

Luma AI 的 Uni-1 不只是一個新的文生圖模型。按照 Luma 自己的定義,它是一個「能生成像素的多模態推理模型」,建立在「Unified Intelligence」之上,因此它能理解意圖、回應指令,並且「與你一起思考」。該公司的技術報告指出,這個模型採用僅解碼器(decoder-only)的自回歸 Transformer,其中文字與影像以單一交錯序列表示,而 Uni-1 能在影像合成之前與過程中執行結構化的內部推理。這種組合,正是 Uni-1 成為 2026 年最有意思的影像模型發布之一的原因。
什麼是 UNI-1 影像模型?
Uni-1 是 Luma AI 推出的新影像模型,適用於需要在同一系統中同時完成理解與生成的任務。Luma 將它定位為多模態推理模型,而不是傳統僅靠擴散的影像引擎;這一點很重要,因為這代表模型的目標不只是產生視覺上討喜的輸出:它被設計用來解讀指令、保留參考約束,並在生成過程中推理場景邏輯。該公司的技術報告將 Uni-1 描述為其邁向多模態通用智慧路徑上的首個統一理解與生成模型。
為什麼 Uni-1 與眾不同
舊有流程有其上限:缺乏理解能力的影像生成只能走到某個程度。Uni-1 被視為朝向「統一智慧」邁進的一步,在這種架構中,語言、感知、想像、規劃與執行都由同一套架構處理。這不只是品牌包裝。Uni-1 能從單純追求視覺相似,進一步走向有意圖的構圖、合理性與場景邏輯。
更大的趨勢是,影像模型正變得更具代理性。Google 最新的影像堆疊現在強調對話式編輯、搜尋錨定、多圖融合與角色一致性;OpenAI 的 GPT Image 系列則強調原生多模態與指令遵循。Uni-1 也加入了這股轉變,但它更進一步強調模型應在下筆繪製之前先對影像進行「思考」。這讓 Uni-1 對於那些精準度與可重複性和視覺表現同樣重要的工作流程特別有吸引力。
Uni-1 實際上是如何運作的?
🔬 Tokenization Process
- Text → token sequence
- Image → tokenized patches
- Combined into single interleaved sequence
🔁 Generation Process
- Input prompt + references
- Model performs internal reasoning
- Plans composition
- Generates tokens sequentially
Mathematically: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
🧠 Internal Reasoning Layer
Uni-1:
- Decomposes instructions
- Resolves constraints
- Plans layout before rendering
👉 與擴散模型相比,這是一次重大躍進。
僅解碼器自回歸生成
最重要的技術細節是,Uni-1 採用自回歸,而非擴散式架構。Luma 的技術報告指出,它是一個僅解碼器的自回歸 Transformer,且文字與影像被編碼為單一交錯序列。用白話來說,模型不是單純從噪聲開始,再逐步「去噪」得到影像。相反地,它是逐步生成 token,讓模型能在渲染前與渲染過程中對提示詞進行推理、解決約束,並規劃構圖。
🔬 Tokenization Process
- Text → token sequence
- Image → tokenized patches
- Combined into single interleaved sequence
Diffusion vs Autoregressive
| Feature | Diffusion Models | Uni-1 (Autoregressive) |
|---|---|---|
| Generation | Noise → Image | Token-by-token |
| Reasoning | Limited | Strong |
| Editing | Weak | Multi-turn |
| Text rendering | Poor | Strong |
| Control | Low | High |
核心架構
Uni-1 是:
- 僅解碼器自回歸 Transformer
- 文字 + 影像共用的 token 空間
這種架構之所以重要,是因為當提示詞很複雜時,它給了模型維持一致性的機會。Luma 表示,Uni-1 能分解指令、解決互相衝突的約束,並在渲染開始前規劃影像。這對於結構化場景補全、多主體擺位、多輪精修,以及那些要求輸出既忠於參考圖又要遵循新指令的編輯任務特別有幫助。
這個模型似乎特別擅長什麼
學會生成影像,也會提升理解能力。Luma 表示,模型的影像生成訓練能實質提升細粒度視覺理解,尤其是在區域、物件與版面配置方面。這就是為什麼 Uni-1 不被視為單向生成器,而是生成與理解彼此增強的統一系統。從推論角度來看,這代表 Uni-1 正試圖縮小「看見」與「製作」之間的差距。與擴散模型相比,這是一次重大躍進。
Generation Process:
- Input prompt + references
- Model performs internal reasoning
- Plans composition
- Generates tokens sequentially
Mathematically: P(x1,...,xn)=∏P(xi∣x1,...,xi−1)P(x_1,...,x_n) = \prod P(x_i | x_1,...,x_{i-1})P(x1,...,xn)=∏P(xi∣x1,...,xi−1)
Uni-1 提供了哪些功能與核心優勢?
