

Vào ngày 3 tháng 3 năm 2026, Google đã giới thiệu Gemini 3.1 Flash-Lite, thành viên mới nhất của gia đình Gemini 3 được thiết kế đặc biệt như một động cơ thông lượng cao, độ trễ thấp và tiết kiệm chi phí cho khối lượng công việc của nhà phát triển và doanh nghiệp. Google định vị Flash-Lite là mô hình “nhanh nhất và hiệu quả chi phí nhất” trong dòng Gemini 3: một biến thể gọn nhẹ nhằm cung cấp tương tác dạng streaming, xử lý nền quy mô lớn và các tác vụ sản xuất tần suất cao (ví dụ: dịch, trích xuất, tạo UI và phân loại khối lượng lớn) với mức giá thấp hơn nhiều so với các phiên bản Pro.
Dưới đây là phân tích về Flash-Lite.
Gemini 3.1 Flash-Lite là gì
Gemini 3.1 Flash-Lite là một thành viên của gia đình Gemini 3, chủ động đánh đổi một phần chiều sâu suy luận cấp cao nhất để lấy tốc độ và hiệu quả chi phí. Nó là mô hình đa phương thức gốc trong dòng Gemini (có thể nhận văn bản, hình ảnh và các dạng đầu vào khác), nhưng được tinh chỉnh và triển khai đặc biệt để đạt thông lượng token/giây tối đa và giảm đáng kể chi phí theo token cho các khối lượng công việc đòi hỏi suy luận nhanh, lặp lại thay vì chiều sâu nhận thức tối đa. Mô hình được mô tả là phát triển từ kiến trúc 3.1 Pro nhưng được tối ưu cho thông lượng, độ trễ và chi phí.
Các đánh đổi thiết kế chính
Cụm “Lite” báo hiệu trọng tâm kỹ thuật của mô hình:
- Ưu tiên thông lượng hơn suy luận nặng: Flash-Lite cố ý giảm lượng tính toán trên mỗi token để mang lại thời gian đến token đầu tiên (TTFT) nhanh hơn và tốc độ xuất token liên tục. Điều đó khiến nó lý tưởng cho các pipeline mà mỗi yêu cầu phải được phục vụ nhanh và ở quy mô lớn (ví dụ: bộ lọc an toàn, trợ lý thời gian thực, sinh nội dung khối lượng lớn).
- Hiệu quả chi phí cho khối lượng lớn: Bằng cách giảm tính toán trên mỗi token, mô hình có thể được cung cấp với mức giá thấp hơn trên mỗi triệu token, từ đó giảm chi phí cận biên trong các ứng dụng quy mô lớn (ví dụ: hàng triệu đến hàng tỷ token mỗi tháng). Bảng giá preview của Google cho thấy chênh lệch đáng kể so với tier Pro.
- Chất lượng được tinh chỉnh cho các tác vụ thực dụng: Theo các tóm tắt chấm điểm ban đầu, Flash-Lite duy trì kết quả mạnh trên các tác vụ phân loại tiêu chuẩn, đa ngôn ngữ và nhiều tác vụ đa phương thức, nhưng không được định vị để vượt Pro ở các bài kiểm thử sinh mã hoặc suy luận đa bước phức tạp nơi chiều sâu là yếu tố quyết định.
