

Luma AI 的 Uni-1 不仅仅是一个新的文生图模型。按照 Luma 自己的定义,它是一个“能够生成像素的多模态推理模型”,建立在“统一智能”之上,因此它可以理解意图、响应指令,并且“与你一起思考”。该公司的技术报告称,这个模型使用的是仅解码器自回归 Transformer,其中文本和图像以单个交错序列表示,并且 Uni-1 能够在图像合成之前和过程中执行结构化的内部推理。正是这种组合,使 Uni-1 成为 2026 年最值得关注的图像模型发布之一。
什么是 UNI-1 图像模型?
Uni-1 是 Luma AI 面向那些需要在同一个系统中同时完成理解与生成任务而推出的新图像模型。Luma 将其定位为多模态推理模型,而不是传统的仅基于扩散的图像引擎,这一点很重要,因为该模型的目标不只是产出视觉上令人满意的结果:它被设计用于解释指令、保留参考约束,并在生成过程中对场景逻辑进行推理。公司的技术报告将 Uni-1 描述为其迈向多模态通用智能道路上的第一个统一理解与生成模型。
为什么 Uni-1 与众不同
旧的流程有其上限:没有理解能力的图像生成只能走到一定程度。Uni-1 被呈现为迈向“统一智能”的一步,在这种范式下,语言、感知、想象、规划和执行都在同一架构内处理。这不仅仅是品牌包装。Uni-1 可以从视觉相似性进一步走向有意图的构图、合理性和场景逻辑。
更大的趋势是,图像模型正变得更具代理性。Google 最新的图像栈现在强调对话式编辑、搜索锚定、多图融合和角色一致性;OpenAI 的 GPT Image 系列则强调原生多模态和指令跟随。Uni-1 也加入了这一转变,但它更进一步地强调模型在作画之前应该对图像进行“思考”。这使得 Uni-1 对那些精度和可复现性与视觉表现同样重要的工作流尤其有吸引力。
Uni-1 实际上是如何工作的?
🔬 标记化过程
- 文本 → token 序列
- 图像 → 标记化图像块
- 合并为单个交错序列
🔁 生成过程
- 输入提示词 + 参考图
- 模型执行内部推理
- 规划构图
- 按顺序生成 token
数学表达:P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 内部推理层
Uni-1:
- 分解指令
- 解决约束冲突
- 在渲染前规划布局
👉 与扩散模型相比,这是一次重大飞跃。
仅解码器自回归生成
最重要的技术细节是,Uni-1 是自回归的,而不是基于扩散的。Luma 的技术报告称,它是一个仅解码器自回归 Transformer,并且文本和图像被编码为单个交错序列。用通俗的话说,这个模型并不是简单地从噪声开始,再逐步“去噪”生成图像。相反,它是一步一步生成 token,这使模型能够在渲染之前和过程中对提示词进行推理、解决约束并规划构图。
🔬 标记化过程
- 文本 → token 序列
- 图像 → 标记化图像块
- 合并为单个交错序列
扩散 vs 自回归
| 特性 | 扩散模型 | Uni-1(自回归) |
|---|---|---|
| 生成方式 | 噪声 → 图像 | 逐 token 生成 |
| 推理能力 | 有限 | 强 |
| 编辑 | 弱 | 多轮 |
| 文字渲染 | 差 | 强 |
| 控制能力 | 低 | 高 |
核心架构
Uni-1 是:
- 仅解码器自回归 Transformer
- 文本 + 图像共享 token 空间
这种架构之所以重要,是因为当提示词变得复杂时,它给了模型保持连贯性的机会。Luma 表示,Uni-1 可以分解指令、解决冲突约束,并在开始渲染之前规划图像。这对结构化场景补全、多主体摆放、多轮细化,以及那些要求输出既忠于参考图像又服从新指令的编辑任务尤其有用。
这个模型似乎被设计得更擅长做什么
学会生成图像会提升理解能力。Luma 表示,模型的图像生成训练能够实质性提升细粒度视觉理解,尤其是在区域、对象和布局方面。因此,Uni-1 不是被当作一个单向生成器,而是被视为一个其生成能力与理解能力彼此增强的统一系统。从推理角度来看,这意味着 Uni-1 正试图缩小“看见”和“制作”之间的差距。与扩散模型相比,这是一次重大飞跃。
生成过程:
- 输入提示词 + 参考图
- 模型执行内部推理
- 规划构图
- 按顺序生成 token
数学表达:P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Uni-1 提供了哪些功能和核心优势?
