

Alibaba 的 Wan2.7-Image 於 2026 年 4 月 1 日發佈,標誌著 AI 視覺生成的一大飛躍。這款統一模型將文字轉圖、互動式編輯、多圖合成與語義理解整合於單一架構中。不同於傳統將生成與編輯分離的流程,它消除了「標準化的 AI 臉」、文字亂碼與顏色不可預期等不一致問題。
創作者、設計師、行銷人員與企業如今能以更少迭代實現照片級真實、指令完全貼合的成果。該模型支援最多 12 張連續圖、9 張參考融合、12 種語言的文字渲染(最多 3,000 tokens),並提供像素級控制。
什麼是 Wan2.7-Image?
Wan2.7-Image 是 Alibaba 的 Tongyi Lab 在 Wan(Tongyi Wanxiang)系列中的旗艦統一圖像模型。它處理端到端的視覺工作流程:文字轉圖像、以圖生圖、基於指令的編輯,以及互動式像素級微調——全都在同一共享潛在空間中完成。
於 2026 年 4 月 1 日發佈,基於先前在 VBench 基準上名列前茅的 Wan 2.x 影片模型,將重心轉向圖像精度。它直接針對以往 AI 工具中常見的「審美疲勞」——臉孔重複、顏色不穩、提示對齊差等問題。該模型家族包含兩個對使用者最重要的名稱:wan2.7-image 與 wan2.7-image-pro。標準版針對「更快的生成速度」調校,Pro 版則面向「專業輸出」,並支援「4K 高清」。
關鍵差異化:統一架構。傳統模型採用不相連的階段(encoder → diffusion → decoder),編輯需另行修補。Wan2.7-Image 直接在共享空間中映射語義,實現真正理解,而非僅是像素圖樣匹配。
為何 Wan2.7-Image 重要(產業脈絡)
傳統 AI 圖像工具的痛點包括:
| 問題 | 說明 |
|---|---|
| 工作流分散 | 生成、編輯、修補相互分離 |
| 「AI 臉綜合症」 | 臉孔重複、缺乏真實感 |
| 指令對齊弱 | 無法準確遵循提示 |
| 文字渲染差 | 文字扭曲或難以辨讀 |
| 多圖輸出不一致 | 角色在多張圖像中容易變化 |
Wan2.7-Image 以「統一架構 + 語義理解層」直接解決上述限制。
Wan2.7-Image 的 5 大核心特性
1. 骨骼級虛擬形象自訂,打造真正獨一無二的臉孔
Wan2.7-Image 擅長「為每個人生成獨一無二的臉孔」。它支援對骨骼結構、眼型(杏眼、鳳眼、深邃眼、泡泡眼、笑眼)、臉部輪廓與細微特徵的精細控制。這消除了過往模型中普遍的「標準化的 AI 臉」問題。

示例提示語:「照片級寫實的 28 歲東亞女性肖像,橢圓臉,杏仁眼,淺淺微笑,皮膚質感細節,自然光。」結果呈現逼真多樣性,適合虛擬網紅、遊戲 NPC 或個人化品牌。
2. 精準色盤控制
其中一項最實用的新特性是全新的「色盤」控制。Alibaba 表示使用者可輸入特定色彩代碼與比例,以復刻藝術風格或鎖定品牌色。API 文件以 color_palette 參數正式定義此能力,接受「3 到 10 種顏色」,建議「8 種」。對品牌團隊而言,這是此次發佈中最明確的企業級功能之一。不再隨機換色——在整個行銷活動中保持完美一致。
官方引述:「向隨機顏色生成說再見。精準實現色彩比例,將你的創意願景具象化。」— Tongyi Wanxiang。
3. 進階多語文字渲染(12 種語言,3,000 tokens)
以印刷等級清晰度(相當於 A4)渲染超長文本、表格、公式、圖表與資訊圖。支援中文、英文、日文、韓文及另外 8 種語言。學術論文、海報、產品標籤與多語橫幅可達近乎完美的可讀性——解決 AI 歷史弱項。
