

GLM-5-Turbo 是 Zhipu AI 推出的一款全新基础大语言模型,专门针对代理式工作流进行训练和调优(该公司将目标生态称为 OpenClaw / “lobster” 场景)。它提供超长上下文(最高约 ~200K tokens)、流式输出和结构化输出、更低的工具调用错误率(第三方测试报告约 ~0.67%),以及显著更低的单 token 价格。该模型旨在以少量单轮峰值吞吐能力为代价,换取更强的稳定性、工具可靠性、定时/持久任务处理能力和长链路执行能力——这对于自主代理、编排系统和多工具流水线尤其有用。
什么是 GLM-5-Turbo?
GLM-5-Turbo 被 Zhipu 定位为一款专为代理编排和复杂自动化工作流打造的基础模型,而不是通用聊天或多模态模型。其设计重点包括:
- 原生面向代理的训练(工具使用、命令遵循、定时/持久任务)。
- 极大的上下文窗口和输出容量,以支持长会话、记忆和思维链规划。
- 面向长业务流程和定时任务的稳定高吞吐推理。
不同于针对聊天或文本生成优化的传统大语言模型,GLM-5-Turbo 具有以下特征:
- 代理优先(而非聊天优先)
- 为 OpenClaw(“lobster”)环境打造
- 面向多步骤自主工作流设计
🦞 “Lobster Agent” 是什么意思?
“lobster” 这一概念指的是 OpenClaw,即 Zhipu 的 AI 代理生态,在这一生态中,模型可以:
- 动态使用工具
- 执行长链路任务
- 维护持久记忆
- 跨终端、应用和 API 运行
GLM-5-Turbo 针对这一范式进行了深度优化,重点解决以下代理核心问题:
- 工具调用可靠性
- 任务拆解
- 长周期规划
- 执行稳定性
关键特性及其重要性
长上下文 + 超大输出容量(200K / 128K)
200K token 的上下文窗口和 128K 的输出能力使 GLM-5-Turbo 可以:
- 保留更长的先前上下文记忆(对话、工具输出、中间结果)。
- 生成极长的产物(多阶段计划、长报告、代码库),而无需反复拼接上下文。
- 承载必须保留完整执行历史以进行准确决策的多轮代理。
对于代理而言,这是一项有意的技术选择——代理不必把任务拆成短提示,而是可以在数千轮对话或步骤中持续维护一致的状态。
训练中内建的代理原语
GLM-5-Turbo 不是将通用模型事后改造成代理模型,而是在训练时就引入了代理式目标(例如工具调用行为、命令/参数解析)。宣称带来的效果是:工具调用时幻觉更少、多步骤计划更稳定、长时间运行下延迟表现更好——这对于需要可靠串联多个外部 API 或工具的自动化场景尤为重要。
吞吐与执行稳定性
