

阿里巴巴的 Wan2.7-Image 于 2026 年 4 月 1 日发布,标志着 AI 视觉生成的重大飞跃。该统一模型将文生图创作、交互式编辑、多图合成与语义理解融于单一架构。不同于传统将生成与编辑分离的流水线,它消除了“标准化 AI 脸”、文字乱码与颜色不可控等不一致问题。
创作者、设计师、营销人员与企业如今可用更少迭代获得照片级、严格遵循指令的结果。该模型支持最多 12 张连续图像、9 张参考融合、12 种语言文本渲染(最多 3,000 tokens),以及像素级控制。
什么是 Wan2.7-Image?
Wan2.7-Image 是阿里巴巴 Tongyi Lab 在 Wan(Tongyi Wanxiang)系列中的旗舰统一图像模型。它覆盖端到端视觉工作流:文生图、图生图、基于指令的编辑与交互式像素级微调——全部在一个共享的潜在空间中完成。
该模型于 2026 年 4 月 1 日发布,基于此前以 VBench 基准测试位居前列的 Wan 2.x 视频模型,转而聚焦图像精度。它直接应对重复面孔、颜色不稳定与提示对齐差带来的“审美疲劳”。该模型家族对用户而言有两款最重要的名称:wan2.7-image 与 wan2.7-image-pro。标准版侧重于更快的生成速度,而 Pro 版面向专业输出,支持4K 高清。
关键差异点:统一架构。传统模型采用割裂的多阶段流程(编码器 → 扩散 → 解码器),编辑需单独的补绘环节。Wan2.7-Image 在共享空间中直接映射语义,实现真正理解,而非像素模式匹配。
为什么 Wan2.7-Image 很重要(行业背景)
传统 AI 图像工具的痛点:
| 问题 | 说明 |
|---|---|
| 工作流割裂 | 生成、编辑、补绘分属不同工具 |
| “AI 脸综合征” | 人脸重复、缺乏真实感 |
| 指令对齐弱 | 难以准确遵循提示 |
| 文本渲染差 | 文本扭曲或不可读 |
| 多图输出不一致 | 角色在多帧之间发生变化 |
Wan2.7-Image 通过统一架构 + 语义理解层正面解决这些限制。
Wan2.7-Image 的 5 大核心特性
1. 骨骼级头像定制,打造真正独一无二的面孔
Wan2.7-Image 擅长实现“每个人都有独特面孔”。它支持对骨骼结构、眼型(杏眼、丹凤眼、深邃、浮肿、笑眼)、面部轮廓与细微特征的精细控制,从根源上消除过往模型中的“标准化 AI 脸”。

示例提示词:“一位 28 岁东亚女性的照片级人像,椭圆脸,杏仁眼,浅浅微笑,皮肤纹理细腻,自然光照。” 结果呈现出栩栩如生的多样性,适用于虚拟网红、游戏 NPC 或个性化品牌形象。
2. 精确的颜色调色板控制
其中一个最实用的功能是全新的颜色调色板控制。阿里巴巴表示,用户可输入特定色码与比例以复刻艺术风格或锁定品牌色。API 文档将其正式定义为 color_palette 参数,可接受3 至 10 种颜色,推荐 8 种。对品牌团队而言,这是本次发布中最明确的企业级特性之一。不再随机偏色——在整个活动中实现完美一致性。
官方引述:“告别随机颜色生成。实现精确的色彩配比,让你的创意愿景落地。”——Tongyi Wanxiang
3. 高级多语种文本渲染(12 种语言,3,000 tokens)
以印刷级清晰度(相当于 A4)渲染超长文本、表格、公式、图表与信息图。支持中文、英文、日语、韩语等共 12 种语言。学术论文、海报、产品标签与多语横幅可实现近乎完美的可读性——直击 AI 长期弱项。
4. 选框工具加持的像素级交互式编辑