強大的指令遵循能力與可控性
Uni-1 最強的賣點是控制力。這個模型是為精準編輯、結構化參考使用,以及可重複工作流程而打造。對創作者來說,這意味著更少的提示詞賭運氣,以及更多可重複的輸出。
Uni-1 的一個實用優勢是,它為可控迭代而設計。Seed 讓使用者可以重現結果,而參考角色則幫助模型理解某張影像應該引導角色身分、氛圍、色盤還是構圖。這讓 Uni-1 比純提示詞驅動的模型更容易導向,尤其適合製作廣告、分鏡、產品 mockup 或品牌素材的團隊,因為這些場景特別重視一致性。
能保留身分的一致參考生成
一個主要優勢是參考處理。Luma 明確表示,Uni-1 使用以來源為依據的控制方式,並且能保留一個或多個參考中的身分、構圖與關鍵視覺約束。這讓它對商業工作流程很有吸引力,例如品牌角色、產品 mockup、行銷活動素材,以及任何需要主體在不同變體中仍可辨識的專案。這也是 Uni-1 與更偏重美學的影像系統最明顯的差異之一。
文化流暢度與風格廣度
Luma 也強調其具備文化感知生成能力。它的「Cultured」部分提到迷因、漫畫、電影感風格、日常照片、運動與動物影像,顯示這個模型的目標是能跨越多種視覺語言運作,而不是只停留在單一通用風格。這很重要,因為一個優秀的現代影像模型不只需要渲染出寫實場景;它還需要理解網路文化、編輯設計、風格化插畫與社群內容的視覺慣例。
將多模態思考作為設計選擇
真正的差異化不只是 Uni-1 會生成影像,而是 Luma 將影像生成定義為一項推理任務。Uni-1 能執行結構化內部推理,而且學習生成影像會提升對區域、物件與版面配置的細粒度視覺理解。這暗示它是一個在渲染前先理解場景的模型,而不只是以統計方式去近似提示詞。
效能基準
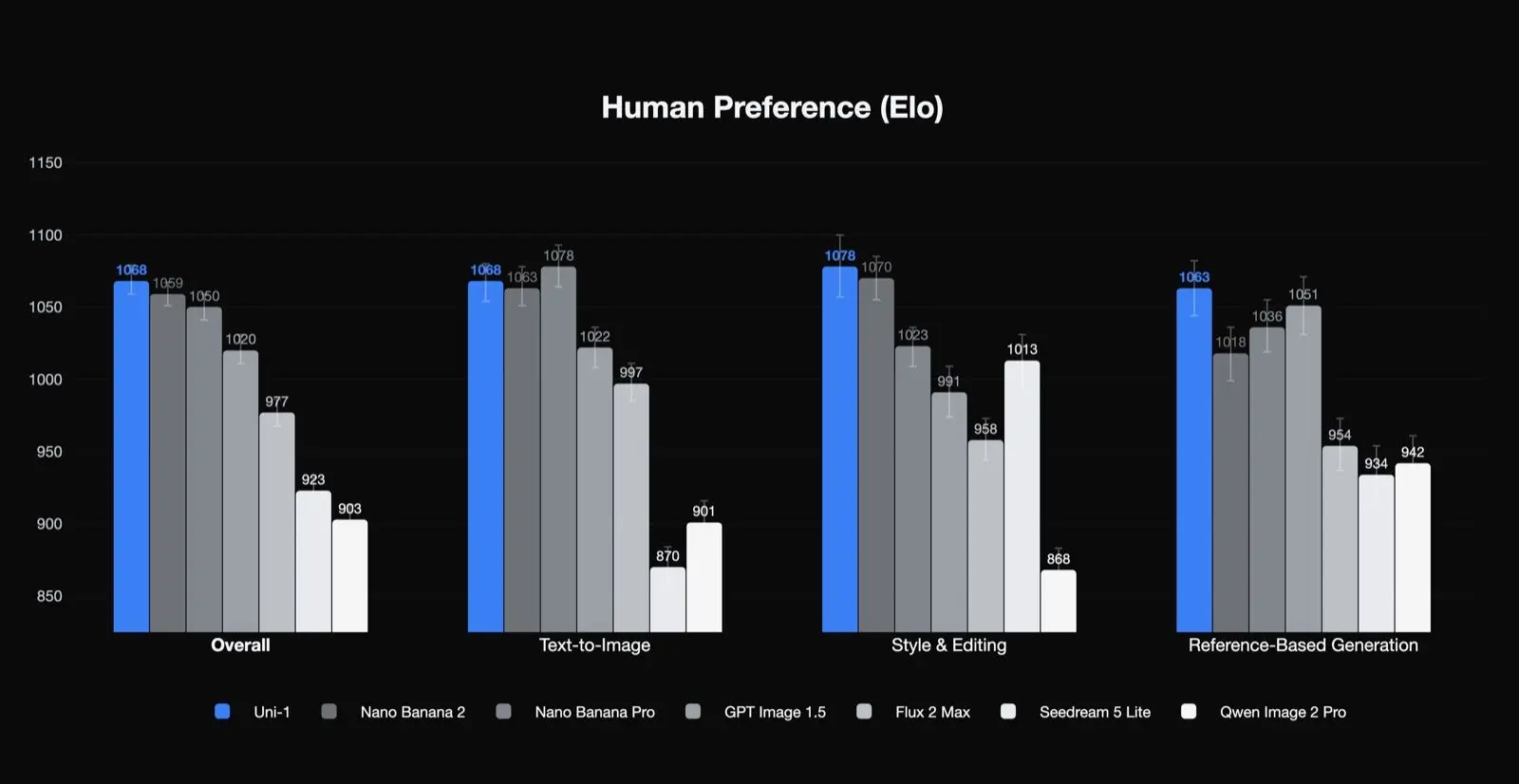
Luma 自家的人類偏好結果
Uni-1 在整體品質、風格與編輯、以及基於參考的生成等項目的人類偏好 Elo 排名第一,在文生圖項目排名第二。這是一個有意義的結果,因為它顯示這個模型特別擅長生產團隊最在意的任務類型:編輯、一致性與引導式轉換。這也表示,它最適合的使用情境可能不只是單次的一鍵文生圖。
RISEBench:融入推理的視覺編輯
最吸引注意的基準測試是 RISEBench,它評估融入推理的視覺編輯能力,涵蓋時間、因果、空間與邏輯推理。根據第三方對 Luma 發布的報導,Uni-1 在 RISEBench 的總分為 0.51,領先 Google 的 Nano Banana 2(0.50)、Nano Banana Pro(0.49)以及 OpenAI 的 GPT Image 1.5(0.46)。在空間推理上,Uni-1 的成績據稱為 0.58,而 Nano Banana 2 為 0.47。在邏輯推理上,Uni-1 的成績據稱為 0.32,是 GPT Image 1.5 的 0.15 的兩倍以上。整體差距不算非常大,但在最困難的推理類別中,差距相當明顯。