强大的指令跟随能力与可控性
Uni-1 最大的卖点是控制力。该模型是为精确编辑、结构化参考使用和可复现工作流而构建的。对于创作者来说,这意味着更少依赖“碰运气式”的提示词尝试,更多获得可复现的输出。
Uni-1 的一个实际优势在于它是为可控迭代而设计的。Seed 允许用户复现结果,而参考角色则帮助模型理解一张图像应该引导角色身份、氛围、色板还是构图。这使 Uni-1 比纯提示词驱动模型更容易操控,尤其适合那些制作广告、分镜、产品样机或品牌资产、并且重视一致性的团队。
保持身份一致的参考驱动生成
一个重要优势是参考处理能力。Luma 明确表示,Uni-1 使用基于源锚定的控制方式,并且能够保留一个或多个参考中的身份、构图和关键视觉约束。这使它对品牌角色、产品样机、营销素材,以及任何要求主体在多个变体中仍保持可识别性的商业工作流都很有吸引力。这也是 Uni-1 与那些更偏审美导向图像系统最明显的区别之一。
文化理解力与风格广度
Luma 还强调其具备文化感知生成能力。其 “Cultured” 部分展示了 meme、manga、电影感风格、随手拍照片、体育和动物图像,表明该模型旨在跨多种视觉语言运作,而不是局限于某一种通用风格。这很重要,因为一个优秀的现代图像模型不只是要能渲染真实场景;它还需要理解互联网文化、编辑设计、风格化插画和社交媒体内容的视觉惯例。
作为设计选择的多模态思维
真正的差异化点不仅在于 Uni-1 能生成图像,更在于 Luma 将图像生成定义为一项推理任务。Uni-1 能执行结构化内部推理,而且“学习生成图像”会提升其对区域、对象和布局的细粒度视觉理解。这表明,这个模型的目标是在渲染之前先理解场景,而不是仅仅通过统计方式近似提示词。
性能基准
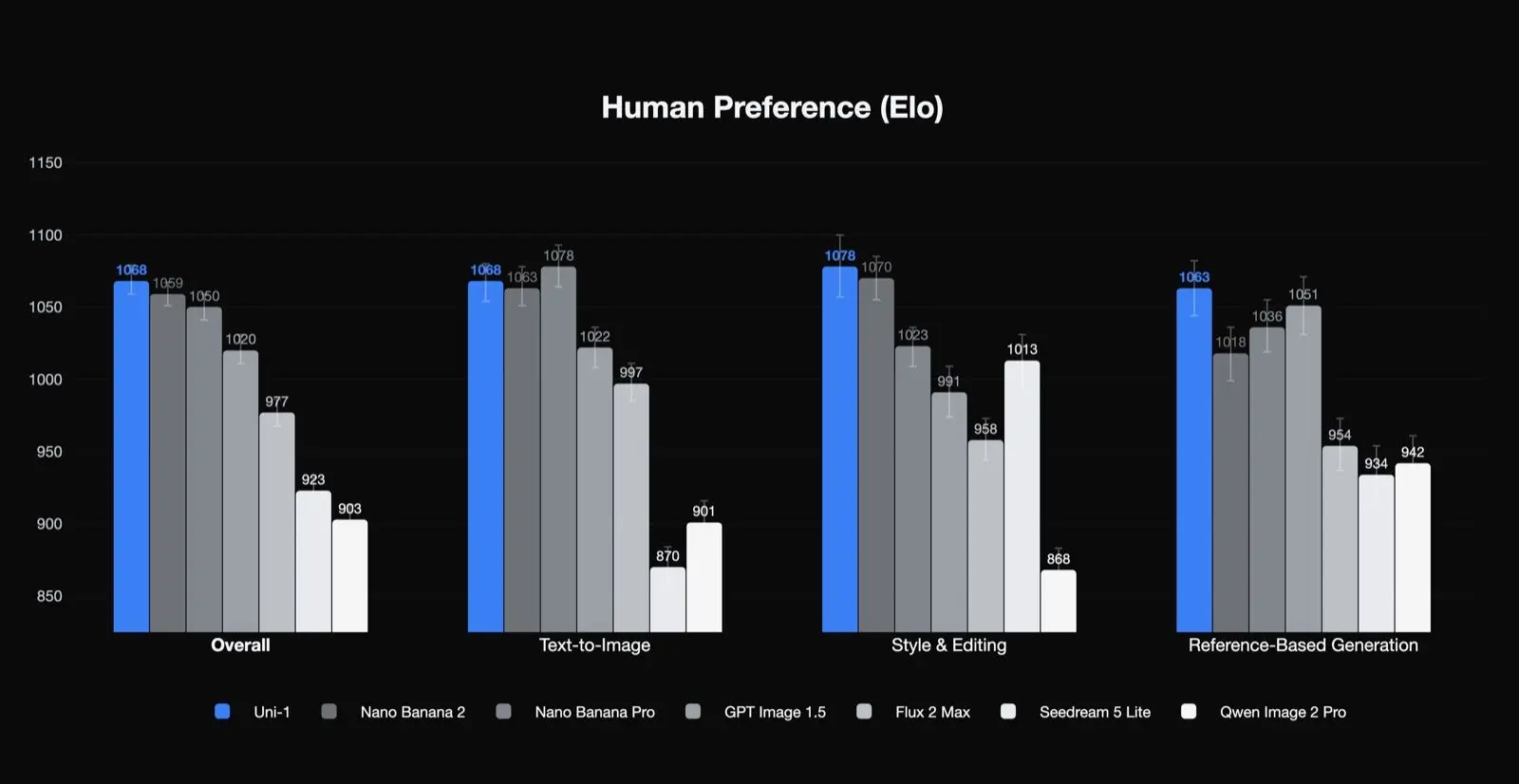
Luma 自身的人类偏好结果
Uni-1 在总体质量、风格与编辑、以及基于参考的生成这几项的人类偏好 Elo 排名中位列第一,在文生图方面位列第二。这是一个有意义的结果,因为它表明,该模型在生产团队最关心的任务类型上尤其强:编辑、一致性和受引导的变换。这也意味着,它最好的应用场景可能并不只是单次的一步式文生图。
RISEBench:基于推理的信息化视觉编辑
最吸引眼球的基准测试是 RISEBench,它评估的是基于推理的信息化视觉编辑能力,涵盖时序、因果、空间和逻辑推理。关于 Luma 发布会的第三方报道指出,Uni-1 在 RISEBench 上的总分为 0.51,领先于 Google 的 Nano Banana 2(0.50)、Nano Banana Pro(0.49)以及 OpenAI 的 GPT Image 1.5(0.46)。在空间推理方面,据称 Uni-1 为 0.58,而 Nano Banana 2 为 0.47。在逻辑推理方面,据称 Uni-1 为 0.32,超过 GPT Image 1.5 的 0.15 一倍以上。总体差距不算特别大,但在最困难的推理类别中差距相当明显。

ODinW-13 与“生成提升理解”的论点
Uni-1 在 ODinW-13(一个开放词汇密集检测基准)上也表现强劲。关于 Luma 技术数据的报道指出,完整模型获得了 46.2 mAP,几乎追平 Google 的 Gemini 3 Pro 的 46.3。同样的报道还称,仅理解版本获得了 43.9 mAP,这意味着生成训练将理解能力提升了 2.3 个点。这一发现值得关注,因为它支持了 Luma 的核心论点:图像生成与图像理解可能是相互增强的目标,而不是彼此竞争的目标。
Uni-1 API 价格
| 输入价格(文本) | $0.50 |
|---|---|
