

Google 于 2026 年 5 月 19 日在 I/O 大会上发布了 Gemini 3.5 Flash,将其定位为一款高智能、速度优化的模型,面向智能体工作流、编码与多模态任务中的持续前沿性能。它在 Gemini 3 Flash 的基础上升级,引入增强的“思考等级”(thinking levels),用于在质量、成本与延迟之间取得平衡。
本指南将全面覆盖:Gemini 3.5 Flash 是什么、关键特性、详细基准表现、定价、与 GPT-5.5、Claude 4.7/4.6 等的对比等。作为领先的 AI API 聚合平台,CometAPI 通过统一计价、简化集成与成本优化工具,帮助开发者接入 Gemini 3.5 Flash(及其竞品)。
Gemini 3.5 Flash 是什么?
Gemini 3.5 Flash 在 Gemini 3 Flash 的推理基础上,加入增强的“思考等级”(minimal、low、medium/default、high),以精细调节质量-延迟-成本之间的权衡。它是原生多模态模型,支持文本、图像、视频、音频与文档(含 PDF),具备 1M token 上下文窗口与最高 65K 输出 token。知识截止时间为 2025 年 1 月。
相较以往 Flash 模型的关键差异点:
- 在智能体、编码与长时程任务上具备持续前沿性能
- 思路保留(Thought preservation):无需额外 API 改动,即可在多轮对话中自动维持中间推理
- 为规模化优化:面向并行智能体执行、迭代式编码与多步骤企业工作流而设计
- 暂不支持 computer use(但工具使用与函数调用能力有明显增强)
Google 将其定位为面向生产的“最智能 Flash 模型”,在多项智能体与编码基准上超越此前的 Gemini 3.1 Pro,同时保持 Flash 级速度(测试中常见 >280 输出 tokens/秒)。
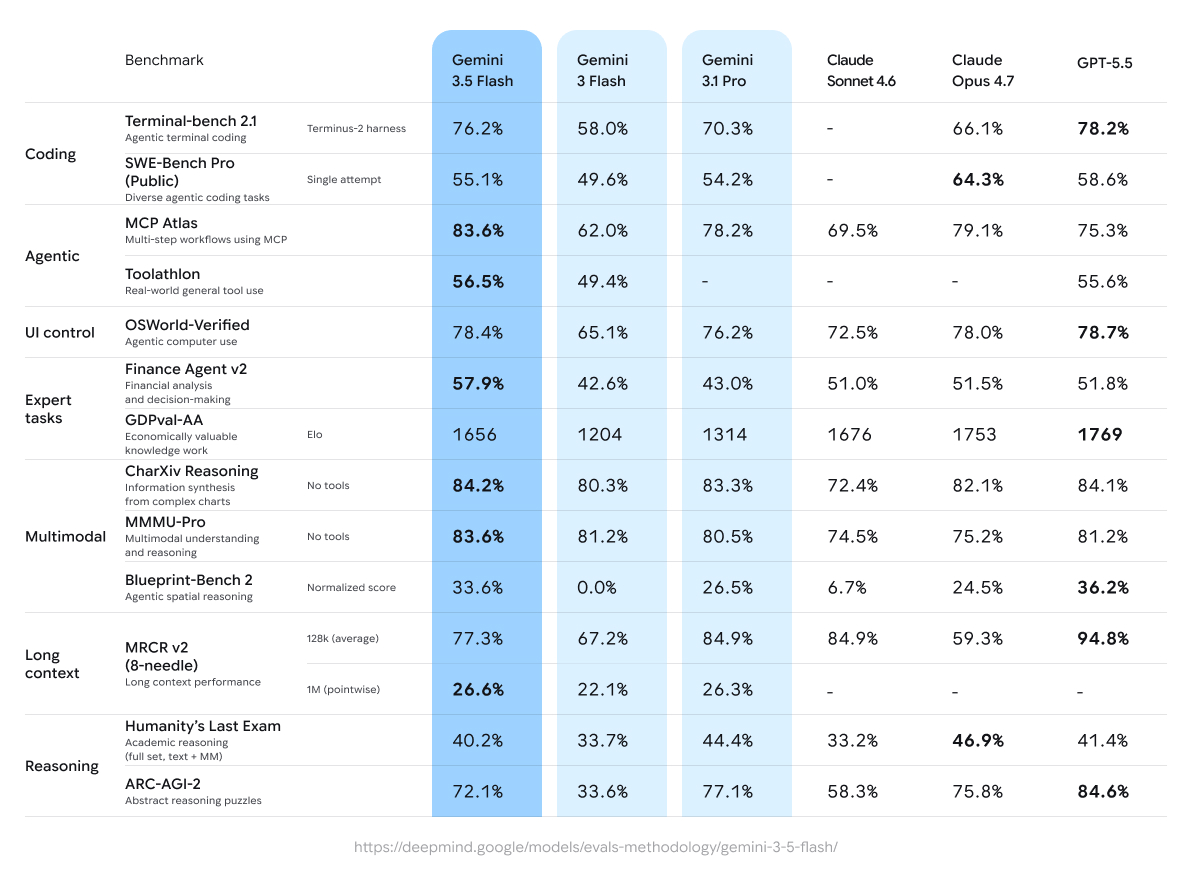
Gemini 3.5 Flash 在智能体工作流与编码方面表现突出,以优化的延迟与成本接近 Pro 级智能水平,在 Terminal-bench 2.1 取得 76.2%,在 MCP Atlas 多步骤任务上取得 83.6%。
基准性能突破
独立测试确认:它在更高速度下可实现 Pro 级或更强的编码/智能体任务表现;但由于复杂智能体循环中会消耗更多 token,且相较更早的 Flash 模型价格上调 3 倍,整体跑分成本也会随之上升。
Gemini 3.5 Flash 相比前代提升显著,尤其在智能体与编码领域。以下为 Google DeepMind 模型卡与独立评测(截至 2026 年 5 月)的关键结果:
部分基准(Gemini 3.5 Flash vs. 对比模型):
编码:
- Terminal-bench 2.1(智能体终端编码):76.2%(对比:Gemini 3 Flash 58.0%、Gemini 3.1 Pro 70.3%、GPT-5.5 78.2%)
- SWE-Bench Pro(公开,多样化智能体编码):55.1%(对比:3 Flash 49.6%、3.1 Pro 54.2%)
智能体工具使用:
- MCP Atlas(多步骤工作流):83.6%(明显领先)
- Toolathlon(真实世界通用工具使用):56.5%
- Finance Agent v2:57.9%(相比 3 Flash 大幅提升 +15.3%)
