

Both Gemini 3 Pro (Google/DeepMind) and Claude Sonnet 4.5 (Anthropic) are 2025-era flagship models optimized for agentic, long-horizon, tool-using workflows — and both place heavy emphasis on coding. Claimed strengths diverge: Google pitches Gemini 3 Pro as a general-purpose multimodal reasoner that also shines at agentic coding, while Anthropic positions Sonnet 4.5 as the best coding/agent model in the world with particularly strong edit/tool success and long-running agents.
Short answer up front: both models are top-tier for software engineering tasks in late 2025. Claude Sonnet 4.5 nudges ahead on some pure software-engineering bench metrics, while Google’s Gemini 3 Pro (Preview) is the broader, multimodal, agentic powerhouse—especially when you care about visual context, tool use, long-context work and deep agent workflows.
I currently use both models, and they each have different advantages in the development environment. I will now compare them in this article.
Gemini 3 Pro is only available to Google AI Ultra subscribers and paid Gemini API users. However, the good news is that CometAPI, as an all-in-one AI platform, has integrated Gemini 3 Pro, and you can try it for free.
What is Gemini 3 Pro Preview and what are its headline features?
Overview
Gemini 3 Pro (available initially as gemini-3-pro-preview) is Google/DeepMind’s latest “frontier” LLM in the Gemini 3 family. It’s positioned as a high-reasoning, multimodal model optimized for agentic workflows (that is, models that can operate with tool use, orchestrate subagents, and interact with external resources). It emphasizes stronger reasoning, multimodality (images, video frames, PDFs), and explicit API controls for internal “thinking” depth.
Key feature bullets (developer-facing)
- Agentic tool use: built-in function calling and tools (code execution, web grounding, file & URL context, terminal/tool use).
- Thinking / Chain-of-Thought support: “thinking” primitives for multi-step planning and internal thought signatures to make multi-step reasoning more explicit.
- Multimodal input/output: text, images, audio, video, and structured outputs with long context handling.
- Code execution tool & IDE integrations: a hosted code execution tool and integrations into IDEs and the new Google Antigravity agentic IDE for collaborative autonomous coding. Antigravity is currently public preview.
- High/extended thinking controls (
thinking_levelparameter) so you can trade latency for deeper internal reasoning.highis the default for Gemini 3 Pro. - Granular multimodal controls (
media_resolution) to tune image/video fidelity vs cost — useful when you want the model to read small text in screenshots or analyze frames.
Where Gemini 3 Pro shines for coding
- Agentic development: orchestrating multi-step tasks across editor/terminal/browser. Antigravity’s artifact system + Gemini’s tools make it excellent for larger feature work and automation.
- Visual + code combos: fixing UI bugs from screenshots, generating UI test harnesses, or converting design images into code because of strong image-to-code understanding.
What is Claude Sonnet 4.5 and what are its main features?
Claude Sonnet 4.5 is Anthropic’s 2025 release that Anthropic markets as its strongest model for coding, agentic workflows and “using computers” (controlling tools, browsers, terminals, spreadsheets, etc.). It emphasizes improved edit capability, tool success, extended thinking, long-running agent coherence (30+ hours of autonomous task execution in demonstrations), and lower code-editing error rates versus prior generations. Anthropic bills Sonnet 4.5 as their “best coding model” with large gains in edit reliability and long-horizon task coherence.
Key features (developer-facing)
- High coding accuracy on real-world engineering benchmarks: Anthropic reports state-of-the-art SWE-bench Verified scores and claims big improvements in edit error rates and tool-based agent success.
- Agentic and computer-use improvements: Sonnet 4.5 is designed to run multiple tools (bash, file editing, browser automation) and to orchestrate subagents via the Claude Agent SDK. Anthropic highlights “30+ hours” of continuous multi-step work in their internal evaluations.
- Large context windows: default 200k tokens for most customers, with a 1M-token context available in beta for higher-tier orgs (the same 1M capability Gemini offers in preview).
- Code execution tool & file APIs: in-product and API tools allow safe code execution, file creation/editing, and test-run loops.