| 输入价格(图像) | $1.20 |
| 输出价格(文本与思考) | $3.00 |
| 输出价格(图像) | $45.45 |
在消费者侧,Luma 的定价页面列出了 Plus 为 $30/月,Pro 为 $90/月,Ultra 为 $300/月,并且各档计划都包含免费试用额度。这意味着实际上有两层定价需要考虑:平台的消费者会员价格,以及用于生产环境的模型级 API 定价。
目前,CometAPI 的 Uni-1 API 显示为 Available Soon,并承诺上线时提供折扣。当前,CometAPI 也提供优秀的原始图像模型,例如 Midjourney 和 Nano Banana 2。
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 对比 Google 的 Nano Banana 2
Nano Banana 2 在参考处理广度和生态系统集成方面看起来更强。Google 强调图像搜索锚定、对话式迭代以及最多支持 14 张参考图的重参考工作流。相比之下,Uni-1 更明确地围绕推理、场景合理性以及统一模型架构中的精确编辑来构建。从实际角度看,Google 似乎针对速度、主流生产规模以及原生 Google 锚定做了优化;而 Luma 则似乎针对结构化视觉推理和可操控的图像编辑做了优化。
在围绕 Uni-1 的公开比较中,这种取舍很明确:Nano Banana 2 在纯文生图质量和速度方面似乎依然很强,而 Uni-1 则更侧重推理密集型编辑、参考控制和指令忠实度。
Uni-1 对比 OpenAI 的 GPT Image
在基准测试报道中,Uni-1 在 RISEBench 总体上略胜 GPT Image 1.5,并且在逻辑推理方面优势更明显。与 OpenAI 的 GPT Image 系列相比,Uni-1 的定位更聚焦,也更激进地围绕视觉推理和可控编辑展开。OpenAI 的文档强调世界知识、多模态理解和上下文感知;Luma 的文档则强调结构化内部推理、参考锚定控制以及经过基准验证的视觉编辑能力。因此,尽管两者都是多模态模型,Uni-1 更明显是“图像专精型推理模型”,而 GPT Image 更像是一个恰好也非常擅长生成图像的通用多模态系统。
三者之间的价格比较
在价格方面,比较取决于输出尺寸和产品层级,因此并非完全可直接对比。Uni-1 公布的 2048px 等效价格约为每张图 $0.0909。Google 最新的图像模型定价页面列出,其最新 Gemini 图像预览模型的价格为每张 1K/2K 图像 $0.134、每张 4K 图像 $0.24;而 OpenAI 的 GPT Image 定价页面列出的逐张图像输出价格为:1024x1024 低质量 $0.011,中质量 $0.042,高质量 $0.167,更大尺寸的高质量输出为 $0.25。换句话说,OpenAI 在低端价格上可能便宜得多,Google 在速度和规模端非常激进,而 Uni-1 则处于中间位置,在 2K 场景下具有很强的价格性能比。
理念差异
| 模型 | 方法 |
|---|---|
| Uni-1 | 统一多模态智能 |
| GPT Image | LLM + 图像生成 |
| Nano Banana 2 | 面向生产优化的扩散模型 |
详细对比表
| 特性 | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| 架构 | 自回归 | 混合 | 扩散 |
| 多模态统一 | ✅ 原生 | 部分 | ❌ |