多模态:
- CharXiv(图表推理):84.2%
- MMMU-Pro:83.6%(领先众多竞品)
推理与长上下文:
- Humanity’s Last Exam:40.2%
- ARC-AGI-2:72.1%
- MRCR v2(128k):77.3%;1M 上下文 pointwise 为 26.6%。
Artificial Analysis Intelligence Index:Gemini 3.5 Flash(高思考)得分 55,较 Gemini 3 Flash 提升 9 分。其在“智能 vs. 速度”的帕累托前沿上领先,在智能体任务上提升并降低幻觉(幻觉率降至 61%)。它可实现 >280 输出 tokens/秒,但在智能体循环中会带来更高 token 使用量。
它在长上下文(MRCR v2 与 1M pointwise 表现强)、多模态领先(图表、文档)与持续智能体表现方面优势明显,并在部分工作流中减少 token 浪费(例如在 cyber 基准上提升 42%,同时 token 使用减少 72%)。
速度与智能体能力的平衡
Gemini 3.5 Flash 在速度-智能权衡上表现突出:在保持高吞吐(>280 tokens/s)的同时,支持复杂智能体行为,如子智能体部署、并行执行与快速迭代。
默认思考强度现在是 medium,与 Gemini 3 Flash Preview 的 high 相比有所调整。
**思考等级(Thinking Levels)**支持精细控制:
- Medium(默认):适用于多数复杂编码与智能体任务的最佳平衡
- High:面向最困难问题的深度推理最大化
- Low/Minimal:用于更简单查询的超低延迟
Google 报告在真实智能体场景中 token 效率显著提升(例如在部分 cyber 基准相对先前版本减少 72%),使其更适合长时间持续运行的工作流。
权衡点:相较以往 Flash 价格更高,在 token 密集的智能体场景中总体成本会上升(相对 Gemini 3 Flash,Intelligence Index 成本约为 5.5 倍,原因是定价上调 + 使用量增加)。
智能体能力增强
Gemini 3.5 Flash 推动“Gemini 智能体时代”。关键增强包括:
- 并行智能体执行循环:为复杂问题部署多个子智能体
- 迭代式编码与原型开发:结合动态工具使用快速探索解法路径
- 长时程多步骤工作流:依托思路保留处理延展性企业流程
- 工具使用改进:更严格的函数响应匹配、多模态函数响应,并通过更好的提示与更低的思考等级减少不必要调用;在 OSWorld 与 UI 任务上表现强
它为 Google 的新信息智能体、自主研究与编码流水线提供动力。内部测试显示,它擅长构建复杂系统并管理研究项目。
对开发者而言,新的 Interactions API(beta)简化了服务端历史管理,类似其他生态中的高级模式。
CometAPI 推荐:使用我们的统一 API,将 Gemini 3.5 Flash 与专用模型(例如用 Claude 做深度代码审查,或用 GPT 处理创意任务)在智能体系统中进行链式编排。我们的路由与回退能力可提升可靠性并节省成本。
多模态领先
Google 继续保持多模态理解领先地位。Gemini 3.5 Flash 可原生处理并推理文本 + 图像 + 视频 + 音频 + 文档,在 CharXiv、MMMU-Pro 与视频理解等任务上领先或与顶级模型竞争激烈。