可用边界框(editRegions)或框选工具进行定向修改。上传最多 9 张参考图,并给出诸如“将背景更换为海滩日落,保留面部、姿势与服装”的指令。像素级精度确保人物身份得以保留。
5. 多图组合生成(最多 12 张连续图像)
该模型不仅面向单次提示生成。阿里巴巴称,用户可使用最多 9 张参考图并一次性生成最多 12 张图像,非常适合连贯的分镜、建筑与电商系列。“点击即编辑”的流程允许用户选择特定区域,并以像素级精度进行修改;API 文档还通过边界框参数补充了交互式精确编辑。
Wan2.7-Image 如何运作?(技术深潜)
阿里巴巴将 Wan2.7-Image 描述为连接语言与视觉的框架,基于海量多样数据集训练。通俗而言,模型不仅学习如何绘制图像,还在学习提示词如何映射到视觉结构、构图、光照与文本排版。这使其比基础的文生图系统更准确地理解用户意图。
API 也表明该模型支持多模态输入。实际使用中,请求通过单轮消息结构发送,内容可同时包含文本与图像项。对于编辑,用户可以传入多张图片与指令(如“移动”“替换”“融合”)来引导结果。这清晰表明 Wan2.7 设计为“提示 + 参考”的系统,而非简单的一次性生成器。
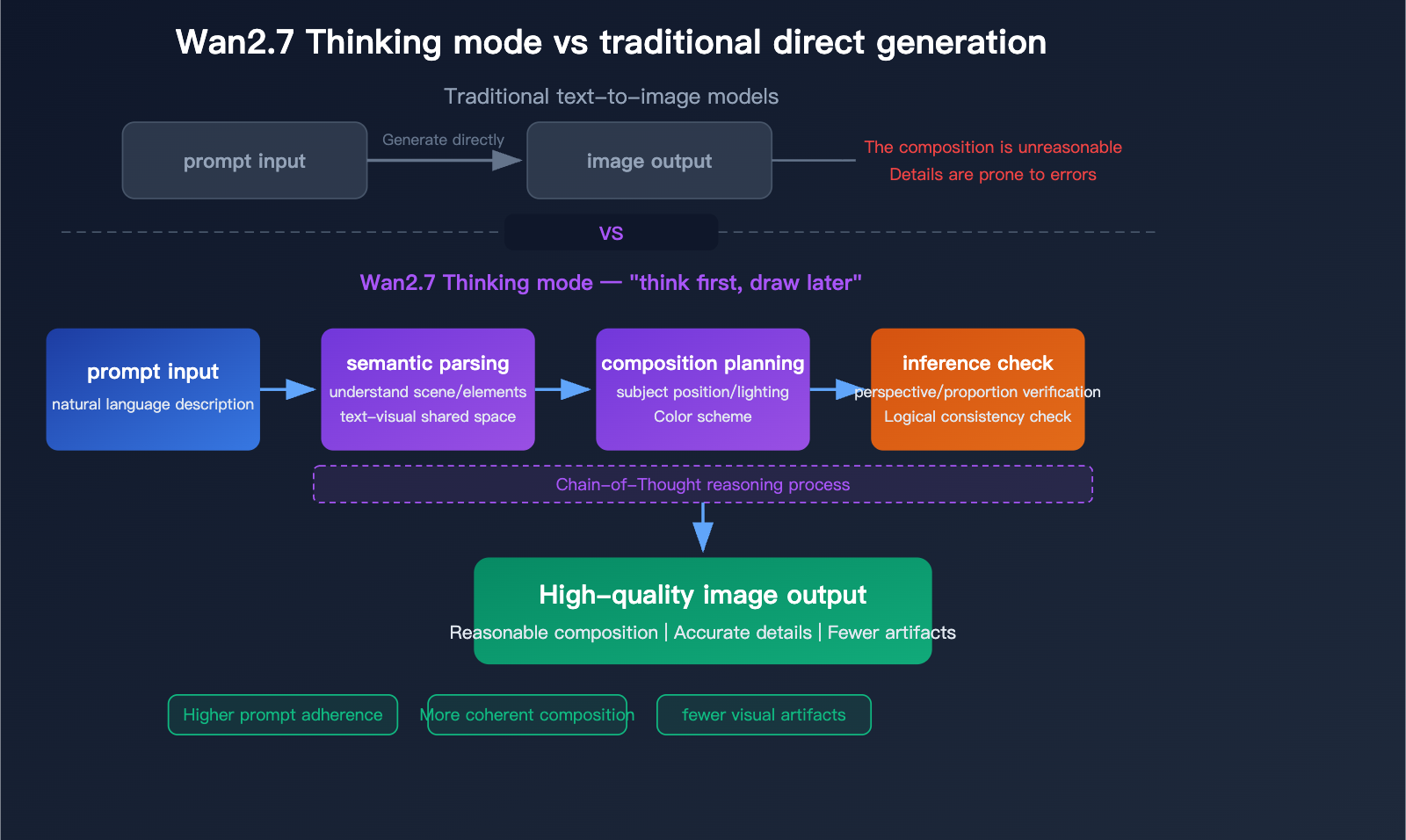
文档还提供了思考模式设置。该模式默认启用,可提升输出质量,但会增加生成时间。这为模型工作流提供线索:当请求文本较长或视觉复杂时,更高质量的输出可能需要更多内部推理时间。
Wan2.7-Image 采用共享潜在空间中的统一生成-编辑框架:
- 输入阶段:文本提示(最多 3,000 tokens)+ 可选参考图(最多 9 张)。
- 语义解析与思考模式(Pro 版增强):在像素生成前,链式推理分析构图、空间关系、光照与逻辑。
- 共享潜在空间映射:语义直接映射到视觉特征——不存在割裂的编码器/解码器鸿沟。
- 统一推理:生成或编辑在单一优化流程中完成。编辑区域使用边界框;调色板强制执行比例。
- 输出:高保真图像(标准 768–2048×2048;Pro 版 4K),可选 JPG/PNG/WEBP,提供用于复现的种子与安全检查。
对 Wan2.7-Image-Pro 的深入分析:以 4K 质量、推理模式与 12 语种文本渲染树立 AI 图像生成新标杆 - Apiyi.com Blog
思考模式流程图(Pro)展示了语义解析 → 构图规划 → 推理校验,相较直接生成,可带来更少伪影与更高的提示遵循度。
多样数据训练带来对意图、光照与版式的深刻理解。长上下文学习(arXiv 研究中有提及)为扩展文本处理提供支撑。
Wan2.7-Image 与 Wan2.7-Image-Pro:关键差异
两者同步发布,但 Pro 面向专业需求。
| 功能 | Wan2.7-Image(标准版) | Wan2.7-Image-Pro | 最佳适用 |
|---|---|---|---|
| 最大分辨率 | 2048×2048 | 4096×4096(4K) | 印刷/生产(Pro) |
| 思考模式 | 可用(默认更快) | 增强/默认,更深层推理 | 复杂场景(Pro) |
| 构图稳定性 | 强 | 语义理解更优 | 商业项目(Pro) |
| 速度 vs 质量 | 更快迭代 | 更高保真,时间略长 | 原型迭代(标准版) |
| 使用场景 | 普通创作者、社媒内容 | 企业设计、学术/印刷 | 规模化 vs 精度 |
标准版适合快速原型;Pro 版提供一致性更强的 4K 级印刷就绪质量。
如何使用 Wan2.7-Image(步骤指南)
1. 访问平台