Where Sonnet 4.5 shines for coding
- Pure software-engineering benchmarks and structured code tasks (unit test generation, repository-wide refactors) where the model’s algorithmic rigor and long-horizon stability matter.
- Code-first CLIs and “code assistant” flows such as Claude Code where tight terminal integration and repository scanning are provided out of the box.
Quick Comparison Table
| Aspect | Gemini 3 Pro (Preview) | Claude Sonnet 4.5 |
|---|---|---|
| Model / release status | gemini-3-pro-preview — Google / DeepMind frontier model (preview). Released Nov 2025 (preview). | claude-sonnet-4-5 — Anthropic Sonnet-class frontier model (GA / announced Sep 29, 2025). |
| Target positioning (coding & agents) | General-purpose frontier model with emphasis on reasoning + multimodal + agentic workflows; positioned as Google’s top coding/agent model. | Specialized for coding, long-horizon agenting and computer use (Anthropic’s “best for coding & complex agents”). |
| Key developer features | thinking_level control for deeper internal reasoning; built-in Google tool integrations (Search grounding, code execution, file/URL context); dedicated image variant for text+image workflows. | Agent SDKs, VS Code integration (Claude Code), file & code-execution tools, long-horizon agent improvements (explicitly tested for multi-hour runs). Emphasis on iterative edit/run/test workflows and checkpointing. |
| Context window (input / output) | 1,000,000 tokens input / 64k tokens output for gemini-3-pro-preview | 1,000,000 tokens input / 64k tokens output |
| Pricing (published baseline) | $2 / $12 per 1M tokens (input / output) for the <200k tier; higher rates for >200k ( show $4 / $18 for >200k). | Anthropic published baseline: $3 / $15 per 1M tokens (input / output) for Sonnet 4.5; |
| Multimodal capability (vision/video/audio) | Full multimodal support: text, images, audio, video frames with configurable image/video resolution parameters; dedicated gemini-3-pro-image-preview. Strong emphasis on image OCR/visual extraction for coding UIs/screenshots. | Supports vision (text+image) inputs and uses vision to support coding workflows; primary emphasis is agentic integration (using visual context inside agent flows rather than image generation parity). |
| Long-horizon agentic performance & persistence | “Thinking” primitives for explicit multi-step internal reasoning; strong math/reasoning & multimodal deep reasoning. Good at decomposing complex algorithmic tasks.Best for heavy single-response reasoning + multimodal analysis. | Anthropic emphasizes long-horizon agentic coherence — Anthropic reports internal tests where Sonnet 4.5 maintained coherent multi-step tool use for 30+ hours and improves continuous agent stability vs prior models. Good fit for persistent automation and CI-style agent workflows. |
| Output quality for coding (edits, tests, reliability) | Very strong single-shot reasoning + code generation; built-in tools to run code via Google’s tooling; high marks on algorithmic benchmarks per vendor claims. Practical advantage when the workflow mixes visual specs + code. | Designed for iterative edit→run→test loops; Sonnet 4.5 highlights improved “patching” reliability (rejection sampling / scoring techniques to pick robust patches) and tooling that supports iterative developer workflows (checkpoints, tests). |
How do their architectures and core capabilities compare?
Architecture and design intent (high level)
Gemini 3 Pro: presented as a multimodal, general-purpose foundation model with explicit engineering for “thinking” and tool use: the design emphasizes deep reasoning, video/audio understanding, and agentic orchestration via built-in function calling and code execution environments. Google frames Gemini 3 Pro as the “most intelligent” in the family, optimized for wide tasks beyond code (though agentic coding is a priority).
Claude Sonnet 4.5: optimized specifically for agentic workflows and code: Anthropic emphasizes instruction-following,tool reliability, edit/correction proficiency, and long horizon state management. The engineering focus is to minimize destructive or hallucinated edits and to make robust real-world computer interactions.
Takeaway: Gemini 3 Pro is pitched as a top generalist that’s been pushed hard on multimodal reasoning and agentic integration; Sonnet 4.5 is pitched as a specialist for coding and agentic tool use with enhanced edit/correction guarantees.