应用场景:图表/数据综合、视频分析、多模态函数调用(例如在工具响应中处理图像)、富媒体智能体。适用于电商、内容创作、科学可视化等应用。
定价:Gemini 3.5 Flash 多少钱?
Gemini API 定价(每 1M tokens,近似全球价格):
- 输入(文本/图像/视频/音频):$1.50
- 输出:$9.00
- 上下文缓存(Context caching):$0.15(对重复提示可显著节省)
这相较 Gemini 3 Flash Preview($0.50/$3)约上涨 ~3 倍,但在能力跃迁下仍具竞争力。其价格接近 Gemini 3.1 Pro($2/$12),同时在许多工作负载中速度更快。
企业/Agent Platform 分层可能随用量折扣与附加功能而变化。使用缓存输入与高效提示(更低思考等级、优化历史)可显著控制成本。
这相较 Gemini 3 Flash Preview($0.50/$3)约上涨 ~3 倍,但在能力跃迁下仍具竞争力。其价格接近 Gemini 3.1 Pro($2/$12),同时在许多工作负载中速度更快。
免费层:可通过 Google AI Studio/Gemini app 获取有限访问;生产使用需付费。
Cometapi 优势:在 Gemini 3.5 Flash API 之外,还可用有竞争力的费率接入 100+ 模型,并提供用量分析与优化工具以减少 token 开销。我们的平台常通过智能路由与批处理带来更优的实际价格。API 价格通常比官方价格低 20%。
Gemini 3.5 Flash vs. GPT-5.5、Claude 4.7/4.6 等
Gemini 3.5 Flash 的优势:
- 速度 + 智能体平衡:推理速度快于多数前沿模型,同时缩小智能差距
- 多模态 & 长上下文:原生 1M 上下文与视觉能力领先
- 规模化成本优势:在许多工作负载中单 token 成本低于顶级 Claude/GPT,尤其结合缓存时
- Google 生态:与 Search、Workspace、Cloud 的无缝集成
竞品更强的方面:
- GPT-5.5 往往在纯推理(例如 ARC-AGI)更领先,并可能具备更强的创意/通用能力
- Claude Opus 4.7/Sonnet 4.6 在谨慎编码(某些情况下 SWE-Bench 更高)与细腻写作/安全性方面更突出
- token 效率存在差异;智能体循环可能使 3.5 Flash 的总体成本更高
高层对比(近似/节选指标;请始终核对最新榜单):
| 基准 / 指标 | Gemini 3.5 Flash | GPT-5.5 | Claude Opus 4.7 / Sonnet 4.6 | Gemini 3.1 Pro | 备注 |
|---|---|---|---|---|---|
| Terminal-bench 2.1(编码) | 76.2% | 78.2% | ~66% | 70.3% | 智能体编码 |
| MCP Atlas(智能体) | 83.6% | 75.3% | 79.1% / 69.5% | 78.2% | 多步骤工作流 |
| GDPval-AA(智能体知识) | 1656 Elo | 1769 | 1753 | 1314 | 经济价值 |
| MMMU-Pro(多模态) | 83.6% | 81.2% | ~75% | 80.5% | Gemini 优势明显 |
