

Cursor’s Composer 2 is the company’s newest agentic coding model, announced on March 19, 2026. Cursor describes it as “frontier-level at coding,” built for low-latency software work, and available directly inside Cursor with a standalone usage pool for individual plans. The launch also introduced a faster variant with the same intelligence, plus a new pricing structure designed to make agentic coding more affordable than many general-purpose frontier models.
Composer 2 matters because it reflects a broader shift in AI software development: the value is no longer just raw model intelligence, but the combination of speed, long-horizon task handling, tool use, and cost efficiency. Cursor’s own framing is explicit: the model is optimized for agentic coding, can handle challenging tasks that require hundreds of actions, and was trained to preserve critical context across long-running workflows.
What is Composer 2?
A model built for agentic coding, not just text completion
Composer 2 is Cursor’s in-house coding model. Composer 2 is specialized for software engineering intelligence and speed, trained in the Cursor agent harness, and intended to work well on real coding tasks rather than generic chat. That matters because agentic coding is different from ordinary code generation: the model must search a codebase, edit files, reason over multiple steps, and recover from mistakes without losing the thread of the task. Cursor’s long-horizon training post makes this design goal very clear.
Dual Model Variants:
| Variant | Purpose |
|---|---|
| Standard | Lowest cost |
| Fast | Higher speed (default) |
Why Cursor built it
Cursor’s research posts suggest a simple thesis: better coding agents need both intelligence and efficient continuation over many steps. Its internal benchmark (CursorBench) observations show that stronger performance on hard real-world coding tasks correlates with more thinking and more codebase exploration. Composer 2 is therefore trained not only to solve tasks, but to keep solving them across long trajectories that exceed the model’s immediate context length.
How Composer 2 Work?
Continued pretraining is the big upgrade
Composer 2’s quality gains come from its “first continued pretraining run,” which it describes as providing a much stronger base for reinforcement learning. This is important because it suggests the model is not merely a tuned version of Composer 1.5; it is a better starting point for the kind of long-horizon coding behavior Cursor wants.
Reinforcement learning on long coding trajectories
After continued pretraining, Cursor trains Composer 2 on long-horizon coding tasks through reinforcement learning. The company claims Composer 2 can solve difficult problems requiring hundreds of actions. In practical terms, that means the model is being taught to persist through multi-step debugging, code navigation, and iterative repair loops rather than producing a single-shot answer and stopping there.
Self-summarization is a key research advance
Cursor trains Composer for longer horizons using “self-summarization.” In that setup, when the model reaches a context trigger, it pauses and summarizes its own working state, then continues from that compressed context. Cursor says this technique lets it train on trajectories much longer than the model’s max context window and reward the summaries themselves as part of the training signal.
Durability
The practical upside is durability. Long coding tasks often fail when an agent forgets an earlier decision or loses the important details in a sprawling workspace. Self-summarization reduces compaction error by 50% while using one-fifth of the tokens compared with a tuned prompt-based compaction baseline in its test environments. That is a substantial claim, because compaction is one of the weak points of current agent systems.
What’s New in Composer 2?
1. Continued Pretraining + RL Scaling
Composer 2 introduces Cursor’s first large-scale continued pretraining pipeline, creating a stronger base model for reinforcement learning.
Then, it applies:
- Long-horizon RL training
- Task chaining across multiple steps
- Real-world coding workflows
👉 Result: Better handling of complex engineering tasks, not just code snippets.
2. Long-Horizon Task Execution
Unlike earlier models that fail after a few steps:
- Composer 2 can complete multi-file refactors
- Execute terminal workflows
- Maintain state across hundreds of actions
This pushes it toward true AI coding agent behavior.
3. Code-Only Training Strategy
Composer 2 is trained only on programming-related data.
Why this matters:
| Factor | General Models | Composer 2 |
|---|---|---|
| Model size | Large | Smaller |
| Scope | Broad | Narrow |
| Efficiency | Lower | Higher |
| Cost | High | Low |
👉 This explains the massive price-performance advantage.
4. Hybrid Foundation (Kimi Base + RL)
Recent disclosures revealed that Composer 2 was initially built on top of Kimi K2.5 (Moonshot AI) with additional reinforcement training.
- Only ~25% compute from base model
- Majority from Cursor’s training stack
👉 This reflects a new trend: hybrid model engineering + proprietary optimization
Performance benchmarks
| Model | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Relative to Composer 1.5, Composer 2 is about 38.7% higher on CursorBench, 28.8% higher on Terminal-Bench 2.0, and 11.8% higher on SWE-bench Multilingual. That does not prove universal superiority over every external model, but it does show a clear step up within Cursor’s own model line.
