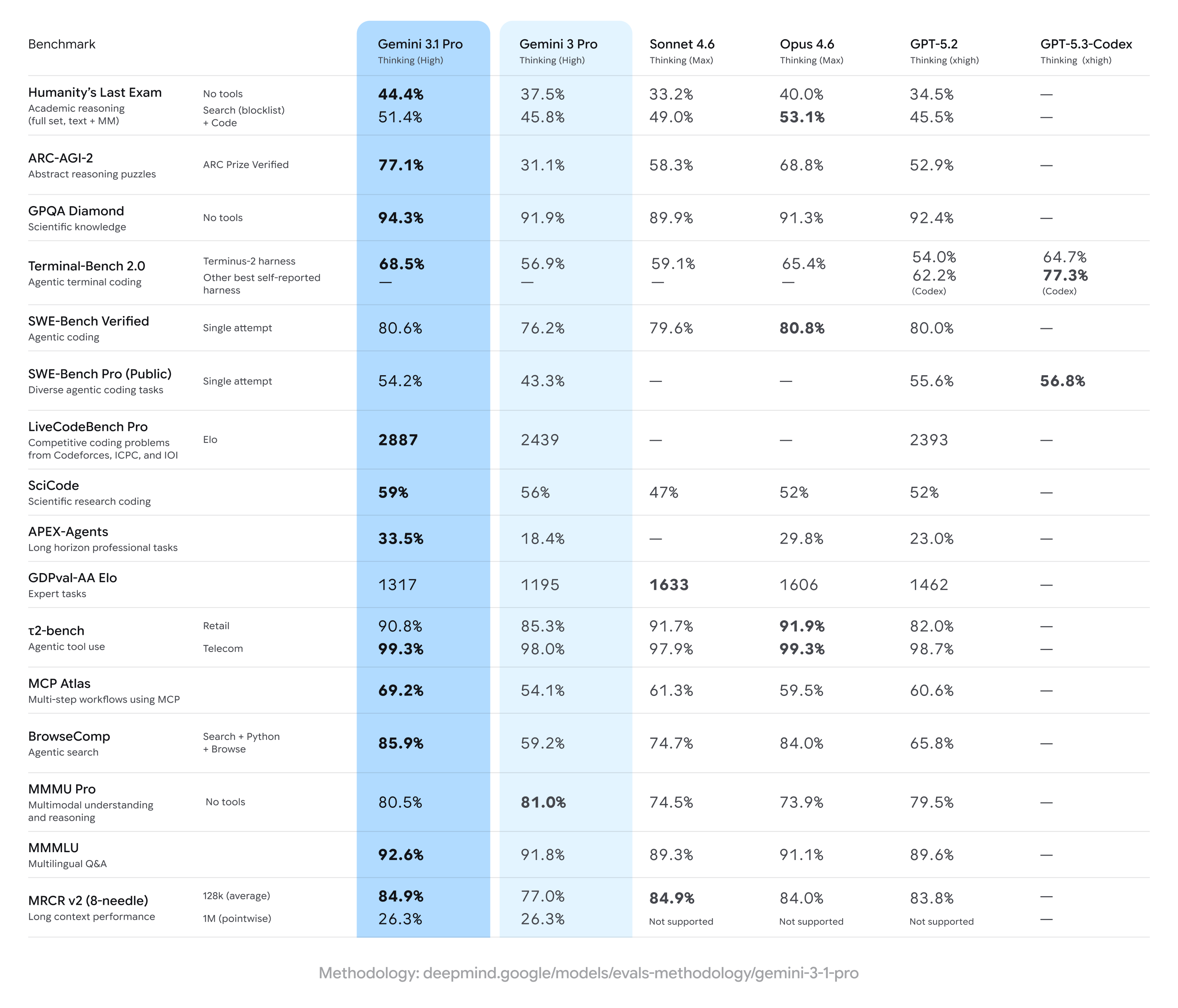
- ARC-AGI-2 (suy luận trừu tượng / câu đố khoa học nhiều bước): Các mức tăng được báo cáo cho Gemini 3.1 Pro cho thấy cải thiện đáng kể so với các phiên bản Gemini 3 Pro trước; một bộ thử nghiệm cộng đồng cho thấy mức cải thiện hơn gấp đôi trên ARC-AGI-2 so với đường cơ sở Gemini 3 Pro trước đó trong các bài thử ngắn, tập trung. Điểm số cụ thể được báo cáo (thử nghiệm cộng đồng) đặt Gemini 3.1 Pro ở mức khoảng 77.1% trên một số phép tổng hợp kiểu ARC (báo cáo công khai).