可通过以下渠道使用:
- Alibaba Cloud(BaiLian platform)
- Wanxiang 官方工具
- CometAPI
2. 选择工作流模式
Mode A: 文生图
提示示例:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Mode B: 图像编辑
- 上传图片
- 选择区域
- 输入指令
示例:
Replace background with a futuristic city
Mode C: 多图合成
- 上传多张参考图
- 定义组合规则
3. 精调参数
- 颜色调色板
- 风格一致性
- 文本渲染
4. 导出输出
- 高分辨率图像
- 可商用的成品素材
基准表现与竞品对比
在盲测的人类偏好测试中,Wan2.7-Image 在文生图质量上超越 GPT-Image-1.5,并在文本渲染、照片真实感与世界知识方面与 Nano Banana Pro 持平或更胜一筹。
比较表:
| 模型 | 文本渲染 | 指令遵循 | 头像定制 | 多图参考 | 统一生成/编辑 | 分辨率 | 开源/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | 优秀(12 种语言) | 出色(思考模式) | 骨骼级 | 9 | 是 | 2K–4K | 是/API |
| Midjourney V8 | 良好 | 中等 | 艺术风格强 | 受限 | 否 | 高 | 仅限 Discord |
| FLUX | 良好 | 强(简单场景) | 良好 | 受限 | 否 | 高 | 是 |
| DALL-E 3 | 中等 | 良好 | 中等 | 否 | 否 | 2K | API |
| Nano Banana Pro | 强 | 强编辑 | 良好 | 强 | 部分 | 高 | 封闭 |
Wan2.7-Image 在统一工作流、多语种文本与精确控制方面领先——对非英语市场与专业生产线尤其有价值。
CometAPI 是一家一站式大模型 API 聚合平台,提供无缝集成与服务管理,支持多种图像生成 API,如 GPT-image-1.5、Nano Banana 系列、Midjourney,以及 Qwen Image Series 等,价格低于官网。
谁应该使用 Wan2.7-Image
Wan2.7-Image 对需要速度与灵活性、而非一次性艺术创作的团队尤为重要。这包括效果营销、产品设计、电商摄影工作室、社媒内容团队与需要从同一简报产出大量变体的代理公司。该模型对多图输入、多图批量生成与基于指令的编辑的支持,使其在强调一致性、速度与提示控制的工作流中极具吸引力。
典型落地场景
- 游戏/娱乐:数分钟内生成 100 位独特 NPC。
- 市场/电商:按精确色板输出的品牌一致轮播。
- 教育/学术:含公式与表格的印刷就绪海报。
- 设计机构:借助交互式编辑完成分镜与客户修订。
生产力提升来自更少的迭代与无缝的参考整合。
结论:
Alibaba Wan2.7-Image 通过统一生成、编辑与理解,重塑 AI 创造力。其 5 大核心特性、共享潜在空间与 Pro 版增强,带来专业级结果,竞争对手仍难以匹敌。无论是原型化社媒内容,还是生产级学术视觉,它都以无与伦比的精度与效率脱颖而出。
立即前往 wan.video 或通过 CometAPI 以 API 方式开始使用。对开发者与企业而言,性能、可用性与数据背书的结合,使 Wan2.7-Image 成为 2026 年及未来统一 AI 图像模型领域的明确领跑者。