How Do You Access Composer 2?
Cursor positions Composer 2 as part of the product’s agent-first workflow. It is available in Cursor itself, and Cursor says that on individual plans, Composer usage comes from a standalone usage pool with generous included usage. Cursor also says users can try Composer 2 in the “early alpha” of its new interface. That means Composer 2 is not just a model API; it is meant to be used inside Cursor’s agent workflow, where the editor, agent, browser, and review tools work together.
Inside Cursor
Composer 2 is available in Cursor and also in the early alpha of its new interface. The practical access model is product-native rather than API-first: users interact with it inside the Cursor editor and its agent workflow. That is consistent with Cursor’s broader direction, where the company treats the editor as the primary surface for model interaction.
Usage pools and plan structure
Every individual plan includes two usage pools that reset each billing cycle: Auto + Composer, which gives significantly more included usage when Auto or Composer 2 is selected, and an API pool charged at the model’s API rate. Cursor also says individual plans include at least $20 of API usage each month, with the exact amount increasing on higher tiers. The practical takeaway is that Composer 2 is designed to be used frequently without immediately forcing every request into pure API billing.
API Price:
$0.50 input / $2.50 output per 1M tokens; fast variant $1.50 / $7.50
Plan context
Cursor Pro at $20 per month, Pro Plus at $60, and Ultra at $200, each with different included usage levels. For teams, Cursor also offers Teams and Enterprise with additional controls. That matters because Composer 2 is not just a model SKU; it is part of a broader product package that blends pricing, usage pools, and collaboration controls.
Composer 2 vs Claude Opus 4.6 vs GPT-5.4: Which one should I choose?
Terminal-Bench 2.0
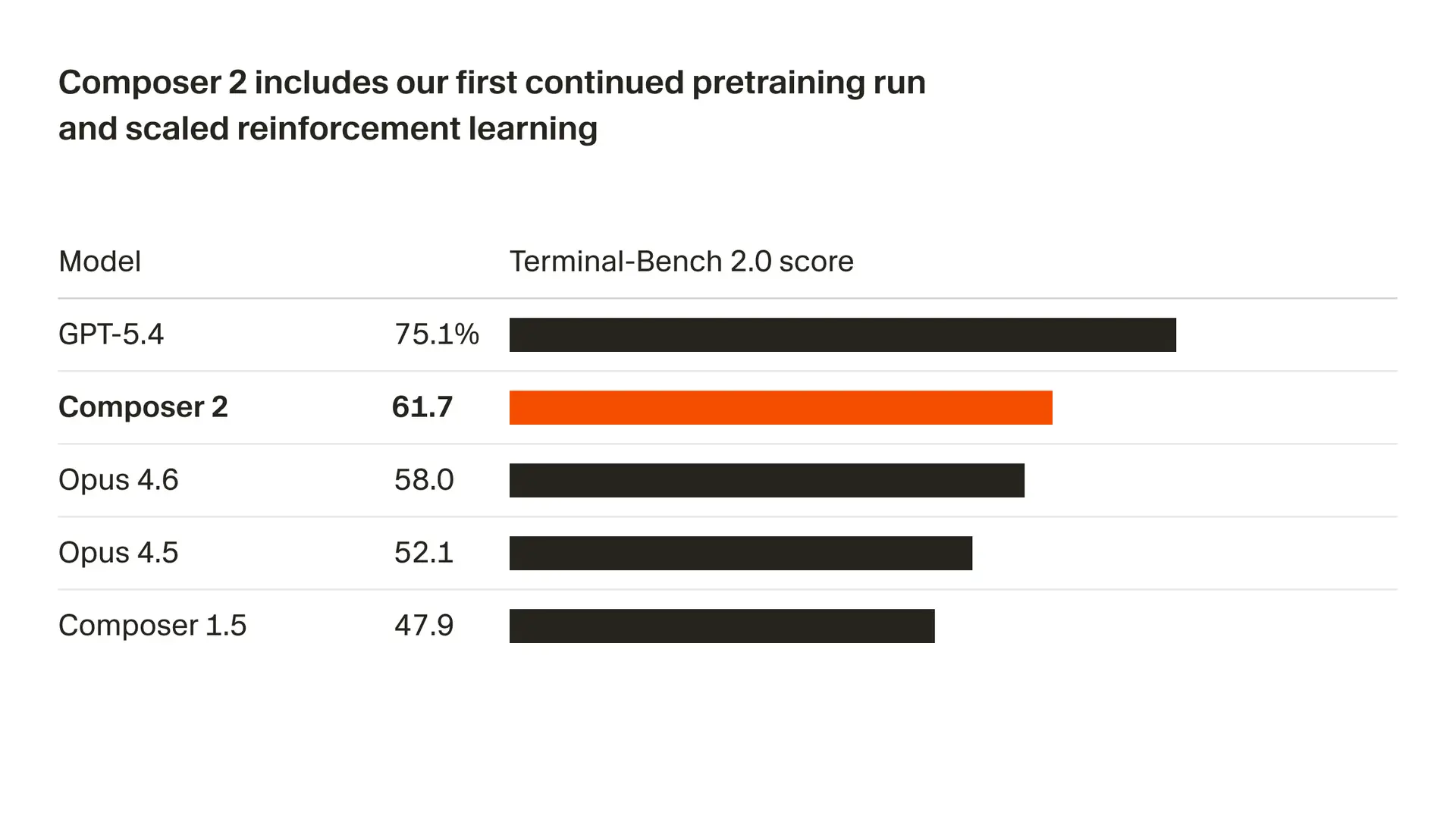
| Model | Score |
|---|---|
| Composer 2 | 61.7 |
| Claude Opus 4.6 | ~58 |
| GPT-5.4 | ~75 |
👉 Composer 2:
Trails GPT-5.4 in peak performance
Beats Opus 4.6 in some setups
Official Pricing
| Model | Input ($/M tokens) | Output ($/M tokens) |
|---|---|---|
| Composer 2 | 0.50 | 2.50 |
| Composer 2 Fast | 1.50 | 7.50 |
| Claude Opus 4.6 | 5.00 | 25.00 |
| GPT-5.4 | 2.50–5.00 | 15.00–22.50 |
👉 Composer 2 is:
- 10× cheaper than Opus 4.6
- ~5–6× cheaper than GPT-5.4
Why are Claude Opus 4.6 and GPT-5.4 still worthwhile?
Composer 2 is a strong fit for developers who spend most of their time inside Cursor, especially on repetitive code-editing loops, refactors, multi-file changes, and agentic tasks that benefit from speed and cost efficiency, is optimized around code and long-horizon action execution, with pricing that is dramatically lower.
