

Vào ngày 19–20 tháng 11 năm 2025, OpenAI đã phát hành hai bản nâng cấp có liên quan nhưng khác biệt: GPT-5.1-Codex-Max, một mô hình lập trình tác tử mới cho Codex nhấn mạnh vào lập trình đường dài, hiệu quả token và “compaction” để duy trì các phiên nhiều cửa sổ; và GPT-5.1 Pro, một mô hình ChatGPT cấp Pro được cập nhật, tinh chỉnh để đưa ra các câu trả lời rõ ràng hơn và mạnh mẽ hơn cho công việc chuyên môn phức tạp.
GPT-5.1-Codex-Max là gì và nó đang cố gắng giải quyết vấn đề gì?
GPT-5.1-Codex-Max là một mô hình Codex chuyên biệt của OpenAI, được tinh chỉnh cho các quy trình lập trình đòi hỏi suy luận và thực thi bền bỉ trong thời gian dài. Trong khi các mô hình thông thường có thể gặp khó khăn với ngữ cảnh cực dài — ví dụ như tái cấu trúc nhiều tệp, các vòng lặp tác tử phức tạp hoặc các tác vụ CI/CD kéo dài — Codex-Max được thiết kế để tự động nén và quản lý trạng thái phiên qua nhiều cửa sổ ngữ cảnh, cho phép nó tiếp tục làm việc một cách nhất quán khi một dự án đơn lẻ kéo dài tới hàng nghìn (hoặc hơn) token. OpenAI định vị Codex-Max là bước tiếp theo trong việc biến các tác tử có khả năng lập trình trở nên thực sự hữu ích cho công việc kỹ thuật kéo dài.
GPT-5.1-Codex-Max là gì và nó đang cố gắng giải quyết vấn đề gì?
GPT-5.1-Codex-Max là một mô hình Codex chuyên biệt của OpenAI, được tinh chỉnh cho các quy trình lập trình đòi hỏi suy luận và thực thi bền bỉ trong thời gian dài. Trong khi các mô hình thông thường có thể gặp khó khăn với ngữ cảnh cực dài — ví dụ như tái cấu trúc nhiều tệp, các vòng lặp tác tử phức tạp hoặc các tác vụ CI/CD kéo dài — Codex-Max được thiết kế để tự động nén và quản lý trạng thái phiên qua nhiều cửa sổ ngữ cảnh, cho phép nó tiếp tục làm việc một cách nhất quán khi một dự án đơn lẻ kéo dài tới hàng nghìn (hoặc hơn) token.
OpenAI mô tả nó là “nhanh hơn, thông minh hơn và hiệu quả hơn về token ở mọi giai đoạn của vòng đời phát triển”, và nêu rõ rằng nó được dùng để thay thế GPT-5.1-Codex làm mô hình mặc định trên các bề mặt Codex.
Tóm tắt tính năng
- Compaction để duy trì tính liên tục qua nhiều cửa sổ: cắt tỉa và giữ lại ngữ cảnh quan trọng để làm việc nhất quán qua hàng triệu token và nhiều giờ. 0
- Hiệu quả token được cải thiện so với GPT-5.1-Codex: ít hơn tới ~30% thinking tokens cho mức nỗ lực suy luận tương tự trên một số benchmark mã nguồn.
- Độ bền tác tử đường dài: được quan sát nội bộ là có thể duy trì các vòng lặp tác tử kéo dài nhiều giờ/nhiều ngày (OpenAI ghi nhận các lần chạy nội bộ >24 giờ).
- Tích hợp nền tảng: hiện đã có trong Codex CLI, các tiện ích mở rộng IDE, cloud và công cụ rà soát mã; quyền truy cập API sẽ sớm ra mắt.
- Hỗ trợ môi trường Windows: OpenAI đặc biệt lưu ý rằng Windows được hỗ trợ lần đầu tiên trong các quy trình Codex, mở rộng phạm vi tiếp cận tới các nhà phát triển trong thực tế.
Nó so sánh thế nào với các sản phẩm cạnh tranh (ví dụ: GitHub Copilot, các AI lập trình khác)?