Tooling and integrations
- Gemini: built-in Google toolset incl. Search grounding, file search, code execution, and first-class image/video parameters;
thinking_levelparameter for controlling internal compute/latency tradeoffs. Deep integration into Google infra makes it convenient for teams already on Google Cloud. - Claude: robust agent SDK and an emphasis on stable long-run computation (Sonnet’s reported 30+ hour coherence). Anthropic also exposes code execution, file APIs, and a new “checkpoints” editing UX in Claude Code and VS Code extension — features that materially improve iterative coding workflows.
What do technical specifications and benchmarks say?
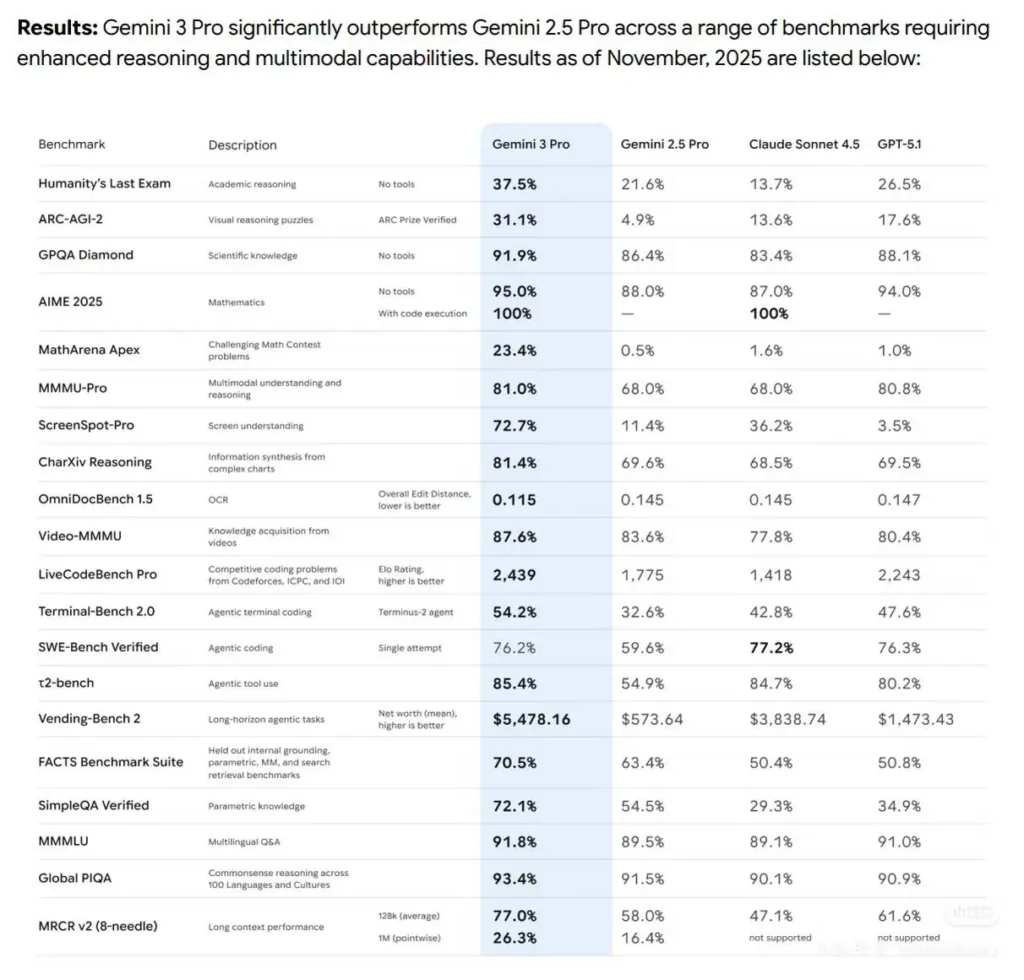
Benchmarks vary slightly depending on the evaluator and configuration (single attempt vs. multi-attempt, tool access, extended-thinking settings). Below are Benchmark data analysis of coding ability:
SWE-bench Verified (real-world software engineering tests)
Claude Sonnet 4.5 (Anthropic reported): 77.2% (200k thinking budget; 78.2% in 1M config). Anthropic also reports an 82.0% high-compute score using parallel attempts/rejection sampling.