与通用大型模型相比,GLM-5-Turbo 在长业务流程中的执行稳定性和吞吐量有所提升——其宣传措辞强调“高吞吐执行”和同类模型中“领先的响应稳定性”。对于企业级代理部署而言,这一点很关键,因为某一步失败就可能导致整条流水线中断。独立第三方基准测试仍在逐步出现。
GLM-5-Turbo 的基准数据
注:Zhipu 已发布内部评测结果,也有针对 GLM-5 的第三方/学术基准可参考。GLM-5-Turbo 刚刚发布,独立社区基准测试还需要时间。以下列出的是当前最有依据、已公开的数据与背景。
GLM-5(参考)——具有代表性的公开指标
Zhipu 的 GLM-5(Turbo 的旗舰前代)在许多工程/工作流任务中表现强劲,例如:
- SWE-bench Verified: 77.8(GLM-5 文档中报告为领先的开源模型分数)。
- Terminal Bench 2.0: 56.2(报告为给定分布上的顶级开源模型表现)。
这些数据表明,GLM-5 在软件工程和执行类任务中是一个很强的基线;而 GLM-5-Turbo 的定位则是在一定程度上弱化纯参数规模/原始能力,换取更好的代理可靠性和吞吐表现。GLM-5-Turbo 在对比测试中显示出 ~0.67% 的工具调用错误率,显著低于作为对照的 GLM-5 供应商运行结果(约 ~2.33% 到 6.41%)。
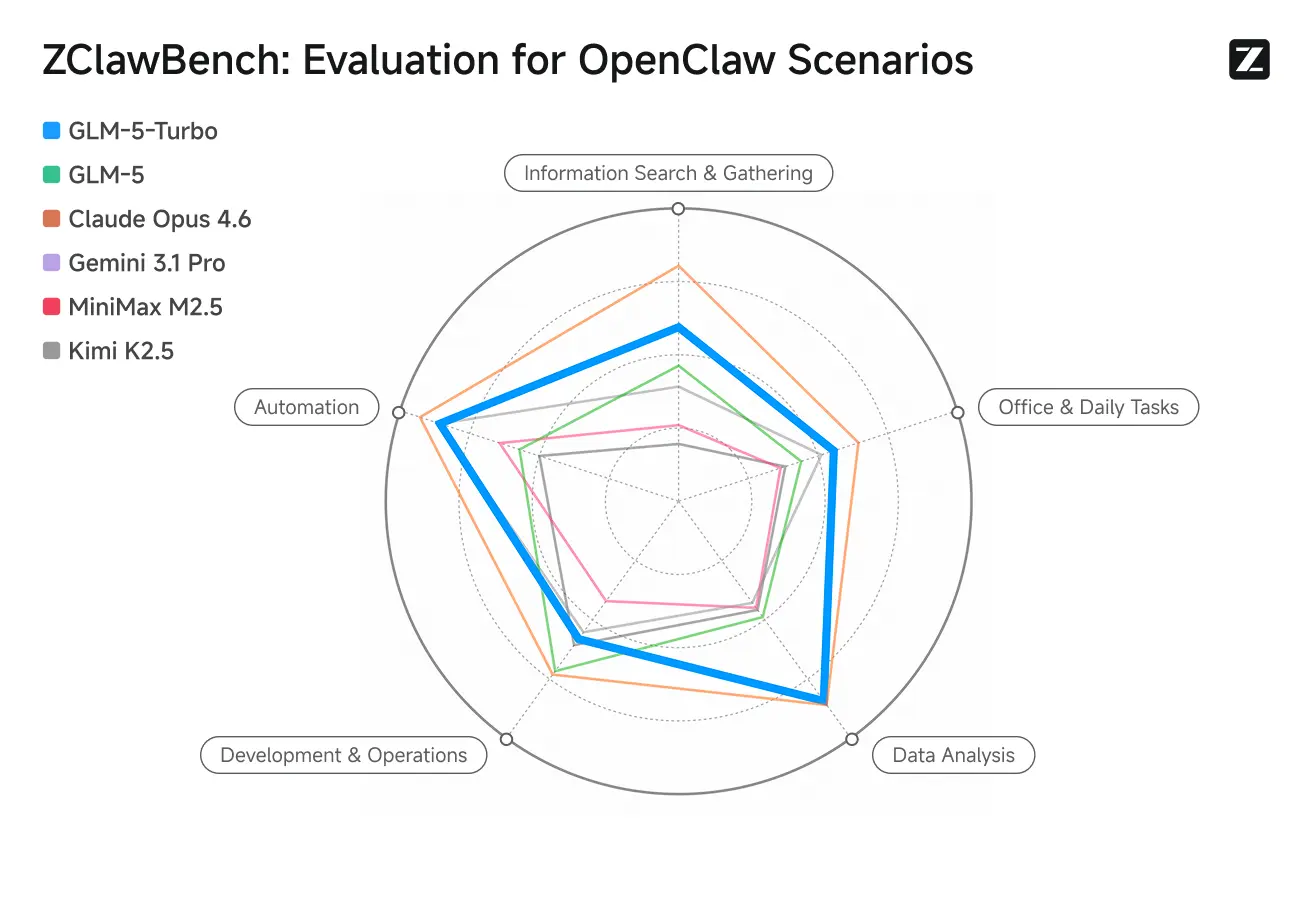
ZClawBench:面向 OpenClaw 代理场景的基准测试
Zhipu 还发布了用于评估智能代理的 ZClawBench 基准。在涵盖代码开发、数据分析、内容创作等多个领域的盲测中,代号为 Pony-Alpha-2 的新模型获得了 90% 受访者的青睐。
定价与可用性(由谁销售、价格多少)
Zhipu 在 GLM-5-Turbo 发布时实施了约 ~20% 的 API 价格上调,同时推出了“Lobster Package”订阅档位,用于平滑代理部署中的 token 成本。
已报道的订阅档位(示例套餐)
两个示例 Lobster 套餐(价格为报道中的换算值,近似):
- 入门 Lobster 套餐: ~39 CNY / 月(~US$5.66),包含 35,000,000 tokens。
- 中档 Lobster 套餐: ~99 CNY / 月(~US$14.36),包含 100,000,000 tokens。
根据这些公开数字,每 100 万 tokens 的成本约为:
- 入门套餐:~US$0.162 / 1M tokens
- 中档套餐:~US$0.144 / 1M tokens