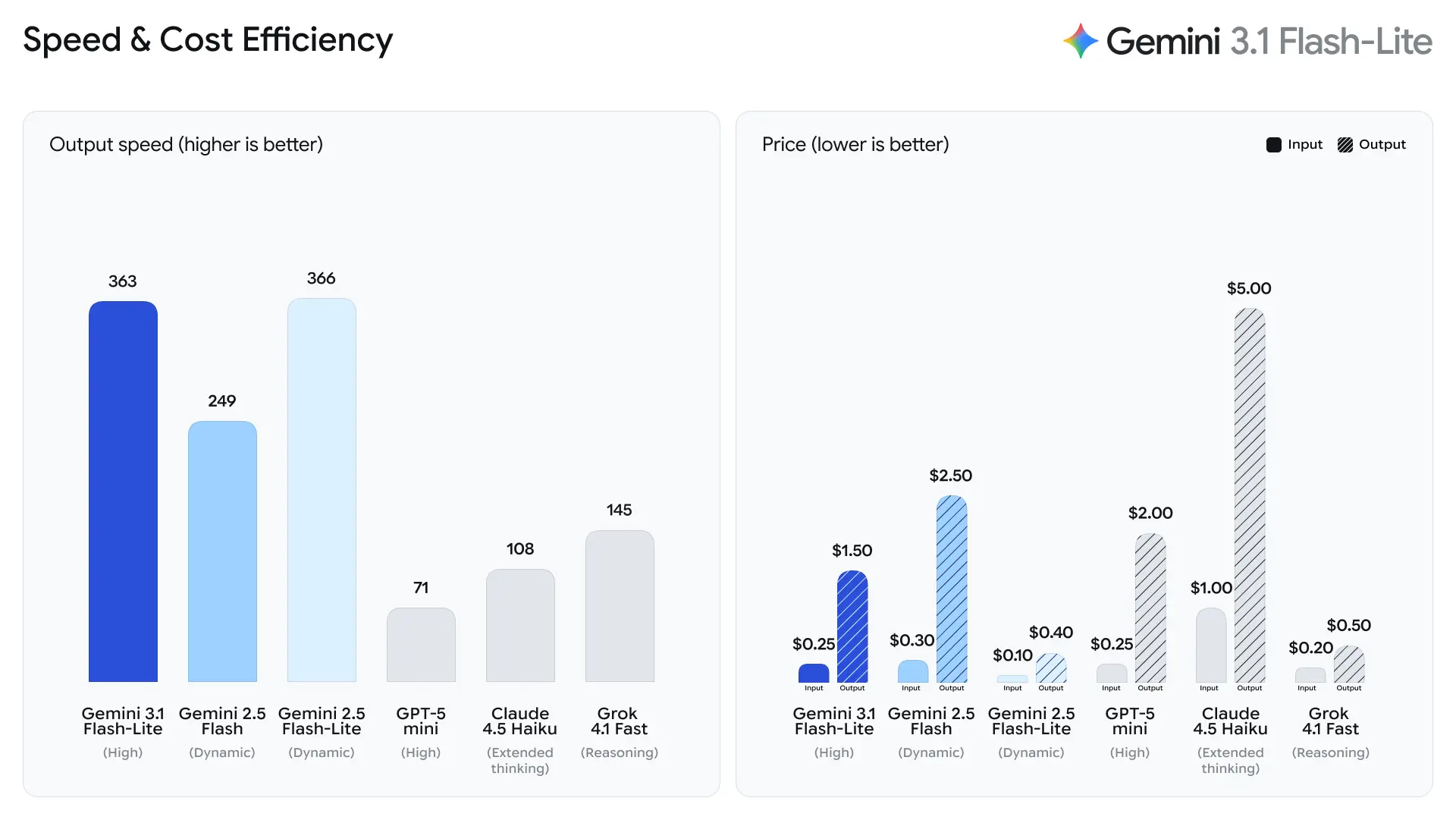
Những khối công việc này yêu cầu đầu ra tin cậy và thông lượng cao, nhưng không phải lúc nào cũng cần năng lực suy luận đa bước phức tạp của các mô hình đầu bảng.
Các tính năng chính của Gemini 3.1 Flash-Lite
1. Độ trễ thấp và thời gian ra token đầu tiên nhanh
Google nhấn mạnh thời gian đến token trả lời đầu tiên như một chỉ số chính đối với Flash-Lite. Công ty báo cáo nhanh hơn ~2,5× về thời gian đến token đầu tiên so với Gemini 2.5 Flash và nhanh hơn tới 45% về tốc độ sinh đầu ra — những cải thiện tác động trực tiếp đến cảm nhận phản hồi của người dùng cuối và chi phí thông lượng cho hệ thống backend. Những lợi ích này khiến Flash-Lite phù hợp với các tính năng tương tác (ví dụ: chatbot nhúng trong ứng dụng) và các pipeline QPS cao nơi từng micro‑giây đều quan trọng.