- GPQA Diamond và các điểm chuẩn khoa học bậc sau đại học: Các báo cáo dữ liệu cho thấy Gemini 3.1 Pro đạt mức cao kỷ lục trên GPQA Diamond (điểm chuẩn Hỏi-Đáp khoa học trình độ sau đại học), vượt các mô hình Gemini trước và thiết lập mốc cao mới cho gia đình này trong các lần chạy độc lập. Những mức tăng này phản ánh tinh chỉnh chuỗi suy luận và lập luận theo từng bước được cải thiện của mô hình.
- “Humanity’s Last Exam” với công cụ bật (suy luận có neo, đa công cụ): Trong so sánh trực tiếp với Claude Opus 4.6 của Anthropic, Claude đạt 53.1% trên điểm chuẩn phức tạp có bật công cụ này trong khi Gemini 3.1 Pro đạt 51.4% trong cùng vòng thử — cho thấy Gemini bám sát nhưng chưa dẫn đầu ở bài thi đa công cụ cụ thể đó.
- Điểm chuẩn mã hóa & terminal (Terminal-Bench 2.0, SWE-Bench Pro): Các điểm chuẩn lập trình chuyên biệt cho thấy sự khác biệt lớn hơn. Trên Terminal-Bench 2.0 với các harness cụ thể, các biến thể GPT-5.3-Codex đạt khoảng 77.3% so với ~68.5% của Gemini 3.1 Pro trong cùng phép so sánh. Trên kết quả công khai SWE-Bench Pro, Gemini 3.1 Pro đạt khoảng 54.2% so với 56.8% của GPT-5.3-Codex — sát hơn, nhưng họ Codex của OpenAI vẫn nhỉnh hơn trên các tác vụ lập trình chuyên biệt trong các lần chạy đó.
- GDPval-AA Elo (xếp hạng nhiệm vụ chuyên gia): Trong xếp hạng tổng hợp kiểu Elo cho nhiệm vụ chuyên gia, các biến thể Claude Sonnet/Opus đạt điểm cao hơn (ví dụ, khoảng 1606–1633 điểm) trong khi một báo cáo công khai đặt Gemini 3.1 Pro ở khoảng 1317 điểm trên cùng bộ dữ liệu — cho thấy còn dư địa cải thiện ở một số miền chuyên môn hẹp.
Kết quả thử nghiệm thực tế và đánh giá trực tiếp
Các bài viết đánh giá cho thấy Gemini 3.1 Pro đặc biệt xuất sắc ở:
- Tóm tắt ngữ cảnh dài và tổng hợp đa tài liệu, nơi cửa sổ 1M token tránh được các lỗi do chia khối.
- Nhiệm vụ hiểu đa phương thức nơi việc neo hình ảnh + văn bản cải thiện trích xuất thực tế.
- Tự động hóa theo hướng tác nhân (ví dụ: phối hợp các chuỗi công cụ đơn giản) — các thử nghiệm với Antigravity chứng minh việc điều phối tác vụ đa tác nhân là khả thi với hiện vật ghi lại từng bước.
Nơi Gemini 3.1 Pro còn hụt hơi (theo con số)
Không mô hình nào tốt nhất ở mọi mặt. Bình luận độc lập và thử nghiệm cộng đồng nêu bật các khoảng trống cụ thể:
- Các điểm chuẩn kỹ nghệ phần mềm và bảo trì mã (SWE-Bench Pro và tương tự) — Gemini 3.1 Pro kém hơn một đối thủ (Claude Opus 4.6 của Anthropic) ở các tác vụ kiểm tra năng lực kỹ nghệ phần mềm thực tế: tái cấu trúc quy mô lớn, phân loại lỗi trong codebase lộn xộn và một số dạng sửa chữa chương trình tự động. Nói cách khác, cho công việc bảo trì kỹ thuật thường ngày, các mô hình chuyên biệt vẫn giữ lợi thế ở một số testbed.
- Các vi tác vụ nhạy trễ — vì Gemini 3.1 Pro được tinh chỉnh cho độ sâu, các tác vụ đòi hỏi độ trễ cực thấp và thông lượng cao (ví dụ: suy luận vi mô cho UI hội thoại nhẹ) có thể phù hợp hơn với “Flash” hoặc các biến thể tối ưu khác trong họ Gemini.
Giá của Gemini 3.1 Pro là bao nhiêu?
Bạn có thể truy cập Gemini 3.1 Pro theo hai cách — gói thuê bao người dùng cuối hoặc API dành cho nhà phát triển — và mức giá khác nhau cho mỗi cách.
- Người dùng (ứng dụng Gemini / Google AI Pro): Truy cập Gemini 3.1 Pro được bao gồm trong gói Google AI Pro, tại Hoa Kỳ là $19.99 / tháng (Google cũng có tầng thấp hơn “AI Plus” và tầng cao hơn “AI Ultra”). Google.