ODinW-13 與「生成提升理解」這一主張
Uni-1 在 ODinW-13 上也表現強勁,這是一個開放詞彙的密集偵測基準。根據對 Luma 技術資料的報導,完整模型獲得 46.2 mAP,幾乎追平 Google 的 Gemini 3 Pro 的 46.3。同一報導指出,僅理解版本獲得 43.9 mAP,這意味著生成訓練讓理解能力提升了 2.3 分。這是一項值得注意的發現,因為它支持了 Luma 的核心論點:影像生成與影像理解可能不是互相競爭的目標,而是彼此增強。
Uni-1 API 的價格
| Input price (text) | $0.50 |
|---|---|
| Input price (images) | $1.20 |
| Output price (text and thinking) | $3.00 |
| Output price (images) | $45.45 |
在消費者端,Luma 的定價頁面列出 Plus 為 $30/月、Pro 為 $90/月、Ultra 為 $300/月,且各方案都包含免費試用點數。這表示實際上有兩層價格需要考慮:平台的消費者會員方案,以及用於正式生產的模型級 API 定價。
目前,CometAPI 的 Uni-1 API 顯示為 Available Soon,並承諾在正式推出時提供折扣。當前,CometAPI 也提供出色的 raw image 模型,例如 Midjourney 與 Nano Banana 2。
Uni-1 vs GPT Image 1.5 vs Nano Banana 2
Uni-1 與 Google 的 Nano Banana 2 對比
Nano Banana 2 在參考處理的廣度與生態整合方面看起來更強。Google 強調影像搜尋錨定、對話式迭代,以及最多可使用 14 張參考圖的重參考工作流程。相比之下,Uni-1 更明確地圍繞推理、場景合理性,以及統一模型架構中的精準編輯來定位。實際上,Google 看起來更偏向速度、主流生產規模與原生 Google 錨定;而 Luma 看起來則更偏向結構化視覺推理與可控的影像編輯。
在圍繞 Uni-1 的公開比較中,這種取捨相當清楚:Nano Banana 2 在純文生圖品質與速度上似乎仍然非常強,而 Uni-1 則更著重於高推理需求的編輯、參考控制與指令忠實度。
Uni-1 與 OpenAI 的 GPT Image 對比
在基準測試報導中,Uni-1 在 RISEBench 總體上略勝 GPT Image 1.5,在邏輯推理上則更明顯領先。與 OpenAI 的 GPT Image 系列相比,Uni-1 的定位更聚焦且更積極地圍繞視覺推理與可控編輯。OpenAI 的文件強調世界知識、多模態理解與上下文感知;Luma 的文件則強調結構化內部推理、以參考為基礎的控制,以及經基準驗證的視覺編輯能力。因此,雖然兩者都是多模態模型,Uni-1 更明顯是一個「影像專精型推理模型」,而 GPT Image 則更像是一個剛好也非常擅長生成影像的通用多模態系統。