Sự cải thiện này tăng cường đáng kể cho các ứng dụng thời gian thực như:
- AI hội thoại
- trợ lý tìm kiếm hỗ trợ AI
- chatbot tương tác
- dịch trực tiếp
Độ trễ thấp hơn cải thiện trải nghiệm người dùng bằng cách rút ngắn thời gian chờ và cho phép tương tác mượt mà hơn.
2. Giá theo token tiết kiệm chi phí
Chi phí suy luận AI thường được tính theo mỗi token, vì vậy giá là yếu tố quan trọng cho các triển khai quy mô lớn.
Gemini 3.1 Flash-Lite giới thiệu cấu trúc giá rất cạnh tranh:
| Loại token | Giá |
|---|---|
| Token đầu vào | $0.25 per 1M tokens |
| Token đầu ra | $1.50 per 1M tokens |
Đây là mức giảm so với các mẫu Flash trước đây, giúp mô hình hấp dẫn với các tổ chức vận hành khối lượng công việc lớn.
So sánh:
| Mô hình | Giá đầu vào | Giá đầu ra |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Chiến lược giá này cho phép nhà phát triển vận hành AI ở quy mô lớn mà không làm tăng mạnh chi phí vận hành.
Nếu bạn đang tìm mức giá tốt hơn nữa, thì Gemini Flash-Lite cung cấp chiết khấu 20% trên CometAPI.
3. “Thinking levels” (độ sâu suy luận có thể điều khiển)
Gemini 3.1 Flash-Lite bao gồm khả năng “thinking levels” — một núm cấu hình cho nhà phát triển để hướng mô hình ưu tiên xử lý nhanh, nông cho tác vụ đơn giản và suy luận sâu hơn cho tác vụ khó. Điều này quan trọng trong thực tế vì nó cho phép đánh đổi động giữa chi phí/độ trễ theo từng yêu cầu mà không cần chuyển mô hình.
Nhà phát triển có thể cấu hình độ sâu suy luận của mô hình phù hợp với độ phức tạp của tác vụ. Thinking levels: Hỗ trợ bốn mức: Tối thiểu, Thấp, Trung bình và Cao.
Cách tiếp cận động này cho phép ứng dụng tối ưu sử dụng tài nguyên đồng thời duy trì chất lượng ở nơi cần thiết. Chiến lược thực tiễn xấp xỉ như sau:
- Tối thiểu/Thấp: Phù hợp cho các tác vụ đồng thời cao nhưng logic đơn giản như dịch, phân loại và phân tích cảm xúc, ưu tiên tốc độ tối đa và chi phí tối thiểu.
- Trung bình: Phù hợp cho hầu hết tác vụ sản xuất, cân bằng giữa chất lượng và hiệu quả.
- Cao: Phù hợp cho các tác vụ đòi hỏi suy luận sâu, như tạo giao diện người dùng, tạo mô phỏng và thực thi hướng dẫn phức tạp.
4. Năng lực đa phương thức với “dấu chân” gọn nhẹ
Dù Flash-Lite được tối ưu cho tốc độ và chi phí, nó vẫn giữ nền tảng đa phương thức của dòng Gemini 3: có thể nhận đầu vào hình ảnh để phân loại hoặc suy luận đa phương thức nhẹ khi cần — nhưng nhà phát triển nên kỳ vọng thiết kế tiết kiệm sẽ ưu tiên các thao tác đa phương thức ngắn, có giới hạn hơn là các quy trình nặng về hình ảnh rất lớn. Giống các mô hình Gemini khác, Gemini 3.1 Flash-Lite hỗ trợ đầu vào đa phương thức, cho phép xử lý nhiều loại dữ liệu.