4. 以選框工具進行像素級互動式編輯
使用邊界框(editRegions)或選框工具進行局部變更。可上傳最多 9 張參考圖,並下達如「更換背景為海灘夕陽,同時保留臉部、姿勢與服裝」等指令。像素級精度確保身份一致性。
5. 多圖合成生成(最多 12 幅連續圖像)
該模型不僅面向單次提示生成。Alibaba 表示,使用者可使用「最多九張參考圖」,並「一次生成最多 12 張圖像」,非常適合一致性的分鏡、建築與電商系列。「點擊編輯」流程可選擇特定區域並以「像素級精度」進行修改,API 文件亦新增透過邊界框參數進行「互動式精準編輯」以實現局部編修。
Wan2.7-Image 如何運作?(技術深潛)
Alibaba 將 Wan2.7-Image 描述為一個橋接語言與視覺的框架,透過在大規模、多樣化資料集上的訓練而成。簡言之,模型不僅學習如何繪製圖像,也學習提示如何映射到視覺結構、構圖、光線與文字配置。這讓模型比基本的文字轉圖系統更能準確解讀使用者意圖。
API 也顯示該模型為多模態輸入而設計。實務上,請求透過單輪訊息結構送出,內容可同時包含文字與圖像項目。對於編輯,使用者可提供多張圖像與如「move」、「replace」或「blend」等指令來引導結果。這清楚顯示 Wan2.7 被設計為「提示 + 參考」系統,而非單步生成器。
文件同時揭示了思考模式設定。該模式預設啟用,可提升輸出品質,但 Alibaba 指出會增加生成時間。這有助於理解模型工作流程:當請求包含大量文本或視覺複雜度較高時,較高品質的輸出可能需要更長的內部推進時間。
Wan2.7-Image 採用共享潛在空間中的「統一生成-編輯框架」:
- 輸入階段:文字提示(最多 3,000 tokens)+ 可選參考圖像(最多 9 張)。
- 語義解析與思考模式(Pro 增強):在像素生成之前,以鏈式思考分析構圖、空間關係、光線與邏輯。
- 共享潛在空間映射:語義直接映射到視覺特徵——不存在編碼器/解碼器的斷層。
- 統一推理:生成或編輯於同一優化流程中完成。編輯區域使用邊界框;色盤強制比例。
- 輸出:高保真圖像(標準 768–2048×2048;Pro 為 4K),可選 JPG/PNG/WEBP,提供可重現的種子與安全檢查。
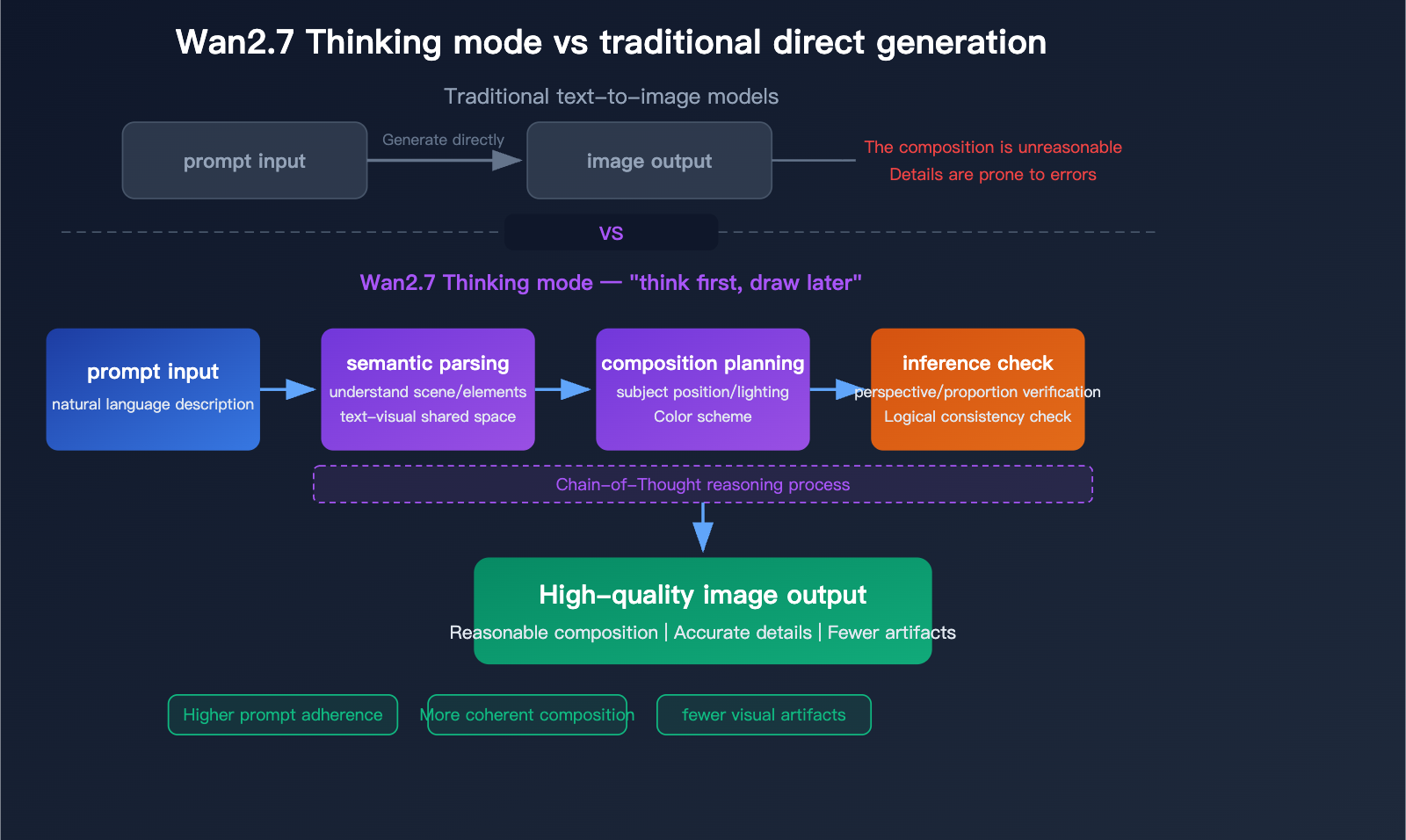
Wan2.7-Image-Pro 的思考模式流程圖顯示語義解析 → 構圖規劃 → 推理檢查,相較直接生成可減少雜訊與瑕疵,並更貼合提示。
在多樣化資料集上的訓練,讓模型能深度理解意圖、光線與版面配置。長上下文學習(arXiv 研究所述)則支援長文本處理能力。
Wan2.7-Image 與 Wan2.7-Image-Pro:關鍵差異
兩個版本同時推出,但 Pro 更聚焦專業需求。
| 特性 | Wan2.7-Image(標準版) | Wan2.7-Image-Pro | 最佳適用 |
|---|---|---|---|
| 最大解析度 | 2048×2048 | 4096×4096(4K) | 印刷/生產(Pro) |
| 思考模式 | 可用(預設更快) | 增強/預設,具更深層思考 | 商業專案(Pro) |
| 構圖穩定性 | 強 | 更佳語義理解 | |
| 速度 vs 品質 | 迭代更快 | 更高保真,時間略長 | 原型製作(標準版) |
| 使用情境 | 一般創作者、社群內容 | 企業設計、學術/印刷 | 可擴展 vs 精準 |
標準版適合快速原型;Pro 版提供可直接印製的 4K,且一致性更佳。