Gemini 3 Pro (DeepMind reporting / related leaderboards): ~76.2% single-attempt on SWE-bench (vendor table). Public leaderboards vary (Gemini and Sonnet trade narrow margins).
Terminal-Bench & Agentic tasks
Gemini 3 Pro: Terminal/agentic bench numbers (vendor table) show strong performance (e.g., Terminal-Bench 54.2% in vendor table), competitive with Sonnet’s agentic strengths.
Sonnet 4.5: excels in agentic tool orchestration (Anthropic reports substantial gains on OSWorld and Terminal-style benchmarks and highlights longer continuous task performance).
Takeaway: the two models are very close on modern code-understanding and code-generation benchmarks; Sonnet 4.5 has a slight edge on some software-engineering verification suites (Anthropic’s published numbers), while Gemini 3 Pro is extremely competitive and often leads on multimodal and some coding-competition style leaderboards. Always validate with the exact evaluation configuration (tool access, context-size, thinking budgets), because those knobs materially change scores.
How do their multimodal capabilities compare?
Vision & image handling
- Gemini 3 Pro: fine-grained multimodal controls with image/video
media_resolution(low/medium/high token budgets per image/frame), image generation/editing (separate image preview model), and explicit guidance for OCR/visual detail. This makes Gemini particularly strong when coding tasks require reading screenshots, UI mockups, or video frames. - Claude Sonnet 4.5: supports text+image multimodality and Anthropic’s product integrations (Claude apps) expose visual workflows; the focus in Sonnet 4.5 is integrating visual context into agentic workflows rather than raw image synthesis parity.
When multimodality matters for coding
If your workflow heavily relies on UI screenshots, design specs in images, or video walkthroughs that the model must analyze to produce or modify code, Gemini’s dedicated image resolution controls and image-generation variant can be a practical advantage. If your pipeline is agent-driven automation (clicking around, running commands, editing files across tools), Claude’s agent SDK and code-execution tooling are first-class.
Advanced reasoning & long-horizon planning — which is better?
Sonnet 4.5: endurance and alignment
Sonnet 4.5 can maintain coherent work for over 30 hours across complex multi-stage tasks (planning, research, litigation drafting, long-running code tasks). This endurance plus Anthropic’s alignment emphasis makes Sonnet an attractive choice for end-to-end automation where the model must keep track of goals and maintain safe behavior.
Gemini 3 Pro: deep reasoning + agent orchestration
Gemini 3 Pro introduces a “Deep Think” variant and richer internal thinking APIs for multi-step planning, coupled with Google’s agentic IDE. In practice this means Gemini can both plan and execute agentic steps across tools (editor, shell, web). If your automation requires external tool access with artifact creation, Gemini’s integrated agentic tooling (Antigravity) is a strong plus. Note: Deep Think trades latency for depth.
Long-Horizon Planning Comparison: Vending-Bench 2
In the “Vending-Bench 2” simulation test, Gemini 3 outperformed Claude 4.5 by running a virtual company for a whole year and remaining profitable. In short-term tests, the Gemini 3 Pro and Claude 4 Sonnet data were similar, but the difference became more pronounced over longer testing periods.