Đầu vào được hỗ trợ gồm:
- Văn bản
- Hình ảnh
- Video
- Âm thanh
Khả năng phân tích nhiều loại thông tin của mô hình mở ra các trường hợp sử dụng mới, như:
- xử lý tài liệu tự động
- trích xuất dữ liệu trực quan
- tóm tắt đa phương tiện
Các mô hình Gemini trước đó cũng cho thấy năng lực suy luận đa phương thức mạnh trên các chuẩn đánh giá về thị giác và tri thức.
Chuẩn hiệu năng — con số thực tế và ý nghĩa
Thông báo và tài liệu sản phẩm của Google đưa ra nhiều dữ liệu benchmark nhằm giúp người mua hiểu vị trí của Flash-Lite trong hệ sinh thái.
Chỉ số tốc độ hướng tới nhà phát triển
- TTFT nhanh hơn 2,5× so với Gemini 2.5 Flash (so sánh nội bộ do Google công bố).
- Tốc độ sinh đầu ra nhanh hơn 45% so với Gemini 2.5 Flash.
Đây là các chỉ số kỹ thuật hiệu năng hơn là chỉ số chất lượng do con người đánh giá; chúng phản ánh cải tiến trong vi kiến trúc runtime, batching và tối ưu hóa ngăn xếp suy luận giúp giảm độ trễ cho câu trả lời ngắn. Thời gian đến token đầu tiên nhanh hơn giúp giảm độ trễ cảm nhận trong ứng dụng tương tác và tăng thông lượng trên mỗi máy chủ, từ đó có thể giảm tổng chi phí tính toán cho cùng mức QPS.
Số token mỗi giây (t/s) và thông lượng
Theo dữ liệu thử nghiệm của Artificial Analysis, 3.1 Flash-Lite đạt tốc độ đầu ra 388.8 token mỗi giây (trong khi trung vị của các mô hình cùng tầm giá chỉ 96.7 token/giây). Tốc độ này thuộc hàng đầu trong phân khúc.
Tuy nhiên, Artificial Analysis cũng chỉ ra một vấn đề: độ trễ token đầu tiên (TTFT) của 3.1 Flash-Lite là 5.18 giây, tương đối cao so với các mô hình suy luận cùng tầm giá (trung vị là 1.82 giây). Ngoài ra, mô hình đã tạo ra 53 triệu token trong quá trình đánh giá, cao hơn đáng kể so với mức trung bình 20 triệu. Điều này có nghĩa là nếu kịch bản của bạn rất nhạy với độ trễ token đầu tiên hoặc có yêu cầu nghiêm ngặt về độ súc tích của đầu ra, bạn có thể cần tối ưu mức tư duy và prompt.
Điểm benchmark về suy luận và tính xác thực
Google đưa vào các so sánh chéo mô hình cho thấy Gemini 3.1 Flash-Lite thể hiện mạnh mẽ so với các đối thủ và các biến thể Gemini trước đó trên các tác vụ tổng hợp về suy luận/tính xác thực:
- Điểm Elo của Arena.ai: Gemini 3.1 Flash-Lite được báo cáo đạt Elo 1432 trên bảng xếp hạng Arena — một xếp hạng đối đầu tổng hợp cho thấy hiệu năng tương đối cạnh tranh trong các kịch bản so kè trực tiếp.
- GPQA Diamond: 86.9% (thước đo độ vững của hỏi đáp).
- MMMU Pro: 76.8% (một chỉ số đa phương thức/đa nhiệm được dùng nội bộ/bên ngoài bởi một số phòng lab).