如何使用 Wan2.7-Image(逐步指南)
1. 存取平台
可透過:
- Alibaba Cloud(BaiLian 平台)
- Wanxiang 官方工具
- CometAPI
2. 選擇工作流程模式
模式 A:文字轉圖像
Prompt example:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
模式 B:圖像編輯
- 上傳圖像
- 選取區域
- 輸入指令
Example:
Replace background with a futuristic city
模式 C:多圖合成
- 上傳多張參考
- 定義合成規則
3. 微調參數
- 色盤
- 風格一致性
- 文字渲染
4. 匯出輸出
- 高解析度圖像
- 可用於商業的素材
基準測試表現與競品比較
在盲測的人類偏好測試中,Wan2.7-Image 在文字轉圖品質上超越 GPT-Image-1.5,並在文字渲染、寫實度與世界知識方面持平或優於 Nano Banana Pro。
比較表:
| 模型 | 文字渲染 | 指令遵循 | 頭像自訂 | 多圖參考 | 生成/編輯統一 | 解析度 | 開源/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | 優秀(12 語) | 卓越(思考模式) | 骨骼級 | 9 | 是 | 2K–4K | 是/API |
| Midjourney V8 | 良好 | 中等 | 藝術性強 | 受限 | 否 | 高 | 僅限 Discord |
| FLUX | 良好 | 強(簡單) | 良好 | 受限 | 否 | 高 | 是 |
| DALL-E 3 | 中等 | 良好 | 中等 | 無 | 否 | 2K | API |
| Nano Banana Pro | 強 | 強編輯能力 | 良好 | 強 | 部分 | 高 | 封閉 |
Wan2.7-Image 在統一工作流、多語文字與精準控制方面領先——對非英語市場與專業管線尤其有價值。
CometAPI 是一站式的大模型 API 聚合平台,提供無縫整合與管理 API 服務,支援多種圖像生成 API,如 GPT-image-1.5、Nano Banana series、Midjourney,以及 Qwen Image Series 等,價格低於官方。
誰該使用 Wan2.7-Image
Wan2.7-Image 尤其適合需要速度與靈活性、而非僅一次性藝術創作的團隊。包括成效型行銷、產品設計、電商攝影棚、社群內容團隊,以及需從同一簡報產出大量變體的代理商。其支援多圖輸入、多輸出生成與基於指令的編輯,對於重視一致性、速度與提示控制的工作流程極具吸引力。
真實應用場景
- 遊戲/娛樂:數分鐘內生成 100 位獨特 NPC。
- 行銷/電商:使用精準色盤的品牌一致輪播圖。
- 教育/學術:可印製的含公式與表格之海報。
- 設計代理:以互動編輯進行分鏡與客戶修訂。
生產力提升來自更少迭代與無縫參考整合。
結論:
Alibaba Wan2.7-Image 以統一生成、編輯與理解重塑 AI 創意疆界。其 5 大核心功能、共享潛在空間與 Pro 增強,帶來競品仍難以匹敵的專業級成果。無論是為社群內容做原型,還是製作可印製的學術視覺,它都提供無與倫比的精準與效率。
立即於 wan.video 開始使用,或透過 CometAPI 的 API 接入。對開發者與企業而言,憑藉強大能力、易用性與數據支撐的優勢,Wan2.7-Image 成為 2026 年及未來統一式 AI 圖像模型的明顯領導者。