GPT-5.1-Codex-Max được định vị là một cộng tác viên tự chủ hơn, có khả năng làm việc đường dài tốt hơn so với các công cụ hoàn thành theo từng yêu cầu. Trong khi Copilot và các trợ lý tương tự vượt trội ở các phần hoàn thành ngắn hạn ngay trong trình soạn thảo, điểm mạnh của Codex-Max nằm ở việc điều phối các tác vụ nhiều bước, duy trì trạng thái nhất quán qua các phiên và xử lý các quy trình đòi hỏi lập kế hoạch, kiểm thử và lặp lại. Tuy vậy, cách tiếp cận tốt nhất đối với hầu hết các nhóm sẽ là kết hợp: dùng Codex-Max cho tự động hóa phức tạp và các tác vụ tác tử kéo dài, đồng thời dùng các trợ lý nhẹ hơn cho các phần hoàn thành ở cấp độ từng dòng.
GPT-5.1-Codex-Max hoạt động như thế nào?
“Compaction” là gì và nó cho phép công việc chạy dài như thế nào?
Một tiến bộ kỹ thuật cốt lõi là compaction—một cơ chế nội bộ cắt tỉa lịch sử phiên trong khi vẫn giữ lại các phần ngữ cảnh nổi bật để mô hình có thể tiếp tục làm việc nhất quán qua nhiều cửa sổ ngữ cảnh. Trên thực tế, điều đó có nghĩa là các phiên Codex khi tiến gần tới giới hạn ngữ cảnh sẽ được nén lại (các token cũ hơn hoặc giá trị thấp hơn sẽ được tóm tắt/giữ lại) để tác tử có một cửa sổ mới và có thể tiếp tục lặp đi lặp lại cho đến khi hoàn thành nhiệm vụ. OpenAI báo cáo các lần chạy nội bộ mà mô hình làm việc liên tục trên các tác vụ trong hơn 24 giờ.
Suy luận thích ứng và hiệu quả token
GPT-5.1-Codex-Max áp dụng các chiến lược suy luận được cải thiện giúp nó hiệu quả hơn về token: trong các benchmark nội bộ do OpenAI công bố, mô hình Max đạt hiệu năng tương đương hoặc tốt hơn GPT-5.1-Codex trong khi sử dụng ít “thinking” token hơn đáng kể—OpenAI cho biết ít hơn khoảng 30% thinking token trên SWE-bench Verified khi chạy ở cùng mức nỗ lực suy luận. Mô hình cũng giới thiệu chế độ nỗ lực suy luận “Extra High (xhigh)” cho các tác vụ không nhạy cảm với độ trễ, cho phép nó sử dụng nhiều suy luận nội bộ hơn để tạo ra đầu ra chất lượng cao hơn.
Tích hợp hệ thống và công cụ tác tử
Codex-Max đang được triển khai trong các quy trình Codex (CLI, tiện ích mở rộng IDE, cloud và các bề mặt rà soát mã) để nó có thể tương tác với các chuỗi công cụ dành cho nhà phát triển thực tế. Các tích hợp ban đầu gồm Codex CLI và các tác tử IDE (VS Code, JetBrains, v.v.), với quyền truy cập API dự kiến sẽ theo sau. Mục tiêu thiết kế không chỉ là tổng hợp mã thông minh hơn mà còn là một AI có thể chạy các quy trình nhiều bước: mở tệp, chạy kiểm thử, sửa lỗi, tái cấu trúc và chạy lại.
GPT-5.1-Codex-Max thể hiện ra sao trên benchmark và trong công việc thực tế?
Suy luận bền bỉ và các tác vụ đường dài
Các đánh giá cho thấy có những cải thiện có thể đo lường được trong suy luận bền bỉ và các tác vụ đường dài:
- Đánh giá nội bộ của OpenAI: Codex-Max có thể làm việc trên các tác vụ trong “hơn 24 giờ” trong các thí nghiệm nội bộ và việc tích hợp Codex với công cụ dành cho nhà phát triển đã làm tăng các chỉ số năng suất kỹ thuật nội bộ (ví dụ: mức sử dụng và thông lượng pull request). Đây là các tuyên bố nội bộ của OpenAI và cho thấy những cải thiện ở cấp độ tác vụ trong năng suất thực tế.