- Nhà phát triển / API (tính theo token): Nếu bạn gọi các mô hình Gemini qua API nhà phát triển Gemini/AI, giá được đo theo token. Với bản xem trước Gemini 3.x Pro, giá nhà phát triển được công bố vào khoảng: $2.00 mỗi 1M token đầu vào và $12.00 mỗi 1M token đầu ra cho băng tiêu chuẩn (≤200k prompts) — với các băng cao hơn (ví dụ $4/$18 mỗi 1M) cho ngữ cảnh rất lớn. (Xem bảng giá Gemini API để biết chi tiết đầy đủ và giá theo lô.)
- Nếu bạn dùng Gemini 3.1 Pro qua CometAPI:
| Giá Comet (USD / M Tokens) | Giá chính thức (USD / M Tokens) |
|---|---|
| Đầu vào:$1.6/M; Đầu ra:$9.6/M | Đầu vào:$2/M; Đầu ra:$12/M |
Giá thuê bao người dùng (ứng dụng Gemini)
Với các gói người dùng cuối trong ứng dụng Gemini, Google cấu trúc các tầng để kiểm soát quyền truy cập vào các biến thể mô hình và tính năng bổ sung: Google AI Pro và Google AI Ultra. Giá khác nhau theo thị trường và tiền tệ; ví dụ công bố cho thấy Google AI Pro ở mức $19.99/tháng (có các ưu đãi dùng thử) và mức giá theo tiền tệ theo tầng được thể hiện trên trang sản phẩm (bao gồm ưu đãi dùng thử và giảm giá ngắn hạn). AI Ultra đi kèm quyền truy cập cao hơn (ví dụ: ưu tiên truy cập đổi mới mới, hạn mức cao hơn cho tạo video) với mức phí hàng tháng cao hơn. Các gói người dùng này cạnh tranh với các thuê bao AI cao cấp khác và hướng tới giúp người dùng mạnh hoặc nhóm nhỏ tiếp cận tính năng 3.1 Pro mà không cần tích hợp API.
Mẹo nhắc lệnh & sử dụng thực tế (tôi sẽ làm gì)
Dùng các cách sau để có kết quả đáng tin cậy, lặp lại được:
- Bộ lập kế hoạch từng bước rõ ràng
Mẫu nhắc:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.Cách này tận dụng năng lực thực thi theo bước mạnh hơn của 3.1 Pro và cung cấp các điểm kiểm soát. - Đầu ra có cấu trúc với schema
Yêu cầu JSON kèm schema vàstrict: true. Vì 3.1 Pro tạo đầu ra dài và tuân thủ schema ổn định hơn, bạn sẽ nhận được phản hồi đơn lớn hơn mà có thể phân tích downstream. - “Sandwich” kiểm tra công cụ
Khi gọi công cụ bên ngoài (API, trình chạy mã), hãy để mô hình tạo: kế hoạch → lệnh gọi công cụ chính xác (dễ copy/paste) → các bước kiểm chứng. Sau đó xác minh các bước kiểm chứng bên ngoài mô hình trước khi tiếp tục. - Cẩn trọng với niềm tin một bước
Dù mô hình viết mã hay lệnh trông hoàn hảo, hãy chạy kiểm chứng độc lập (kiểm thử, linter, thực thi sandbox) — đặc biệt cho hành động mang tính tác nhân/tự động.
Trải nghiệm trực tiếp với Gemini 3.1 Pro
Ca thử 1: Trợ lý nghiên cứu ngữ cảnh dài (NotebookLM / Deep Research)
Mục tiêu: Đánh giá khả năng của mô hình trong việc tổng hợp 10–50 tài liệu dài (ví dụ: báo cáo, whitepaper) thành bản tóm tắt điều hành nhiều trang kèm trích dẫn và hạng mục hành động.
Thiết lập: Nạp một corpus tổng 200k–800k token; giao nhiệm vụ tạo tóm tắt 2–4 trang với trích dẫn rõ ràng và đề xuất “bước tiếp theo”. Dùng mẫu nhắc có thể lặp lại và đo thời gian, mức dùng token (chi phí) và độ chính xác thực tế.
Kết quả: Tóm tắt đầu-cuối nhanh hơn với ít lỗi do chia khối so với mô hình cũ, độ trung thực trích dẫn cao hơn trong bản tóm tắt và mạch lạc tốt hơn ở quy mô — đổi lại tiêu thụ token đáng kể (nên lập ngân sách). Điểm chuẩn và thử nghiệm thực tế cho thấy Gemini 3.1 Pro xuất sắc ở tổng hợp đa tài liệu nhờ cửa sổ 1M token.