But Claude Opus 4.6 and GPT-5.4 each bring wider professional capabilities, large context windows, and richer enterprise features. If you need to produce a polished essay, a spreadsheet, and a browser-agent workflow in one go.
Comparison Table:
| Feature | Composer 2 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| Focus | Coding only | General AI | General AI |
| Cost | ⭐ Lowest | Very high | Medium |
| Coding Accuracy | High | Very high | High |
| Reasoning | Medium | Very high | Very high |
| Speed | Fast variant available | Moderate | Moderate |
| Agent Capability | Strong | Strong | Improving |
| Multimodal | ❌ | ✅ | ✅ |
| Best Use Case | Dev workflows | Research-grade tasks | General + coding |
Best-fit use cases and Access
If the task is broad reasoning, multimodal work, or general enterprise use, GPT-5.4 and Claude Opus 4.6 are both strong candidates based on their official positioning and capabilities. If the task is day-to-day coding inside Cursor, especially where cost and iteration speed matter, Composer 2 is the more specialized and cheaper fit. Cursor positions Composer 2 as a specialized agentic coding model for Cursor itself. , GPT-5.4 and Opus 4.6 are broad frontier models, while Composer 2 is purpose-built for the IDE-agent loop.
OpenAI positions GPT-5.4 as a frontier model for complex professional work, with tool support in the API and strong general reasoning. Anthropic positions Claude Opus 4.6 as its smartest model for coding, reasoning, and agentic work, now they all are with availability across CometAPI.
CometAPI's API is currently 20% off, and it can directly generate playgrounds. Compared to other solutions, CometAPI is a much better option; it's essentially a cursor that doesn't require a subscription.
Comclusion
Composer 2 is not just another incremental Cursor model. It is Cursor’s attempt to reset the price-performance curve for coding agents: stronger benchmark results than its predecessors, a design centered on long-horizon agent behavior, and pricing that is dramatically below the big frontier alternatives. Cursor’s own evidence shows clear gains over Composer 1 and 1.5, while its pricing undercuts Claude Opus 4.6 by 10x and GPT-5.4 by 5x on input tokens.
For teams already living in Cursor, Composer 2 is a compelling default for many coding tasks. For the hardest, highest-stakes, or widest-scope work, Claude Opus 4.6 and GPT-5.4 remain the premium benchmarks to compare against. The real story is that the frontier coding market is getting sharper, cheaper, and more specialized all at once.
If you're looking for an alternative to Cursors, or a cheaper, cutting-edge model API like Claude Opus 4.6 and GPT-5.4, then CometAPI is the best choice. Ready to go?