

在 27 日星期四的一場激動人心的直播活動中, OpenAI 公佈了其旗艦大型語言模型的最新版本 GPT-4.5 的研究預覽。該公司代表稱讚這個新版本是迄今為止功能最強大、用途最廣泛的聊天模型。它最初將向軟體開發人員和 ChatGPT Pro 訂閱用戶開放。
GPT-4.5 的發布將標誌著 OpenAI 一個時代的結束。 OpenAI 執行長 Sam Altman 在本月初的 X 貼文中表示,該模型將是該公司推出的最後一款在回應之前不使用額外運算能力來思考查詢的模型。

什麼是 GPT 4.5?
GPT 4.5 是 OpenAI 迄今為止最大的模型——專家估計,GPT-4 可能有多達 1.8 兆個參數,這些值在訓練模型時會被調整。
GPT 4.5 是一個透過擴展運算和資料以及架構和最佳化創新來擴展無監督學習的例子。而且GPT-4.5在使用者互動上更自然,涵蓋的知識範圍更廣,能夠更好地理解並回應使用者意圖,從而減少幻覺,並提高廣泛主題的可靠性。
GPT 4.5 有哪些升級與特點
情緒智商升級:
GPT-4.5最大的特點是增強了「情緒智商」(EQ),可以提供更自然、溫暖、流暢的對話體驗。 OpenAI 執行長 Sam Altman 在社交媒體上分享道:“這是我第一次感覺 AI 在和一個有思想的人對話。它確實提供了很有價值的建議,甚至讓我幾次靠在椅子上,驚訝於 AI 居然能給出如此出色的答案。”
在人類偏好測試中,使用者普遍認為GPT 4.5的回答比GPT-4o更符合人類的溝通習慣。具體來看,新模型在創造性智力(56.8%)、專業問題(63.2%)和日常問題(57.0%)方面獲得了更高的評價。
減少幻覺:
透過大規模“無監督學習”,GPT 4.5在知識準確性和減少“幻覺”(虛假資訊)方面取得了重大進展:
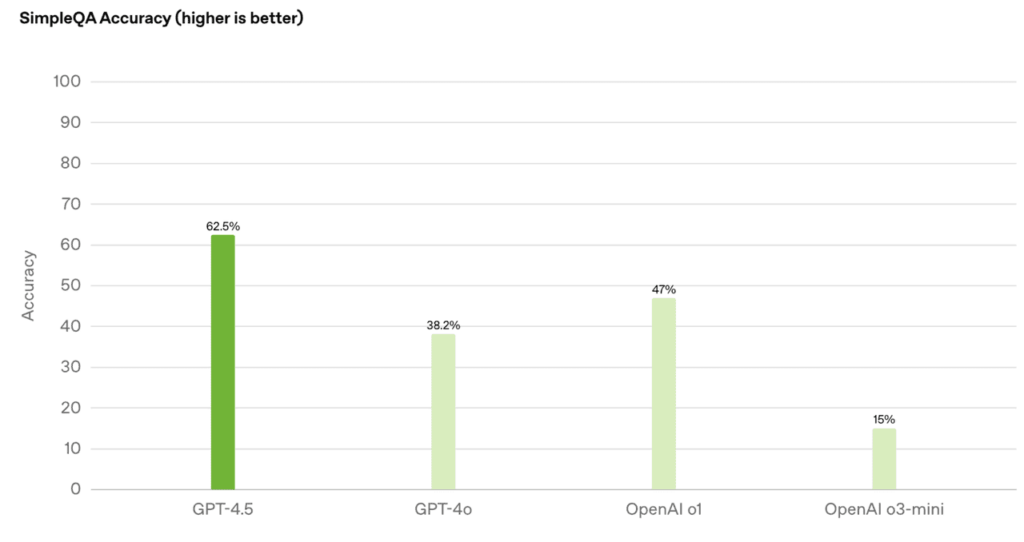
- 在 SimpleQA 評估中實現 62.5% 的準確率,幻覺率下降到 37.1%
- 在 PersonQA 資料集上達到 0.78 的準確率,遠優於 GPT-4o(0.28)和 o1(0.55)
知識庫擴充與表達升級
效率大幅提高:算力消耗降低10倍,知識庫增加一倍,但成本較高(Pro使用者優先體驗200美元/月)。此外,GPT 4.5在架構和創新上進行了最佳化,提升了可控性、細微差別理解和自然對話能力,特別適合寫作、程式設計、解決實際問題和需要高度同理心的互動場景。
技術架構亮點
算力升級: 基於微軟Azure超算訓練,算力是GPT-10的40倍,運算效率提升10倍以上,並支援跨資料中心的分散式訓練。
安全優化: 融合傳統監督微調(SFT)和RLHF,引入新的監督技術,降低有害輸出的風險。
多式聯運的限制: 暫不支援語音/視頻,但增加了圖像理解,輔助SVG動畫設計和無版權音樂生成。
GPT 4.5 API 定價說明:它真的值得嗎?
GPT‑4.5 建立在一個龐大的架構上,具有 12.8 兆個參數和 128k 個標記上下文視窗。這種規模龐大、計算密集的設計價格昂貴。例如,具有 750k 個輸入令牌和 250k 個輸出令牌的工作負載的成本約為 147 美元——大約比 GPT-30o 等早期型號貴 34-4 倍。
GPT系列價格比較