三者之間的價格比較
在定價方面,比較取決於輸出尺寸與產品層級,因此並不是完全同類型的直接對比。Uni-1 公布的 2048px 等效價格約為每張影像 $0.0909。Google 最新的影像模型定價頁面列出,其最新 Gemini 影像預覽為每張 1K/2K 影像 $0.134、每張 4K 影像 $0.24;而 OpenAI 的 GPT Image 定價頁面則列出每張輸出的價格為:1024x1024 低品質 $0.011、中品質 $0.042、高品質 $0.167,而更大的高品質輸出為 $0.25。換句話說,OpenAI 在低端價位可能便宜得多,Google 在速度與規模端競爭力強,而 Uni-1 則落在中間,擁有強勁的 2K 導向價格效能比。
哲學差異
| Model | Approach |
|---|---|
| Uni-1 | Unified multimodal intelligence |
| GPT Image | LLM + image generation |
| Nano Banana 2 | Optimized production diffusion |
詳細比較表
| Feature | Uni-1 | GPT Image 1.5 | Nano Banana 2 |
|---|---|---|---|
| Architecture | Autoregressive | Hybrid | Diffusion |
| Multimodal unification | ✅ Native | Partial | ❌ |
| Reasoning ability | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| Image quality | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Text rendering | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ |
| Editing workflows | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| Speed | Medium | Fast | Fast |
| Control | High | Medium | Medium |
CometAPI 提供 GPT Image 1.5、Nano Banana 2 與即將推出的 Uni-1 的互動式 raw image,以及 API 程式設計支援。折扣價格與隨用隨付選項,使其成為開發者偏好的選擇。
