

Vào ngày 17 tháng XNUMX, kỳ lân AI Thượng Hải MiniMax chính thức mở nguồn MiniMax-M1, mô hình suy luận hybrid-attention quy mô lớn có trọng lượng mở đầu tiên trên thế giới. Bằng cách kết hợp kiến trúc Mixture-of-Experts (MoE) với cơ chế Lightning Attention mới, MiniMax‑M1 mang lại những cải tiến lớn về tốc độ suy luận, xử lý ngữ cảnh cực dài và hiệu suất tác vụ phức tạp.
Bối cảnh và sự tiến hóa
Xây dựng trên nền tảng của MiniMax-Văn bản-01, giới thiệu sự chú ý chớp nhoáng trên khuôn khổ Hỗn hợp chuyên gia (MoE) để đạt được 1 triệu ngữ cảnh mã thông báo trong quá trình đào tạo và lên đến 4 triệu mã thông báo khi suy luận, MiniMax-M1 đại diện cho thế hệ tiếp theo của dòng MiniMax-01. Mô hình tiền nhiệm, MiniMax-Text-01, chứa 456 tỷ tham số tổng cộng với 45.9 tỷ được kích hoạt trên mỗi mã thông báo, chứng minh hiệu suất ngang bằng với các LLM hàng đầu trong khi mở rộng đáng kể khả năng ngữ cảnh.
Các tính năng chính của MiniMax‑M1
- MoE lai + Chú ý chớp nhoáng: MiniMax‑M1 kết hợp thiết kế Hỗn hợp chuyên gia thưa thớt—tổng cộng 456 tỷ tham số, nhưng chỉ có 45.9 tỷ được kích hoạt cho mỗi mã thông báo—với Lightning Attention, một sự chú ý phức tạp tuyến tính được tối ưu hóa cho các chuỗi rất dài.
- Bối cảnh siêu dài: Hỗ trợ lên đến 1 triệu mã thông báo đầu vào—gấp khoảng tám lần giới hạn 128 K của DeepSeek‑R1—cho phép hiểu sâu các tài liệu khổng lồ.
- Hiệu quả vượt trội:Khi tạo 100 nghìn mã thông báo, Lightning Attention của MiniMax‑M1 chỉ cần khoảng 25–30% khả năng tính toán được DeepSeek‑R1 sử dụng.
Các biến thể mô hình
- MiniMax‑M1‑40K: 1 M ngữ cảnh mã thông báo, 40 K ngân sách suy luận mã thông báo
- MiniMax‑M1‑80K: 1 M ngữ cảnh mã thông báo, 80 K ngân sách suy luận mã thông báo
Trong các tình huống sử dụng công cụ TAU-bench, biến thể 40K vượt trội hơn tất cả các mô hình trọng số mở—bao gồm cả Gemini 2.5 Pro—thể hiện khả năng tác nhân của nó.
Chi phí đào tạo và thiết lập
MiniMax-M1 được đào tạo từ đầu đến cuối bằng cách sử dụng học tăng cường (RL) quy mô lớn trên nhiều tác vụ khác nhau—từ lý luận toán học nâng cao đến môi trường kỹ thuật phần mềm dựa trên hộp cát. Một thuật toán mới, CISPO (Clipped Importance Sampling for Policy Optimization), tăng cường hiệu quả đào tạo hơn nữa bằng cách cắt giảm trọng số lấy mẫu quan trọng thay vì cập nhật cấp mã thông báo. Cách tiếp cận này, kết hợp với sự chú ý chớp nhoáng của mô hình, cho phép đào tạo RL đầy đủ trên 512 GPU H800 hoàn thành chỉ trong ba tuần với tổng chi phí thuê là $534,700.
Tính sẵn có và giá cả
MiniMax-M1 được phát hành theo Apache 2.0 giấy phép nguồn mở và có thể truy cập ngay lập tức thông qua:
- Kho GitHub, bao gồm trọng số mô hình, tập lệnh đào tạo và điểm chuẩn đánh giá.
- Đám mây Silicon lưu trữ, cung cấp hai biến thể—40 K‑token (“M1‑40K”) và 80 K‑token (“M1‑80K”)—với kế hoạch cho phép kênh 1 M token đầy đủ.
- Giá hiện tại được thiết lập ở mức ¥4 cho một triệu mã thông báo cho đầu vào và ¥16 cho một triệu mã thông báo cho đầu ra, với chiết khấu theo khối lượng dành cho khách hàng doanh nghiệp.
Các nhà phát triển và tổ chức có thể tích hợp MiniMax-M1 thông qua API tiêu chuẩn, tinh chỉnh dữ liệu cụ thể theo miền hoặc triển khai tại chỗ cho khối lượng công việc nhạy cảm.