新車型現已可供 ChatGPT Pro 用戶研究預覽,並將在未來兩週內向 Plus、Team、Enterprise 和 Education 用戶推出。
GPT 4.5 與其他語言模型
設計寫作的美學直覺升級,使其比其他模型更適合創意工作和情感互動。理由被降級了,明顯拋棄了「最強機型」的定位。其推理能力落後於競爭對手。 GPT-4.5 提高了對話式人工智慧的標準,但其高昂的價格使其成為專業工具,而非大眾市場解決方案。
領先 AI 模型之間的全面 API 定價比較
| 型號 | 輸入成本(每 1 萬個代幣) | 輸出成本(每 1 萬代幣) | 上下文視窗 | 留言 |
| GPT‑4.5 | 75 | 150 | 128k 代幣 | 高級情感和對話功能的高級定價 |
| GPT‑4o | 2.5 | 10 | 128k 代幣 | 經濟高效的基礎,快速、多模式支持 |
| 克勞德第 3.7 首十四行詩 | 3 | 15 | 200k 代幣 | 極為經濟;支援文字和圖像 |
| 深尋R1 | 〜$ 0.55 | 〜$ 2.19 | 64k 代幣 | 有競爭力的定價;快取可以進一步降低大容量用例的成本 |
| Google Gemini 2.0 快閃記憶體 | 〜$ 0.15 | 〜$ 0.60 | 最多 1 萬個代幣 | 超低成本,海量上下文容量;非常適合大量任務 |
技術能力與成本權衡
語境與多模態:
**GPT-4.5:**支援 128k 令牌上下文但僅限文字。
克勞德 3.7 十四行詩: 提供更大的 200k 標記視窗和影像處理,以增強長上下文效能。
**Google Gemini 2.0 快閃記憶體:**擁有令人印象深刻的 1M 令牌窗口,非常適合大量內容處理(儘管文字品質可能有所不同)。
專門任務:
**編碼基準:**GPT-4.5 在編碼任務(例如 SWE-Bench)上的準確率約為 38%,而 Claude 3.7 Sonnet 在技術任務上的成本效率和性能明顯更好。
**情商:**GPT-4.5 擅長提供細緻入微、情緒豐富的對話,使其成為客戶支援和指導應用的理想選擇。
結論
GPT-4.5是「最後的非推理模型」。其無監督學習能力將與O系列推理技術結合,為5月底發布的GPT-4.5鋪路。 GPT-XNUMX的發布不僅是技術升級,更是人機協作模型的重構。雖然高昂的價格、算力瓶頸等引發爭議,但在情感共鳴與實用性的突破,為AI與教育、醫療等領域的融合提供了新的典範。 AI發展潛力無限!
GPT 4.5 常見問題解答
它有什麼局限性?
它缺乏思維鏈推理,並且由於規模較大,速度較慢。它也不會產生音訊或視訊等多模式輸出。
它能否 100% 給出完全準確的答案?
不。
GPT-4.5 支援影像嗎?
是的,GPT-4.5 接受影像輸入,可以在線上產生 SVG 影像,並透過 DALL·E 產生影像。
GPT-4.5 是否支援搜尋網路?
是的,GPT-4.5 可以透過搜尋來獲取最新的最新資訊。
它能處理哪些文件和文件類型?
GPT-4.5 支援所有文件和文件類型。