

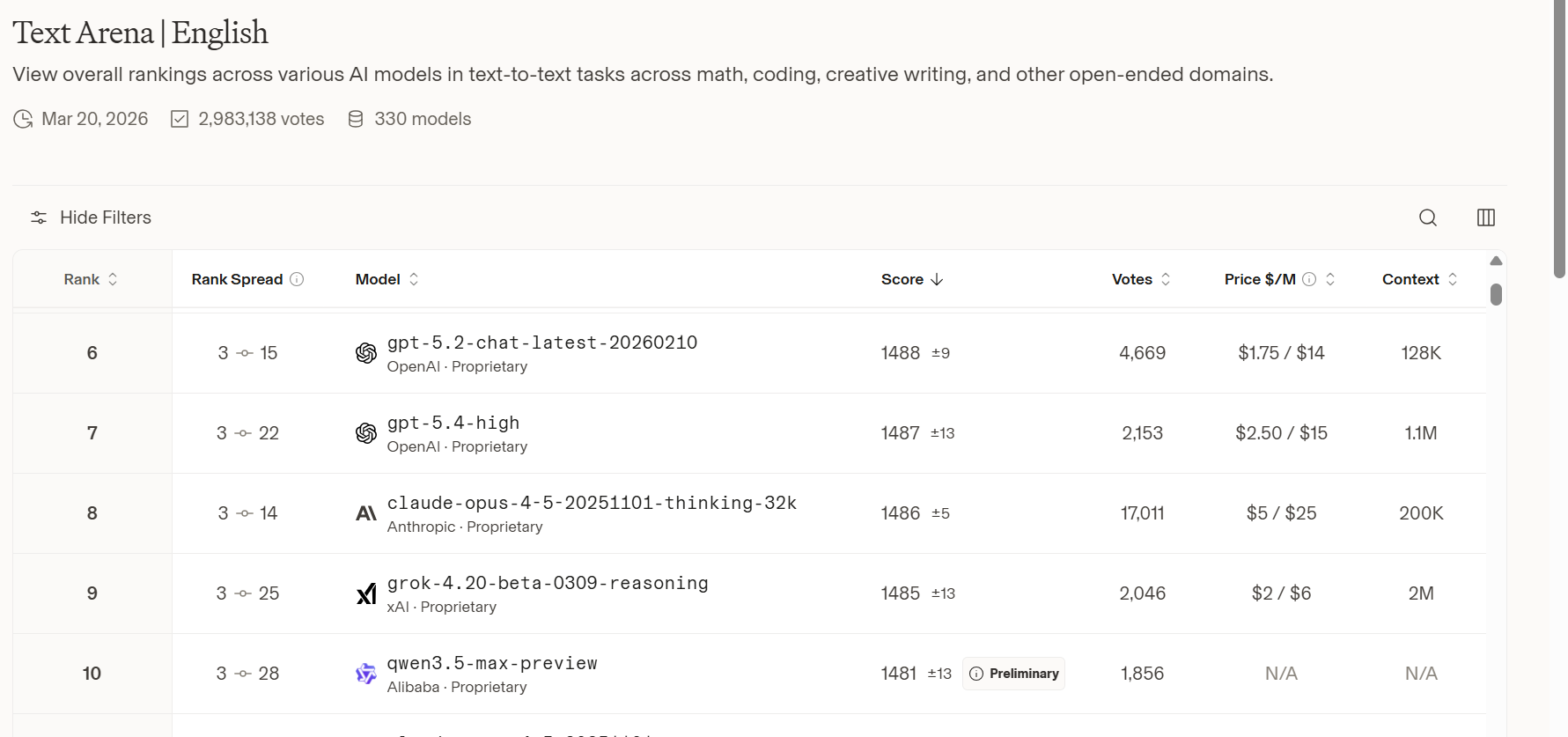
Alibaba’s Qwen team has pushed its model lineup into a new phase with the launch of Qwen3.5-Max-Preview in February 2026, a flagship release in the Qwen3.5 family that the team positions as a native multimodal agent model., In the latest public leaderboard snapshot, qwen3.5-max-preview was added to LMArena’s Text leaderboard on March 19, 2026, and currently appears at rank 10 on the English Text leaderboard and rank 15 on the overall Text leaderboard.
Since Lunar New Year's Eve, the Qwen 3.5 series has successively released eight models with different parameter scales, ranging from 0.8B to 397B. You Can access Qwen 3.5 Flash, qwen3.5-plus and qwen3.5-397b-a17b.
What is Qwen 3.5-Max?
Qwen 3.5-Max represents the flagship tier of Alibaba’s Qwen 3.5 model series, designed to compete directly with frontier AI models from OpenAI, Anthropic, and Google.