这些每百万 token 的数字,是根据公开的订阅价格与 token 上限做的简单换算,用于说明高吞吐代理工作负载下的经济性。(计算基于媒体报道中的汇率与 token 数量。)
API 价格
代表性聚合平台(CometAPI)上的标价为:GLM-5-Turbo 输入 $0.96 / 1M tokens,输出 $3.20 / 1M tokens。
Zhipu 自家的(Z.ai)开发者定价页面则给出了略高的直连价格:GLM-5-Turbo 输入 $1.20 / 1M tokens,输出 $4.00 / 1M tokens(缓存输入价格更低)。
GLM-5-Turbo 与 GLM-5 对比
从高层来看:
- GLM-5 = 旗舰级通用基础模型(强推理、强编程、强基准表现)
- GLM-5-Turbo = GLM-5 的代理优化变体(聚焦长工作流、工具使用与稳定性)
GLM-5-Turbo 并不是一套全新的模型架构,而是 GLM-5 的一个专门化、面向生产优化的版本,专为 OpenClaw 这类代理系统设计。
核心定位
| 模型 | 定位 |
|---|---|
| GLM-5 | 通用旗舰 LLM(推理、编程、基准表现) |
| GLM-5-Turbo | 代理优先模型(自动化、编排、工具使用) |
👉 简单来说:
- 使用 GLM-5 → 当你想要最高智能水平
- 使用 GLM-5-Turbo → 当你想要稳定自动化 / 代理能力
代理能力对比(最重要)
GLM-5(代理能力方面)已经支持:
- 工具使用
- 多步骤推理
- 编程代理
但存在一些限制:
- 在长链路中可能丢失上下文
- 工具调用效果可能随时间退化
- 需要更多编排逻辑
GLM-5-Turbo 则是明确为代理优化的:
关键提升包括:
- 工具调用可靠性 ↑
- 任务拆解(规划)能力 ↑
- 长链一致性 ↑
- 持久执行支持 ↑
改进示例:
- 在10+ 步执行中保持稳定,不丢失上下文
👉 这对于以下场景至关重要:
- AutoGPT 风格系统
- 多代理工作流
- SaaS 自动化
速度与效率
| 方面 | GLM-5 | GLM-5-Turbo |
|---|---|---|
| 推理速度 | 中等 | 更快 |
| 吞吐量 | 标准 | 更高 |
| 长任务延迟 | 可能退化 | 已优化 |
GLM-5-Turbo 的设计目标之一,就是解决行业中的一个真实问题:
大模型在长工作流中会变慢,甚至失效
价格对比
| 模型 | 输入($/1M tokens) | 输出($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo 更贵(约高出 ~20%)
为什么更贵?