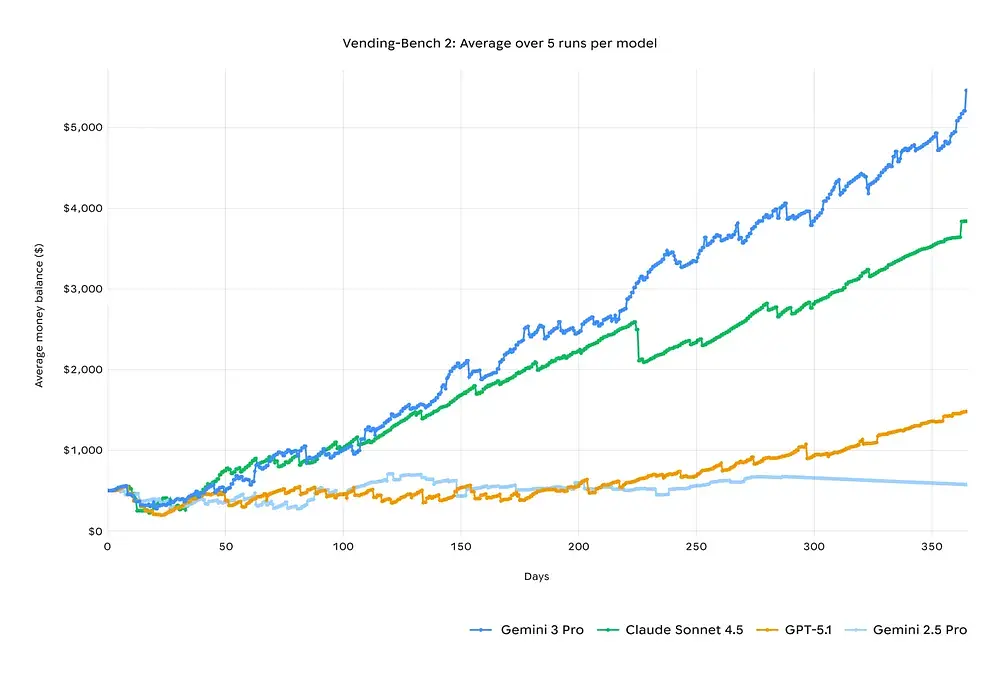
Practical difference
- For single-shot high-reasoning tasks (complex algorithmic debugging, deep logical proofs embedded in code), Gemini’s
thinking_leveland Deep Think promise greater single-response depth. - For long-duration, tool-driven automation (persistent agents running many commands, writing tests, iterating, and managing state), Claude Sonnet 4.5’s long-horizon focus and agent SDK are strong differentiators.
How do API access and pricing compare for developer use?
Gemini 3 Pro (Google) — access and pricing
- Access: Gemini 3 Pro preview is available via Google AI Studio and Vertex AI (model garden). SDKs include google-genai for Python/JS/Go/etc., plus OpenAI-compat layers for easier migration, with REST endpoints and function calling / code execution tools. Antigravity provides an IDE surface that uses Gemini 3 Pro in preview.
- Price: Preview pricing listed on Google docs: $2 / $12 per 1M tokens (input / output) for the <200k tier; higher rates for >200k (examples in docs show $4 / $18 for >200k).
Claude Sonnet 4.5 — access and pricing
- APIs & SDKs: Anthropic provides the Claude API, the Claude Agent SDK for building agentic workflows, file APIs, and code-execution tools (native VS Code extension, Claude Code improvements, and a “checkpoint” feature).
- Price: 200k-token default context window, 1M-token context in beta for enterprise; pricing $3 / $15 per 1M tokens (input/output respectively)
As a developer, you should choose a model based on your needs and its characteristics, not just the cheapest one. If the task can be handled by two models, decide based on the context.
If you want to use two models simultaneously, I recommend CometAPI, which provides both Gemini 3 Pro Preview API and Claude Sonnet 4.5 API, and is priced at 20% of the official price.
| Gemini 3 Pro Preview | GPT-5.1 | |
| Input Tokens | $1.60 | $2.4.00 |
| Output Tokens | $9.60 | $12.00 |
Final thoughts
Gemini 3 Pro (Preview) and Claude Sonnet 4.5 are both state-of-the-art choices for coding assistants in late 2025. Sonnet 4.5 edges out Gemini in specific software-engineering verification benchmarks and stamina on long-horizon tasks, while Gemini 3 Pro brings stronger multimodal understanding and deep agentic tooling that can execute in editor/terminal/browser environments. The right choice depends on whether your primary need is pure code reasoning and verification (Sonnet), or multimodal, agentic, tool-augmented development (Gemini). For enterprise-grade deployment, many teams will reasonably adopt a hybrid approach, using whichever model is strongest for a particular stage of the dev workflow.
Developers can access Gemini 3 Pro Preview API and Claude Sonnet 4.5 API through CometAPI. To begin, explore the model capabilities ofCometAPI in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
Ready to Go?→ Free trial of Gemini 3 pro and GPT-5.1 models !
If you want to know more tips, guides and news on AI follow us on VK, X and Discord!