- Đánh giá độc lập (METR): báo cáo độc lập của METR đo observed 50% time horizon (một thống kê đại diện cho thời gian trung vị mà mô hình có thể duy trì nhất quán một tác vụ dài) của GPT-5.1-Codex-Max ở khoảng 2 giờ 40 phút (với khoảng tin cậy rộng), tăng từ 2 giờ 17 phút của GPT-5 trong các phép đo tương đương — một cải thiện có ý nghĩa, phù hợp với xu hướng, về tính nhất quán bền bỉ. Phương pháp luận và CI của METR nhấn mạnh tính biến thiên, nhưng kết quả này củng cố câu chuyện rằng Codex-Max cải thiện hiệu suất đường dài trong thực tế.
Benchmark mã nguồn
OpenAI báo cáo kết quả được cải thiện trên các bài đánh giá lập trình tiên tiến, đáng chú ý là SWE-bench Verified, nơi GPT-5.1-Codex-Max vượt GPT-5.1-Codex với hiệu quả token tốt hơn. Công ty nhấn mạnh rằng với cùng mức nỗ lực suy luận “medium”, mô hình Max tạo ra kết quả tốt hơn trong khi sử dụng ít hơn khoảng 30% thinking token; đối với người dùng cho phép suy luận nội bộ lâu hơn, chế độ xhigh có thể tiếp tục nâng chất lượng câu trả lời với cái giá là độ trễ.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
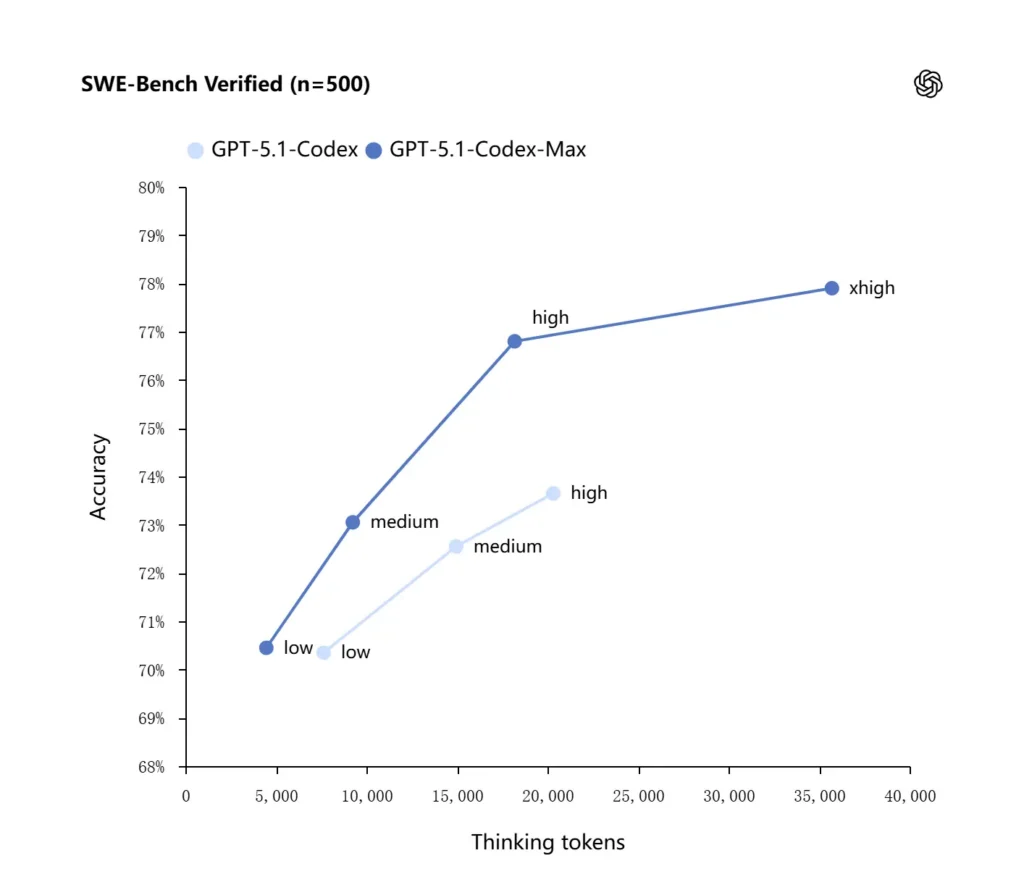
GPT-5.1-Codex-Max so với GPT-5.1-Codex như thế nào?