- LiveCodeBench (Khả năng lập trình): 72.0%
- CharXiv Reasoning (Suy luận đồ họa): 73.2%
- Video-MMMU (Hiểu video): 84.8%
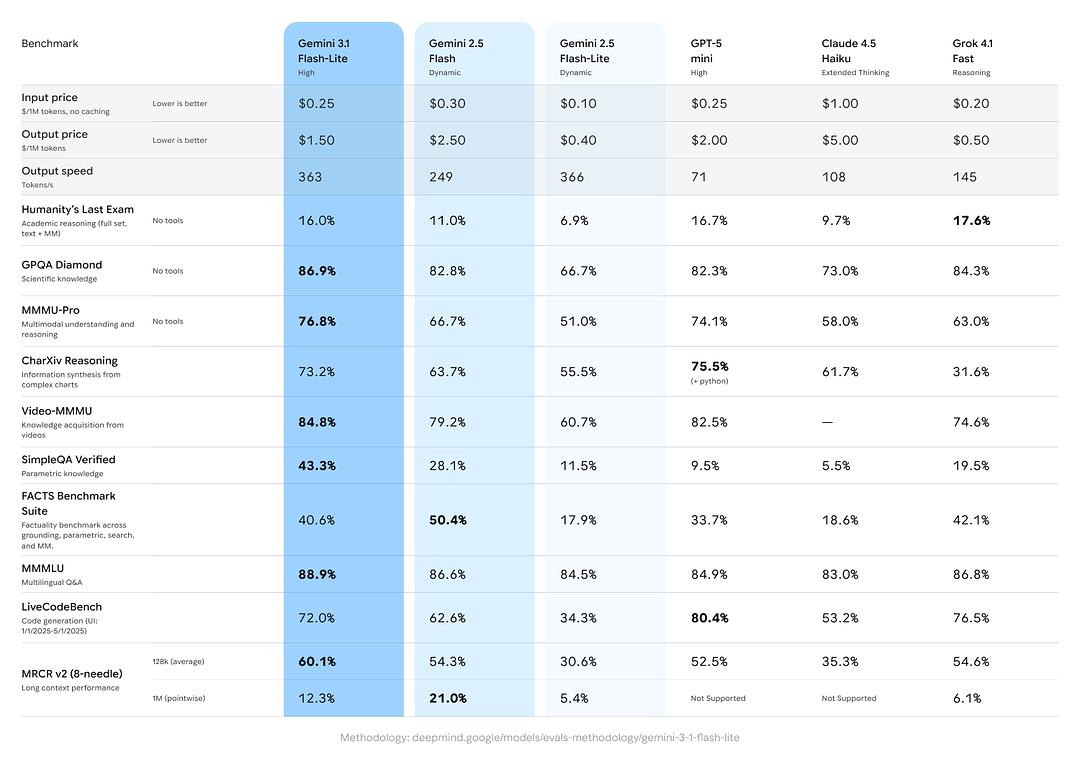
Gemini 3.1 Flash-Lite vượt Gemini 2.5 Flash cũ ở một số chỉ số này trong khi vẫn mang lại tốc độ/chi phí tốt hơn nhiều.
Trường hợp sử dụng phù hợp với Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite được thiết kế xoay quanh một tập hợp rõ ràng các khối lượng công việc thực tế, nơi thông lượng cao và chi phí thấp trên mỗi token là yếu tố quyết định:
Tác nhân hội thoại tần suất cao và UI streaming
Chatbot thời gian thực, luồng phiên âm + dịch trực tiếp và các UI cộng tác hiển thị câu trả lời từng phần khi mô hình sinh ra sẽ hưởng lợi từ khả năng streaming token và thời gian đến token đầu tiên thấp của Flash-Lite.
Xử lý dữ liệu hàng loạt (RAG, pipeline chuyển đổi)
Nạp tài liệu quy mô lớn: trích xuất thực thể, gắn thẻ metadata, phân loại và dịch trên hàng triệu tài liệu — Gemini 3.1 Flash-Lite giảm chi phí suy luận đồng thời cung cấp độ chính xác chấp nhận được cho các đầu ra theo mẫu hoặc theo quy tắc.