| Intelligence Index(AA) | 55 | 高(有波动) | 具竞争力 | 更低 | 速度/智能帕累托 |
| 速度(tokens/s) | >280 | 更低 | 不固定 | 更慢 | Flash 优势 |
| 输入/输出价格($/1M) | 1.50 / 9.00 | 更高 | 更高(尤其 Opus) | 2/12 | 具成本优势的前沿能力 |
| 上下文窗口 | 1M | 具竞争力 | 强 | 1M+ | 均为前沿级别 |
权衡总结:
- Gemini 3.5 Flash 在速度 + 多模态 + 规模化智能体效率方面领先
- GPT-5.5 往往在纯推理/编码峰值能力上略胜
- Claude 4.7 Opus 在谨慎、高可靠编码上优势明显,但成本/延迟更高
Gemini 常在多模态与特定智能体套件上领先或持平,同时更快、在高吞吐场景更具性价比。
如何访问与集成 Gemini 3.5 Flash
可通过以下方式接入:
- Gemini App / Google AI Studio
- Gemini API(
gemini-3.5-flash) - Google Cloud Vertex AI / Enterprise Agent Platform
- 第三方聚合平台以获得多供应商灵活性
CometAPI 推荐:用于 Cometapi.com 的生产应用时,可用单一 API Key 一次集成,访问 Gemini 3.5 Flash(以及来自 OpenAI、Anthropic、xAI 等的 500+ 模型),获得 20–40% 更低的实际定价、无厂商绑定与便捷的模型切换能力。
你的项目可获得的收益:
- 仅需更改模型名即可即时对比 Gemini 3.5 Flash 与 GPT-5.5 或 Claude 4.7
- 统一账单、回退路由与延迟优化
- 适用于需要跨供应商可靠性的智能体应用
- 免费 API Key 注册,提供充足测试额度
示例集成可使用官方 SDK 或 CometAPI 的统一端点——非常适合规模化编码
使用场景与最佳实践
- 智能体自动化:构建用于研究、数据分析或客服支持的稳健多智能体系统
- 编码与开发:迭代原型、调试与完整流水线生成(在 Antigravity 或 IDE 中)
- 多模态应用:图像/视频分析、图表理解、内容生成
- 企业工作流:利用缓存与思考等级进行成本控制的长时程流程
建议:使用完整对话历史以实现思路保留;从 medium 思考开始;优化提示以减少工具调用;监控 token 用量以提升成本效率。
限制与注意事项
- 价格上涨要求对高吞吐应用进行更精细优化
- 暂无 computer use(关注后续更新)
- 安全评估表现稳健且语气有所改善,但自动化指标存在波动
- 幻觉降低明显,但关键输出仍需验证
- 价格上涨:高于此前 Flash;可通过思考等级与缓存优化
- 知识截止:2025 年 1 月——涉及时事请使用 grounding/Search 工具
结论:Gemini 3.5 Flash 值得用吗?
值得——尤其适合优先追求速度、智能体可靠性、多模态能力与可规模化性能的开发者与企业。它推动了帕累托前沿,使前沿 AI 更适合生产工作负载。
准备开始构建? 立即访问 CometAPI,在同一仪表盘中将 Gemini 3.5 Flash 与其他顶级模型一起测试。优化你的 AI 技术栈、降低成本、更快交付。