Khác biệt về hiệu năng và mục đích
- Phạm vi: GPT-5.1-Codex là một biến thể lập trình hiệu năng cao của họ GPT-5.1; Codex-Max rõ ràng là một phiên bản kế nhiệm có tính tác tử, hướng tới công việc đường dài và được kỳ vọng trở thành mặc định được khuyến nghị cho Codex và các môi trường kiểu Codex.
- Hiệu quả token: Codex-Max cho thấy mức cải thiện đáng kể về hiệu quả token (theo tuyên bố ít hơn ~30% thinking token của OpenAI) trên SWE-bench và trong sử dụng nội bộ.
- Quản lý ngữ cảnh: Codex-Max giới thiệu compaction và khả năng xử lý nhiều cửa sổ nguyên bản để duy trì các tác vụ vượt quá một cửa sổ ngữ cảnh đơn; Codex trước đó không cung cấp sẵn khả năng này ở cùng quy mô.
- Mức độ sẵn sàng của công cụ: Codex-Max được phát hành như mô hình Codex mặc định trên CLI, IDE và các bề mặt rà soát mã, báo hiệu một sự chuyển dịch cho các quy trình làm việc của nhà phát triển trong môi trường sản xuất.
Khi nào nên dùng mô hình nào?
- Dùng GPT-5.1-Codex cho hỗ trợ lập trình tương tác, chỉnh sửa nhanh, tái cấu trúc nhỏ và các trường hợp sử dụng độ trễ thấp nơi toàn bộ ngữ cảnh liên quan dễ dàng nằm gọn trong một cửa sổ.
- Dùng GPT-5.1-Codex-Max cho tái cấu trúc nhiều tệp, các tác vụ tác tử tự động đòi hỏi nhiều chu kỳ lặp, các quy trình kiểu CI/CD hoặc khi bạn cần mô hình giữ được góc nhìn ở cấp độ dự án qua nhiều tương tác.
Các mẫu prompt thực tế và ví dụ để đạt kết quả tốt nhất?
Các mẫu prompting hoạt động tốt
- Nêu rõ mục tiêu và ràng buộc: “Refactor X, giữ nguyên API công khai, giữ nguyên tên hàm và đảm bảo các bài kiểm thử A,B,C đều pass.”
- Cung cấp ngữ cảnh tái tạo tối thiểu: liên kết tới bài kiểm thử đang lỗi, kèm stack trace và các đoạn tệp liên quan thay vì đổ toàn bộ repository. Codex-Max sẽ nén lịch sử khi cần.
- Dùng hướng dẫn theo từng bước cho các tác vụ phức tạp: chia công việc lớn thành chuỗi tác vụ con, và để Codex-Max lặp qua chúng (ví dụ: “1) chạy kiểm thử 2) sửa 3 bài kiểm thử lỗi đầu tiên 3) chạy linter 4) tóm tắt thay đổi”).
- Yêu cầu giải thích và diff: yêu cầu cả bản vá và phần giải thích ngắn để người rà soát có thể nhanh chóng đánh giá mức độ an toàn và chủ đích.
Các mẫu prompt ví dụ
Tác vụ tái cấu trúc
“Refactor mô-đun
payment/để tách xử lý thanh toán vàopayment/processor.py. Giữ ổn định chữ ký hàm công khai cho các caller hiện có. Tạo unit test choprocess_payment()bao phủ trường hợp thành công, lỗi mạng và thẻ không hợp lệ. Chạy bộ kiểm thử và trả về các bài kiểm thử lỗi cùng một bản vá ở định dạng unified diff.”
Sửa lỗi + kiểm thử
“Một bài kiểm thử
tests/test_user_auth.py::test_token_refreshbị lỗi với traceback . Điều tra nguyên nhân gốc, đề xuất cách sửa với thay đổi tối thiểu và thêm một unit test để ngăn hồi quy. Áp dụng bản vá và chạy kiểm thử.”
Tạo PR lặp lại
“Triển khai tính năng X: thêm endpoint
POST /api/exportphát luồng kết quả export và có xác thực. Tạo endpoint, thêm tài liệu, tạo kiểm thử và mở một PR với phần tóm tắt và checklist các mục thủ công.”
Với hầu hết các trường hợp này, hãy bắt đầu với mức nỗ lực medium; chuyển sang xhigh khi bạn cần mô hình thực hiện suy luận sâu trên nhiều tệp và qua nhiều vòng lặp kiểm thử.