Tính toán kiểu edge/ở nền
Các khối lượng công việc xử lý liên tục dữ liệu telemetry đến hoặc dữ liệu phi cấu trúc (ví dụ: pipeline phân loại kiểm duyệt nội dung, tạo báo cáo tự động) rất phù hợp vì Gemini 3.1 Flash-Lite tối thiểu hóa chi phí trên mỗi đơn vị.
Công cụ cho nhà phát triển và hoàn thành mã theo lô
Với các tính năng như dựng khung nhiều tệp, linting mã quy mô lớn và tạo template hàng loạt, lợi thế tốc độ của Gemini 3.1 Flash-Lite giúp giảm độ trễ và chi phí cho công cụ trải nghiệm nhà phát triển nơi không cần chiều sâu suy luận tối đa tuyệt đối.
So sánh Gemini 3.1 Flash-Lite với các mô hình Gemini khác và đối thủ
Trong hệ Gemini
- Gemini 3.1 Pro: năng lực cao nhất ở suy luận phức tạp và lập kế hoạch đa bước; đắt và chậm hơn nhiều trên mỗi token nhưng tốt hơn cho các tác vụ sâu, tinh tế.
- Gemini 3.1 Flash (không phải Lite): nhắm tới điểm cân bằng giữa thông lượng thô và năng lực — Flash-Lite tối ưu sâu hơn xuống ngăn xếp tính toán cho thông lượng.
So với các mô hình “nhanh” cạnh tranh
Gemini 3.1 Flash-Lite vượt hoặc sánh ngang nhiều mô hình nhanh/mini ở nhiều chỉ số về thông lượng và chất lượng — tuy vậy các nhà phân tích độc lập cảnh báo rằng so sánh đối đầu trực tiếp nhạy với phương pháp đánh giá và lựa chọn dữ liệu. Kỳ vọng Gemini 3.1 Flash-Lite sẽ rất cạnh tranh về thông lượng và chi phí trong khi nằm gần nhóm giữa ở các chỉ số suy luận cao nhất.
Kết luận — vị trí của Flash-Lite trong ngăn xếp AI
Gemini 3.1 Flash-Lite là một sản phẩm được thiết kế có chủ đích: thành viên tập trung vào hiệu quả và thông lượng của gia đình Gemini 3 cho phép các đội ngũ đánh đổi một phần tính toán trên mỗi mẫu để nhận lại cải thiện lớn về độ trễ và chi phí. Với doanh nghiệp và nhà phát triển xây dựng các pipeline khối lượng lớn — dịch, xử lý theo lô, UI streaming và các tác vụ tác tử phức tạp vừa phải — Flash-Lite là một động cơ chuẩn hợp lý. Với tổ chức cần độ trung thực suy luận cao nhất, các mô hình Pro vẫn là lựa chọn phù hợp.
Nếu khối lượng công việc của bạn chủ yếu gồm nhiều suy luận ngắn, lặp lại hoặc cần đầu ra streaming nhanh ở quy mô lớn, Flash-Lite rất đáng để thử nghiệm. Nếu công việc dựa nhiều vào suy luận đa bước sâu, hãy lên kế hoạch tiếp cận lai: định tuyến lưu lượng thông lượng sang Flash-Lite và nâng cấp các truy vấn phức tạp, giá trị cao lên mô hình Pro.
Nhà phát triển có thể truy cập Gemini 3.1 Flash Lite thông qua CometAPI ngay bây giờ. Để bắt đầu, hãy khám phá khả năng của mô hình trong Playground và tham khảo API guide để có hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập CometAPI và lấy API key. CometAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.
Sẵn sàng bắt đầu?→ Sign up fo Gemini 3.1 Flash lite today
Nếu bạn muốn biết thêm mẹo, hướng dẫn và tin tức về AI, hãy theo dõi chúng tôi trên VK, X và Discord!