因为它提供了:
- 更好的编排可靠性
- 更高的生产稳定性
- 面向代理的专用优化
👉 在企业场景中:
- 你需要支付更高的单 token 成本
- 但能降低失败成本 + 重试成本
| 属性 | GLM-5 | GLM-5-Turbo |
|---|---|---|
| 主要目标 | 通用旗舰基础模型(能力广、编程强、基准表现好) | 面向 Agent / “OpenClaw” / lobster 优化的基础模型 |
| 上下文窗口 | (据称较大;GLM-5 也聚焦 ~200K 长上下文) | 200,000 tokens(文档明确说明) |
| 最大输出 tokens | (较大,取决于具体模型) | 128,000 tokens(文档说明) |
| 代表性基准分数 | SWE-bench:77.8;Terminal Bench 2.0:56.2(GLM-5 报告数据) | 内部评测宣称在代理工作流中具有更好的长链稳定性与吞吐;独立公开基准尚待补充。 |
| 模态 | 文本为主,GLM 系列在同系模型中也有视觉变体 | 仅文本(按文档)——针对基于工具的代理优化 |
| 推荐使用场景 | 广泛:聊天、代码、推理、内容生成 | 代理编排、工具调用、长周期自动化 |
| 定价 | 现有 GLM-5 定价(因套餐而异) | 新发布——据报道 API 价格上调约 ~20%,并引入新的 Lobster 订阅档位 |
如何使用 GLM-5-Turbo
CometAPI —— 单一 API 接入多个模型(兼容 OpenAI)
CometAPI 已列出 GLM-5-Turbo,并提供兼容 OpenAI 的 base URL 和 SDK。请使用其发布的模型字符串(网站上列出的 GLM-5-Turbo 价格也大致相当)。以下示例改编自 CometAPI 文档:
curl(CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // 或使用 CometAPI 界面中显示的准确模型 slug "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
CometAPI 的价值在于聚合便利性(一次集成即可接入多个模型)。实际调用前,请先在 CometAPI 控制台中确认准确的模型 slug。
使用 GLM-5-Turbo 构建 Lobster / OpenClaw 代理的最佳实践
- 为可靠性而设计,而不是只追求最低延迟: Turbo 的优势在于长链路中更低的工具调用失败率。设计代理运行时,应优先考虑稳健完成(重试、幂等工具调用),而不是只追求极小的首 token 延迟收益。
- 使用流式输出与增量式工具调用: 采用流式/分块输出可以减少返工,并在适当时支持尽早调用工具。GLM-5-Turbo 支持流式输出。
- 为解析器提供结构化输出: 优先使用 JSON 或格式良好的结果,以便下游工具进行确定性解析。Turbo 支持结构化输出。
- 为调度 / 持久化做好规划: 如果你的代理需要定期检查或运行后台任务,可利用 Turbo 更好的时间语义和缓存特性,避免每个周期都重新规划。
- 对工具调用与回退机制进行埋点: 记录工具调用,并设计优雅的回退逻辑(例如微调 temperature 后重试,或调用备用工具),因为代理工作流在单个外部 API 失败时往往非常脆弱。Turbo 能降低错误率,但无法消除外部故障。
开发者现在已经可以通过 CometAPI 访问 GLM-5 和 GLM-5 turbo API。开始之前,请查阅 API guide 获取详细说明。在访问前,请确保你已经登录 CometAPI 并获取了 API key。CometAPI 提供远低于官方价格的方案,帮助你完成集成。
准备开始了吗?→ 立即注册使用 GLM-5 和 GLM-5 turbo!