At its core, Qwen 3.5-Max is:
- A large-scale Mixture-of-Experts (MoE) model
- Built for agentic AI workflows
- Optimized for high reasoning, coding, and multimodal tasks
- Designed to reduce cost while increasing performance
The Qwen 3.5 family itself is an evolution of earlier Qwen models, but with a strategic shift toward autonomous AI agents—systems capable of independently executing complex workflows across tools and environments.
Qwen 3.5-Max is positioned as a key competitor in the “agentic AI era”, where models don’t just generate text but take actions across applications.
Qwen 3.5-Max Jumps to Top Global Rankings
A Stunning Debut in 2026
Recent developments show that Qwen 3.5-Max (and its underlying architecture) has rapidly climbed global AI rankings, with strong performance across multiple benchmark suites.
Key highlights:
qwen3.5-max-preview was added to the LMArena Text leaderboard on March 19, 2026, according to the leaderboard changelog. In the live leaderboard snapshot, the model is shown with a preliminary score of 1481±13 on the English Text leaderboard, and in the broader Text leaderboard snapshot it appears at 1464±9, again marked preliminary:
- Ranked among top global LLMs (Top 5–Top 6 range in some leaderboards)
- Achieved top-tier scores across reasoning and coding benchmarks
- Outperformed several U.S. frontier models in multiple categories
This rapid ascent reflects a broader shift: Chinese AI models are now competing at the very top of global rankings, not just regionally.
Benchmark Performance
Core Benchmark Scores
| Benchmark | Qwen 3.5-Max | Industry Position |
|---|---|---|
| AIME (Math) | 91.3 | Top-tier |
| GPQA Diamond | 88.4 | Leading |
| LiveCodeBench v6 | 83.6 | Industry-leading |
| MMLU-Pro | ~84–86 | Top 20% |
| BrowseComp | 78.6 | Best-in-class |
Interpretation of Benchmarks
Strengths:
- Mathematical reasoning → near state-of-the-art
- Coding → top-tier
- Scientific reasoning → leading
Weaknesses:
- Some coding benchmarks still trail top proprietary models
- Real-world consistency varies depending on task
For developers, the practical takeaway is clear: Qwen3.5 is being positioned as a model that can work across chat, coding, agent workflows, web research, multimodal understanding, and long-context tasks. The official ecosystem support for Qwen Chat, Qwen API, Qwen Code, and Qwen Agent makes it easier for teams to adopt the model in different forms, while the benchmark table suggests it is not merely a local-market model but one that can compete meaningfully in the global frontier conversation.
Why is Qwen3.5-Max-Preview getting so much attention? Is is Worth?
The attention comes from a rare combination of three things: a flagship model name, a strong Arena debut, and a broader Qwen3.5 launch narrative that emphasizes agentic capabilities and lower operating cost. Alibaba introduced Qwen 3.5 as a model built for the “agentic AI era,” claiming it is 60% cheaper to use and eight times better at handling large workloads than its predecessor, while also adding visual agentic capabilities across mobile and desktop environments.
A strong debut, but not a final verdict
Qwen3.5-Max-Preview is best understood as a flagship preview model that combines a large sparse architecture, native multimodality, long context, multilingual reach, and competitive benchmark performance. Its debut on LMArena, the quick media reaction, and the strong benchmark table all point to a model that is already serious competition in the frontier race. At the same time, the “fifth place” narrative should be read carefully: the public text leaderboard snapshot shows a solid but not topmost rank, while company-level coverage paints a more favorable overall picture for Alibaba.
Why this release stands out
What makes Qwen3.5-Max noteworthy is not a single number, but the combination of capability breadth, efficiency design, and deployment flexibility. It is rare to see a model that is simultaneously positioned for long-context reasoning, multimodal understanding, tool use, agent planning, and open-weight ecosystem adoption. If Alibaba continues to refine the preview version into a full release, Qwen3.5-Max could become one of the most consequential models in the next wave of global AI competition.
Bottom line
Qwen3.5-Max-Preview is best understood as Alibaba’s latest flagship preview model in the Qwen3.5 line: a multimodal, agent-oriented system that the company says can handle complex tasks more efficiently than before, with official messaging emphasizing visual agentic capabilities, lower cost, and stronger large-workload performance. Its LMArena debut at 1464 points shows that the model is immediately competitive with the field’s most visible systems, even though exact rank labels differ across live boards and report formats. In a market where perception, performance, and pricing all matter, that is enough to make Qwen3.5-Max one of the most closely watched model launches of the season.
If you are a developer looking for the Qwen 3.5 series APIs, then CometAPI is a good choice. Its pricing strategy and diversity of integration vendors will ensure you don't miss out on any AI model.