| 推理能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 图像质量 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 文字渲染 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| 编辑工作流 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 速度 | 中等 | 快 | 快 |
| 控制能力 | 高 | 中 | 中 |
CometAPI 提供 GPT Image 1.5、Nano Banana 2 以及即将推出的 Uni-1 的交互式原始图像能力,以及 API 编程支持。折扣定价和按量付费选项使其成为开发者偏好的选择。
Uni-1 最适合什么
Uni-1 看起来尤其适合那些需要可复现性、角色一致性或多参考控制的场景。这包括品牌营销活动、产品样机、编辑概念图、分镜、本地化变体,以及那些要求构图保持不变、但风格或环境需要变化的图像编辑。Luma 自己的示例也高度聚焦这些用例,而该模型的 “Create vs Modify” 区分,基本上就是对常见生产痛点的直接回应。
如果你的工作主要是“根据单个提示词做出一张漂亮图”,那么它的差异化优势可能不会显得那么明显。但如果你的工作流是“做出五个相关版本,保持同一个角色,保留构图,改变光线,并且下周还能复现”,那么 Uni-1 的设计就会显得非常合理。这是一个推断,但它很自然地来自于 Luma 所强调的控制特性。
使用 Uni-1 获得更好结果的最佳实践
首先要使用正确的模式。Luma 的指导很简单:当你想创建一个新场景时使用 Create,当你想保留现有场景时使用 Modify。混用这两种意图会让输出更不稳定。
像专业人士一样使用参考标签。Luma 推荐使用诸如“Use IMAGE1 as a STYLE reference”或“Use IMAGE2 as LIGHTING”这样的表述。当每张参考图都有明确职责时,模型表现会更好,而不是给出模糊的“灵感来源”。
找到满意结果后就锁定 seed。Luma 明确建议,先在不设 seed 的情况下探索,等得到强结果后再保存该 seed。之后,每次只改变一个变量。这是将生成转化为可控生产系统的最简单方式。
要具体,要明确。Luma 提醒不要使用像“beautiful”或“amazing”这样模糊的词,而是鼓励使用具名美学描述,例如“1970s Italian giallo film poster”,或者精确的相机风格提示。实际中,具体的提示词通常优于诗意化提示词,因为模型可以锚定在真实结构上。
使用 Create → Modify 链路。Luma 明确表示,这是其最强大的工作流之一:先在 Create 中探索,再在 Modify 中细化。对于严肃的生产工作来说,这正是最佳甜点区,因为它能减少返工,并在保留构图优点的同时收紧细节。
最终结论
Uni-1 是 Luma 迄今为止最明确的一次表态:图像生成正在从“输入提示词,输出图片”迈向“由推理引导的视觉创作”。它公开展现出来的优势在于控制力、参考处理、可复现性,以及一种让语言和像素共处于同一系统中的模型架构。
对于那些关注高点击视觉产出、角色一致性、精确编辑以及高分辨率价格透明度的创作者和团队来说,Uni-1 绝对是一个值得关注的模型。如果 API 的落地发布足够顺利,它有可能在 2026 年成为 Google 的 Nano Banana 2 和 OpenAI 的 GPT Image 1.5 之外最有趣的替代选择之一。
准备开始创建原始图像了吗?CometAPI 这个多模态模型 API 的一站式聚合平台欢迎你!