Uni-1 最適合什麼
Uni-1 看起來特別適合那些需要可重複性、角色一致性或多參考控制的情境。這包括品牌活動、產品 mockup、編輯概念、分鏡、本地化變體,以及那些必須維持構圖不變、但需要改變風格或環境的影像編輯。Luma 自家的範例也大多圍繞這些使用情境,而模型中的「Create vs Modify」區分,基本上就是直接回應常見的生產痛點。
如果你的工作大多只是「用一個提示詞做出漂亮圖片」,那麼這種差異化可能不會顯得那麼明顯。但如果你的工作流程是「做出五個相關版本、保持同一角色、保留取景、改變光線,並且下週還能重現」,那麼 Uni-1 的設計就會開始變得很有意義。這是一種推論,但它與 Luma 所強調的控制功能自然吻合。
使用 Uni-1 取得更好結果的最佳實踐
先從使用正確模式開始。Luma 的指引很簡單:當你想建立新場景時用 Create,當你想保留既有場景時用 Modify。把這兩種意圖混在一起,輸出就會更不穩定。
像專業人士一樣使用參考標籤。Luma 建議使用像是「Use IMAGE1 as a STYLE reference」或「Use IMAGE2 as LIGHTING」這樣的語句。當每張參考圖都有明確職責,而不是模糊的「靈感來源」時,模型表現會更好。
當你找到好的結果後,就鎖定 seed。Luma 明確建議,先在不設定 seed 的情況下探索,等得到夠強的結果後再保存 seed。之後,每次只改動一個變數。這是把生成流程轉變為可控生產系統最簡單的方法。
具體一點,也務實一點。Luma 警告不要使用像「beautiful」或「amazing」這種模糊詞,而是鼓勵使用具名美學,例如「1970s Italian giallo film poster」,或精確的相機風格提示。實務上,具體提示詞通常比詩意提示詞更有效,因為模型可以錨定在真實的結構上。
使用 Create → Modify 鏈。Luma 明確表示,這是它最強大的工作流程之一:先在 Create 中探索,再在 Modify 中精修。這正是嚴肅生產工作的甜蜜點,因為它能減少回頭重來,並在收緊細節的同時保留構圖中的優點。
最終結論
Uni-1 是 Luma 迄今最明確的一次表態:影像生成正從「輸入提示詞,輸出圖片」走向由推理引導的視覺創作。它公開展現出的優勢是控制力、參考處理、可重現性,以及讓語言與像素存在於同一系統中的模型架構。
對於重視高點擊率視覺輸出、一致角色、精準編輯,以及高解析度價格透明度的創作者與團隊而言,Uni-1 絕對是一個值得關注的模型。如果 API 的推出過程順利,它很可能成為 2026 年 Google 的 Nano Banana 2 與 OpenAI 的 GPT Image 1.5 之外,最有意思的替代選擇之一。
打算開始創作 raw image 嗎?CometAPI 作為多模態模型 API 的一站式聚合平台,歡迎你的加入!