Ca thử 2: Trợ lý mã hóa theo hướng tác nhân (Antigravity + GitHub Copilot)
Mục tiêu: Đo mức giảm thời gian hoàn thành cho nhiệm vụ nhà phát triển nhiều bước (ví dụ: triển khai tính năng qua nhiều tệp, chạy kiểm thử, sửa kiểm thử lỗi).
Thiết lập: Dùng Antigravity hoặc GitHub Copilot bản xem trước với Gemini 3.1 Pro được chọn. Định nghĩa tác vụ có thể tái lập (tạo issue → triển khai → chạy kiểm thử), ghi nhật ký bước và hiện vật tác nhân, và so sánh với đường cơ sở chỉ con người.
Kết quả: Điều phối nhiệm vụ nhiều bước được cải thiện (ghi hiện vật, đề xuất bản vá tự động), suy luận đa tệp tốt hơn so với Gemini 3 Pro trước, và tiết kiệm thời gian đo đếm được cho công việc tính năng thường nhật. Các tác vụ gỡ lỗi hệ thống mức thấp chuyên biệt có thể vẫn ưu ái các mô hình định hướng mã chuyên sâu (kết quả cộng đồng cho thấy khoảng cách so với một số biến thể GPT-Codex trên vài điểm chuẩn terminal).
Ca thử 3: Rà soát tài liệu pháp lý/y tế đa phương thức
Mục tiêu: Dùng mô hình để nạp một corpus hỗn hợp (PDF quét, hình ảnh, bản chép âm thanh), trích xuất dữ kiện chính và tạo ma trận rủi ro cùng hành động ưu tiên.
Thiết lập: Cung cấp bộ dữ liệu chứa hình ảnh quét và văn bản OCR, cộng thêm âm thanh hỗ trợ. Đo độ chính xác trích xuất thực thể có tên, tỉ lệ dương tính giả và khả năng mô hình tham chiếu hiện vật nguồn.
kết quả: Suy luận tích hợp mạnh hơn giữa các phương thức và đầu ra dễ truy vết hơn (khả năng chỉ ra ảnh/trang/dấu thời gian âm thanh hỗ trợ một khẳng định). Cửa sổ ngữ cảnh dài giảm nhu cầu chia khối và tham chiếu chéo thủ công. Tuy nhiên, trong lĩnh vực chịu điều tiết, đầu ra nên được chuyên gia thẩm định và dùng pipeline neo/kiểm chứng.
Ấn tượng đầu tiên (điều cảm nhận khác biệt)
- Suy luận theo bước sâu hơn. Các tác vụ trước đây cần nhiều vòng qua lại — ví dụ: tổng hợp đa tài liệu, toán/lôgic nhiều bước — nay thường hoàn tất trong ít lượt hơn và với đầu ra kiểu chuỗi suy luận rõ hơn (mà không lộ văn bản chỉ dẫn nội bộ). Đây là tiêu đề Google nhấn mạnh.
- Đầu ra có cấu trúc dài hơn, chất lượng cao hơn. JSON và tự động hóa dạng dài nhất quán hơn và thường dài hơn (một số người dùng báo cáo kích cỡ đầu ra lớn hơn nhiều so với 3.0). Điều đó khiến mô hình rất phù hợp các bài sinh nội dung nơi bạn muốn một payload lớn duy nhất. Hãy chuẩn bị xử lý đầu ra lớn hơn và streaming.
- Hiệu quả token/ngữ cảnh tốt hơn. Hiệu quả token cải thiện và hành vi “có neo, nhất quán thực tế” hơn cho các kịch bản dùng công cụ. Điều này thể hiện ở ít ảo giác hơn trên các truy vấn thực tế ngắn.
Phân tích cuối: Có nên áp dụng Gemini 3.1 Pro ngay bây giờ?
Gemini 3.1 Pro là bước tiến có ý nghĩa trong gia đình Gemini với các cải thiện rõ rệt trên điểm chuẩn suy luận, mã hóa và tác nhân — được hậu thuẫn bởi thẻ mô hình do Google công bố và các bộ theo dõi độc lập ghi nhận bước nhảy lớn trên một số bảng xếp hạng. Với các đội cần suy luận nâng cao, phối hợp công cụ theo hướng tác nhân hoặc năng lực đa phương thức ngữ cảnh dài, 3.1 Pro là một lựa chọn hấp dẫn.
Nhà phát triển có thể truy cập Gemini 3.1 Pro qua CometAPI ngay bây giờ. Để bắt đầu, hãy khám phá năng lực của mô hình trong Playground và tham khảo API guide để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập CometAPI và lấy API key. CometAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.
Ready to Go?→ Đăng ký Gemini 3.1 Pro ngay hôm nay!
Nếu bạn muốn biết thêm mẹo, hướng dẫn và tin tức về AI hãy theo dõi chúng tôi trên VK, X và Discord!