Cách truy cập GPT-5.1-Codex-Max
Hiện khả dụng ở đâu
OpenAI hiện đã tích hợp GPT-5.1-Codex-Max vào các công cụ Codex: Codex CLI, các tiện ích mở rộng IDE, cloud và các luồng rà soát mã mặc định dùng Codex-Max (bạn có thể chọn Codex-Mini). Khả năng truy cập API đang được chuẩn bị ; GitHub Copilot có các bản xem trước công khai bao gồm các mô hình GPT-5.1 và dòng Codex.
Các nhà phát triển có thể truy cập GPT-5.1-Codex-Max và GPT-5.1-Codex API thông qua CometAPI. Để bắt đầu, hãy khám phá khả năng mô hình của CometAPI trong Playground và tham khảo hướng dẫn API để biết chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập vào CometAPI và có API key. CometAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để hỗ trợ bạn tích hợp.
Sẵn sàng bắt đầu?→ Đăng ký CometAPI ngay hôm nay !
Nếu bạn muốn biết thêm mẹo, hướng dẫn và tin tức về AI, hãy theo dõi chúng tôi trên VK, X và Discord!
Bắt đầu nhanh (từng bước thực tế)
- Đảm bảo bạn có quyền truy cập: xác nhận rằng gói sản phẩm ChatGPT/Codex của bạn (Plus, Pro, Business, Edu, Enterprise) hoặc gói API dành cho nhà phát triển của bạn hỗ trợ các mô hình dòng GPT-5.1/Codex.
- Cài đặt Codex CLI hoặc tiện ích mở rộng IDE: nếu bạn muốn chạy các tác vụ mã cục bộ, hãy cài Codex CLI hoặc tiện ích mở rộng Codex IDE cho VS Code / JetBrains / Xcode nếu phù hợp. Bộ công cụ sẽ mặc định dùng GPT-5.1-Codex-Max trong các thiết lập được hỗ trợ.
- Chọn mức nỗ lực suy luận: bắt đầu với mức medium cho hầu hết tác vụ. Đối với gỡ lỗi sâu, tái cấu trúc phức tạp hoặc khi bạn muốn mô hình suy nghĩ kỹ hơn và không quan tâm đến độ trễ phản hồi, hãy chuyển sang chế độ high hoặc xhigh. Với các bản sửa nhỏ nhanh chóng, low là hợp lý.
- Cung cấp ngữ cảnh repository: đưa cho mô hình một điểm khởi đầu rõ ràng — URL repo hoặc một tập các tệp cùng hướng dẫn ngắn (ví dụ: “refactor mô-đun thanh toán để dùng async I/O và thêm unit test, giữ nguyên các hợp đồng ở cấp hàm”). Codex-Max sẽ nén lịch sử khi tiến gần tới giới hạn ngữ cảnh và tiếp tục công việc.
- Lặp lại với kiểm thử: sau khi mô hình tạo ra các bản vá, hãy chạy bộ kiểm thử và phản hồi lại các lỗi như một phần của phiên đang diễn ra. Compaction và tính liên tục qua nhiều cửa sổ cho phép Codex-Max giữ lại ngữ cảnh quan trọng về các bài kiểm thử bị lỗi và tiếp tục lặp.
Kết luận:
GPT-5.1-Codex-Max là một bước tiến đáng kể hướng tới các trợ lý lập trình tác tử có thể duy trì các tác vụ kỹ thuật phức tạp, chạy dài với hiệu quả và khả năng suy luận được cải thiện. Những tiến bộ kỹ thuật (compaction, các chế độ nỗ lực suy luận, huấn luyện cho môi trường Windows) khiến nó đặc biệt phù hợp với các tổ chức kỹ thuật hiện đại — miễn là các nhóm kết hợp mô hình này với các biện pháp kiểm soát vận hành thận trọng, chính sách human-in-the-loop rõ ràng và giám sát vững chắc. Đối với những nhóm áp dụng cẩn trọng, Codex-Max có tiềm năng thay đổi cách phần mềm được thiết kế, kiểm thử và bảo trì — biến những công việc kỹ thuật lặp lại, nặng nhọc thành sự cộng tác giá trị cao hơn giữa con người và mô hình.