Hiệu suất cấp độ nhiệm vụ
| Thể loại nhiệm vụ | Đánh dấu | Hiệu suất tương đối |
|---|---|---|
| Toán học & Logic | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; gần nguồn đóng |
| Hiểu ngữ cảnh dài | Ruler (4 K–1 M token): Cấp cao ổn định | Vượt trội hơn GPT‑4 với độ dài mã thông báo vượt quá 128 K |
| Kỹ thuật phần mềm | SWE‑bench (lỗi GitHub thực tế): 56% | Tốt nhất trong số các mô hình mở; Thứ 2 sau mô hình đóng hàng đầu |
| Sử dụng tác nhân và công cụ | TAU-bench (mô phỏng API) | 62–63.5% so với Song Tử 2.5, Claude 4 |
| Đối thoại & Trợ lý | Nhiều thử thách: 44.7% | Phù hợp với Claude 4, DeepSeek‑R1 |
| QA thực tế | Đơn giản QA: 18.5% | Khu vực cần cải thiện trong tương lai |
Lưu ý: tỷ lệ phần trăm và điểm chuẩn từ thông báo chính thức của MiniMax và các báo cáo tin tức độc lập
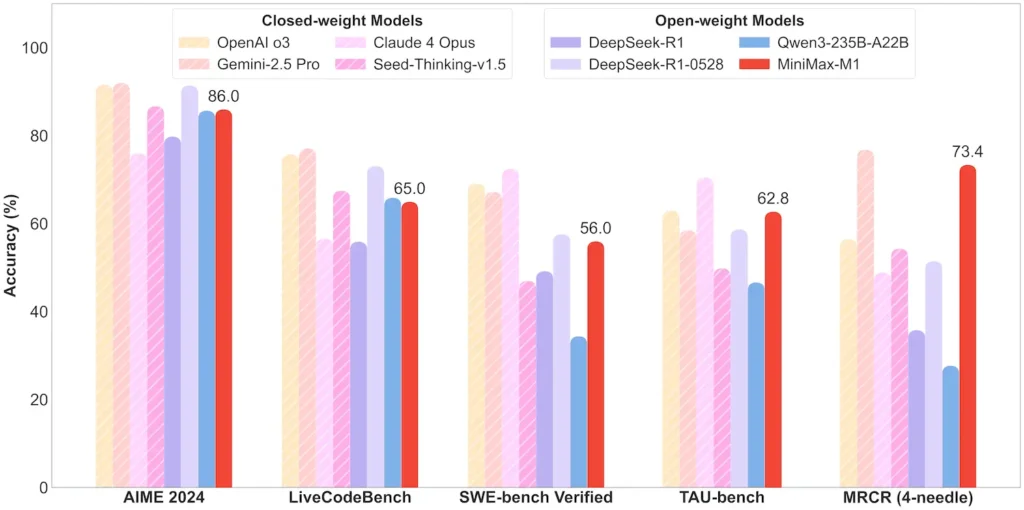
Đổi mới kỹ thuật
- Hybrid Attention Stack: Chú ý sét các lớp (chi phí tuyến tính) xen kẽ với Softmax Attention tuần hoàn (bậc hai nhưng biểu cảm hơn) để cân bằng hiệu quả và sức mạnh mô hình.
- Tuyến đường MoE thưa thớt: 32 mô-đun chuyên gia; mỗi mã thông báo chỉ kích hoạt ~10% tổng số tham số, giúp giảm chi phí suy luận trong khi vẫn duy trì dung lượng.
- Học tăng cường CISPO: Thuật toán “Tối ưu hóa chính sách trọng số IS đã cắt” mới giữ lại các mã thông báo hiếm nhưng quan trọng trong tín hiệu học, giúp tăng tốc độ và độ ổn định của RL.
Phiên bản mở của MiniMax‑M1 mở ra khả năng suy luận ngữ cảnh cực dài, hiệu quả cao cho mọi người—thu hẹp khoảng cách giữa nghiên cứu và AI quy mô lớn có thể triển khai.
Bắt đầu
CometAPI cung cấp giao diện REST thống nhất tổng hợp hàng trăm mô hình AI—bao gồm cả họ ChatGPT—dưới một điểm cuối nhất quán, với quản lý khóa API tích hợp, hạn ngạch sử dụng và bảng điều khiển thanh toán. Thay vì phải xử lý nhiều URL và thông tin xác thực của nhà cung cấp.
Để bắt đầu, hãy khám phá khả năng của các mô hình trong Sân chơi và tham khảo ý kiến Hướng dẫn API để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập vào CometAPI và lấy được khóa API.
API MiniMax‑M1 tích hợp mới nhất sẽ sớm xuất hiện trên CometAPI, vì vậy hãy theo dõi! Trong khi chúng tôi hoàn thiện việc tải lên Mô hình MiniMax‑M1, hãy khám phá các mô hình khác của chúng tôi trên Trang mô hình hoặc thử chúng trong sân chơi trí tuệ nhân tạo. Mô hình mới nhất của MiniMax trong CometAPI là Minimax ABAB7-API xem trước và API MiniMax Video-01 ,tham khảo:
