
.png&w=3840&q=75)
GPT-5.4 Mini 和 GPT-5.4 Nano 是 OpenAI 全新推出的 GPT-5.4 家族紧凑版本:Mini 面向代码、 多模态 UI 任务与子代理工作负载,在性能/延迟上实现业界领先的平衡;Nano 面向超低成本与超低延迟的分类、抽取、排序以及大规模并行子代理。Mini 在众多开发者基准上提供接近前沿的准确率,同时运行速度比以往 mini 提高超过 >2×;Nano 每个 token 明显更便宜,非常适合对吞吐与响应速度要求极高的场景。这些模型已在 API 上线(GPT 5.4 Mini 和 Nano 可在 CometAPI 获取)。
GPT-5.4 Mini 和 GPT-5.4 Nano 是什么?
简要定义: GPT-5.4 Mini 和 GPT-5.4 Nano 是 GPT-5.4 家族的紧凑工程化版本,旨在将大型 GPT-5.4 的核心能力(推理、编程、多模态感知、工具使用)带到更快、更低成本、针对高吞吐与低延迟工作负载的模型中。它们由 OpenAI 在 GPT-5.4 发布时一同宣布。
- GPT-5.4 Mini — 一款高性能小模型,“在多项评估上接近 GPT-5.4 的表现”,同时针对速度与成本进行优化。其在编码、推理、多模态 UI 理解(截图)以及作为智能体系统中的子代理方面尤为突出。OpenAI 报告称其相较此前的 “mini” 变体运行速度快超过 2×。
- GPT-5.4 Nano — 最小且最便宜的 GPT-5.4 变体;推荐用于分类、抽取、排序以及在极高吞吐下处理狭窄、重复任务的“支持型”子代理。它以更低延迟与成本为优先,牺牲部分深层推理能力。
可用性与价格
OpenAI 提供了两个可用于成本对比的具体数据点:
- GPT-5.4(旗舰完整型号)API 输入价格:$2.50 / 1M tokens(旗舰的输出价格更高)。
- GPT-5.4 mini API 输入价格:$0.75 / 1M tokens,输出 $4.50 / 1M tokens。
- GPT-5.4 nano API 输入价格:$0.20 / 1M,输出 $1.25 / 1M。
并排对比:mini 的输入 token 价格(0.75)是旗舰(2.50)的 30%,即输入成本约为三分之一;mini 的输出价格(4.50)约为 API 价格表中旗舰输出价格的 32%,同样约为三分之一。Nano 甚至更便宜:其输入成本约为旗舰输入成本的 8%,输出成本低于旗舰输出成本的 10%。这正是 OpenAI 将 mini/nano 定位为“约三分之一”(mini)与“只占一小部分”(nano)旗舰成本的原因。nano token 的价格从 $0.05 上调至 $0.20,mini token 的价格从 $0.25 上调至 $0.75(针对输入 token)。
在 OpenAI 平台
GPT-5.4 mini 可在三个地方使用:OpenAI API、Codex(OpenAI 的开发者 IDE/应用平台)和 ChatGPT(通过“Thinking”选项向 Free 与 Go 用户提供,并作为付费层的限流回退)。在 API 中,它支持文本与图像输入、工具使用(函数调用)、网页/文件搜索、电脑操作与技能,并提供非常大的上下文窗口(400k tokens),以满足文档密集与多截图工作流。API 的定价为每 1M 输入 tokens $0.75,每 1M 输出 tokens $4.50。
GPT-5.4 nano 仅通过 API 提供。其标价为每 1M 输入 tokens $0.20、每 1M 输出 tokens $1.25 —— 将其定位为 GPT-5.4 家族中成本最低的选择。nano 模型在能力上有意做出取舍,以换取成本与速度优势。
在第三方平台
CometAPI 是一个 AI API 多模态聚合平台,现已上线 GPT 5.4 系列 API,包括 GPT 5.4 Mini 与 GPT 5.4 Nano,价格较 OpenAI 官方低 20%。
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| 输入:$0.16/M; 输出:$1/M | 输入:$0.2/M; 输出:$1.25/M |
GPT 5.4 Nano:
| Comet Price (USD / M Tokens) | Official Price (USD / M Tokens) |
|---|---|
| 输入:$0.6/M; 输出:$3.6/M | 输入:$0.75/M; 输出:$4.5/M |
关键特性与新增内容
以下是工程师与产品团队最关心的能力亮点。
编码与长上下文支持
上下文窗口: GPT-5.4 mini 支持 400k token 上下文窗口(OpenAI 明确标注 mini 为 400k 上下文)。这足以应对多文件代码库、超长文档,或需要保留大量上下文的多轮智能体会话。Nano 的上下文相对完整 GPT-5.4 更小,但对于快速短任务仍相当可用。
推理
推理级别: OpenAI 提供可配置的 reasoning_effort(none → xhigh);mini 与 nano 可在不同强度下运行,而在更高强度时,mini 在多项推理基准上缩小至接近完整 GPT-5.4。于多项智能测评(如 GPQA Diamond)中,mini 达到 88.0%,对比 GPT-5.4 的 93.0%,而 nano 为 82.8%,显示出在小模型范畴内相当可观的推理能力。这些结果来自 OpenAI 的发布文章。
多模态理解(视觉与 UI)
视觉感知与 UI 任务: GPT-5.4 mini 在 UI 任务(截图、密集文档图像)上表现非常强劲。在 OSWorld-Verified(计算机使用基准)中,mini 得分 72.1%,更接近 GPT-5.4 的 75.0%,并远超此前的 mini——这也是 mini 被定位于基于截图的自动化与高响应多模态助手的原因。Nano 在视觉基准上更低,但对更简单的图像任务仍具价值。
工具调用与电脑操作
原生工具/点击能力: GPT-5.4 引入并扩展了原生电脑操作工具;mini 继承了调用工具、进行函数调用、解读截图与编排子代理的能力。工具调用基准(Toolathlon、MCP Atlas)显示 mini 与 nano 表现可观(Toolathlon:mini 42.9%,nano 35.5%)——量化了它们调用与协调外部工具的能力。这些指标来自 OpenAI 的公告。
幻觉/事实性/错误率
OpenAI 报告称 GPT-5.4 是“迄今最具事实性”的模型,并较 GPT-5.2 进一步降低了幻觉率;mini 与 nano 的绝对事实性低于完整模型(如 HLE w/ tools:GPT-5.4 52.1%、mini 41.5%、nano 37.7%),提示在高事实性任务中使用小模型需加强校验。当正确性至关重要时,请使用基于工具的核验(工具调用、引用回溯)。
速度
OpenAI 报告称 GPT-5.4 mini 在典型生产风格的延迟估计中(基于包含工具调用持续时间与抽样生成的模拟生产行为)比此前的 GPT-5 mini 快超过 2×。这一提速是该新家族的核心主张,使 mini 能在编码助手等交互式应用中作为高响应子代理使用。
mini 与 nano 表现如何——它们是否“接近”完整 GPT-5.4?
OpenAI 发布了覆盖编码、工具使用、多模态电脑操作、智能测试与长上下文评估的全面基准对比。核心数据(在适用时使用 xhigh 推理强度)包括:
| Benchmark | GPT-5.4 | GPT-5.4 Mini | GPT-5.4 Nano | GPT-5 Mini (Old) | Notes |
|---|---|---|---|---|---|
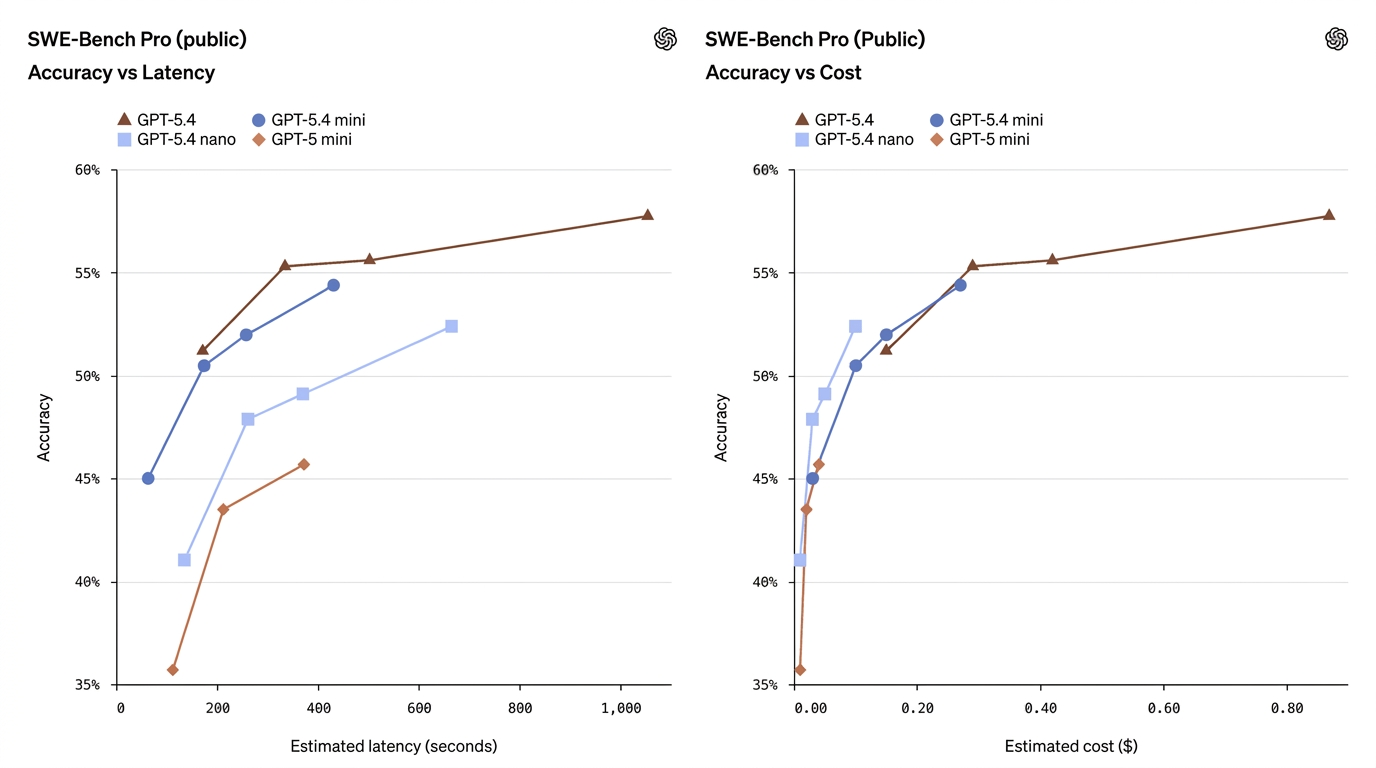
| SWE-Bench Pro (Coding) | 57.7% | 54.4% | 52.4% | 45.7% | Mini 接近完整模型的编码表现 |
| Terminal-Bench 2.0 (Interactive Coding) | 75.1% | 60.0% | 46.3% | — | Mini 具备强实时编码能力 |
| Toolathlon (Tool Use) | 54.6% | 42.9% | 35.5% | — | 衡量编排与工具调用能力 |
| GPQA Diamond (Advanced QA) | 93.0% | 88.0% | 82.8% | — | 智能与推理基准 |
| OSWorld-Verified (GUI Tasks) | 75.0% | 72.1% | 39.0% | 42.0% | UI/电脑操作能力 |
这些数据表明,mini 往往大幅缩小差距——尤其在编码与电脑操作任务上——而 nano 则在能力与成本之间占据一个有用的折中。
用通俗的话,这些数字意味着什么?
- GPT-5.4 Mini ≈ 许多生产任务上“接近旗舰”。 在 SWE-Bench Pro(编码通过率指标)中,mini 得分 54.4%,而旗舰为 57.7%——对许多真实世界编码任务而言,差距相对较小,尤其当延迟重要时。在 OSWorld(电脑使用)中,mini 为 72.1%,对比旗舰的 75.0%——同样在 UI/截图任务上非常接近。
- GPT-5.4 Nano 以速度/成本换能力。 Nano 的编码得分(SWE-Bench Pro 上 52.4%)相较旧款 mini 仍具竞争力,但其 OSWorld 得分降至 39.0%,显示在需要复杂多步 UI 理解或代理式工具序列的任务中,nano 并不合适。Nano 在单轮分类、抽取与小型辅助任务中更闪光。
- 工具使用有所提升,但仍敏感。 从 GPT-5 mini 切换到 GPT-5.4 mini/nano 后,Toolathlon 与其他工具使用指标显著提升,说明 OpenAI 在小型模型上改进了工具调用的可靠性——但在复杂工具编排方面,完整模型仍然领先。
它们如何在生产中工作
压缩、蒸馏与工程优化
如 mini/nano 这类紧凑模型通常结合 模型蒸馏、量化 与 架构剪枝,在降低推理计算的同时尽力保留高价值能力(编码启发、视觉感知)。OpenAI 的表述显示,其在小型体量中对特定技能(编码、多模态 UI 理解)进行了针对性保留与优化。
推荐模式
- 编排者 + 子代理模式: 使用 GPT-5.4(大模型)作为规划/评审者,将工作下发给 GPT-5.4 mini / nano 子代理以快速执行(搜索、解析、编辑)。这样既降低总体成本,又降低用户端延迟。OpenAI 明确推荐该设计模式。
- 回退与限流处理: 将 mini 作为 ChatGPT 或 Codex 中的限流回退,以便在完整模型不可用时,为时间敏感请求提供仍然可靠的回答。
- 分层架构控成本: 批量流水线(索引、抽取)→ GPT-5.4 nano;交互式 UI 组件 → GPT-5.4 mini;最终编辑判断/复杂链路 → GPT-5.4 完整模型。该多层策略在成本与能力之间取得平衡。
延迟与并行化
Mini 与 nano 针对 并行子代理 进行优化,即让大量小型工作者并发运行——例如并行扫描数千份 PDF。OpenAI 的“tool yields”概念衡量并行工具调用如何降低总体耗时;mini/nano 的工程设计使这些模式具备更高的性价比。
我该如何在实践中使用 mini 与 nano
我是否应该在所有地方用 mini/nano 替换旗舰模型调用?
不必然。OpenAI 明确推荐的正确模式是 委派:使用更大的模型进行规划、复杂判断或最终核验,并将许多支持性、短小的子任务下发给 mini 或 nano 子代理。这种模式在保留大模型关键护栏的同时降低成本与延迟。适用场景:
- 交互式编码助手: 旗舰负责规划与代码审阅;mini 负责快速代码搜索、编辑与短小单元测试。
- 基于截图的“电脑使用”代理: mini 可快速解析密集界面;旗舰用于解决含糊的多步规划。
- 高容量抽取与分类流水线: nano 处理海量批次输入(表单、日志)并返回结构化结果;旗舰处理异常与复杂边界情况。
mini 或 nano 可用于多模态或图像任务吗?
可以——mini 支持图像输入,并在多模态/视觉基准(MMMUPro/OmniDocBench)上表现良好,在部分测试上接近旗舰。Nano 的多模态能力更有限:尽管优于旧款 nano,但不适合需要深度多模态推理或代理式图像任务的场景。
小型模型能力之战愈演愈烈
三个月前,小模型还被认为“差不多够用”。如今,GPT-5.4 mini 在编程基准上已逼近旗舰模型,并在计算性能上几乎与之匹敌。
背后的趋势十分清晰:旗舰模型的能力正在快速迁移到更小的模型上。OpenAI、Google 与 Anthropic 都在做同样的事情:将大型模型的核心能力蒸馏到更小、更快、更便宜的版本中。
结论
这两款模型的发布标志着 AI 应用从“规模导向”向“实用效率导向”的转变。通过快速响应能力,它们为实时交互与复杂任务流的拆解提供了更可靠的底层支撑。
对开发者而言,这意味着智能体系统的成本结构正在被重新定义。当成本降至这一量级,许多此前“理论可行但经济上不可行”的代理场景将变得可行。
开发者现在可通过 CometAPI 访问 GPT 5.4 Mini 与 GPT-5.4 Nano(CometAPI 是一个聚合 GPT APIs、Nano Banana APIs 等大模型 API 的一站式平台)。在访问前,请确保已登录 CometAPI 并获取 API key。CometAPI 提供远低于官方的价格,帮助你集成。
准备好出发了吗?