

17年2025月1日,上海人工智慧領導者MiniMax(又稱兮語科技)正式發表MiniMax-M1(以下簡稱「M1」)-全球首個開源、大規模混合注意力推理模型。 M1融合了混合專家(MoE)架構和創新的閃電注意力機制,在生產力導向的任務中實現了業界領先的性能,媲美頂級閉源系統,同時保持著無與倫比的成本效益。在這篇深入的文章中,我們將探討MXNUMX的概念、工作原理、關鍵特性以及存取和使用模型的實用指南。
什麼是 MiniMax-M1?
MiniMax-M1 代表了 MiniMaxAI 在可擴展、高效注意力機制研究方面的巔峰。 M01 迭代在 MiniMax-Text-1 基礎上,將閃電注意力機制與 MoE 框架結合,在訓練和推理過程中實現了前所未有的效率。這種組合使模型即使在處理極長序列時也能保持高效能——這對於涉及海量程式碼庫、法律文件或科學文獻的任務來說至關重要。
核心架構和參數化
MiniMax-M1 的核心在於利用混合 MoE 系統,該系統透過專家子網路的子集動態路由令牌。雖然模型總共包含 456 億個參數,但每個代幣僅啟動 45.9 億個參數,從而優化了資源利用率。此設計借鑒了早期 MoE 實現,但改進了路由邏輯,以最大限度地降低分散式推理期間 GPU 之間的通訊開銷。
閃電關注和長上下文支持
MiniMax-M1 的一個顯著特徵是其閃電注意力機制,它大幅降低了長序列自註意力的計算負擔。透過結合局部和全域核函數來近似注意力矩陣,該模型在處理 75 萬個 token 序列時,與傳統 Transformer 相比,可將 FLOP 降低高達 100%。這種效率不僅加速了推理,還為處理高達一百萬個 token 的上下文視窗打開了大門,而無需過高的硬體要求。
MiniMax-M1 如何實現運算效率?
MiniMax-M1 的效率提升源自於兩項主要創新:其混合專家架構和訓練過程中使用的全新 CISPO 強化學習演算法。這些元素共同縮短了訓練時間和推理成本,從而實現了快速實驗和部署。
混合專家路由
MoE 元件採用 32 個專家子網絡,每個子網絡專注於推理的不同面向或特定領域任務。在推理過程中,一種學習門控機制會動態地為每個 token 選擇最相關的專家,僅啟動處理輸入所需的子網路。這種選擇性激活機制減少了冗餘計算並降低了記憶體頻寬需求,使 MiniMax-M1 在成本效率方面顯著優於單片 Transformer 模型。
CISPO:一種新穎的強化學習演算法
為了進一步提升訓練效率,MiniMaxAI 開發了 CISPO(帶有部分覆蓋的裁剪重要性採樣),這是一種強化學習 (RL) 演算法,以基於重要性採樣的裁剪取代了標記級權重更新。 CISPO 緩解了大規模強化學習 (RL) 設定中常見的權重爆炸問題,加速了收斂,並確保在不同基準測試中策略的穩定改進。因此,MiniMax-M1 在 512 塊 H800 GPU 上的完整強化學習 (RL) 訓練僅需三週即可完成,成本約為 534,700 美元——僅為同類 GPT-4 訓練運行成本的一小部分。
MiniMax-M1 的效能基準為何?
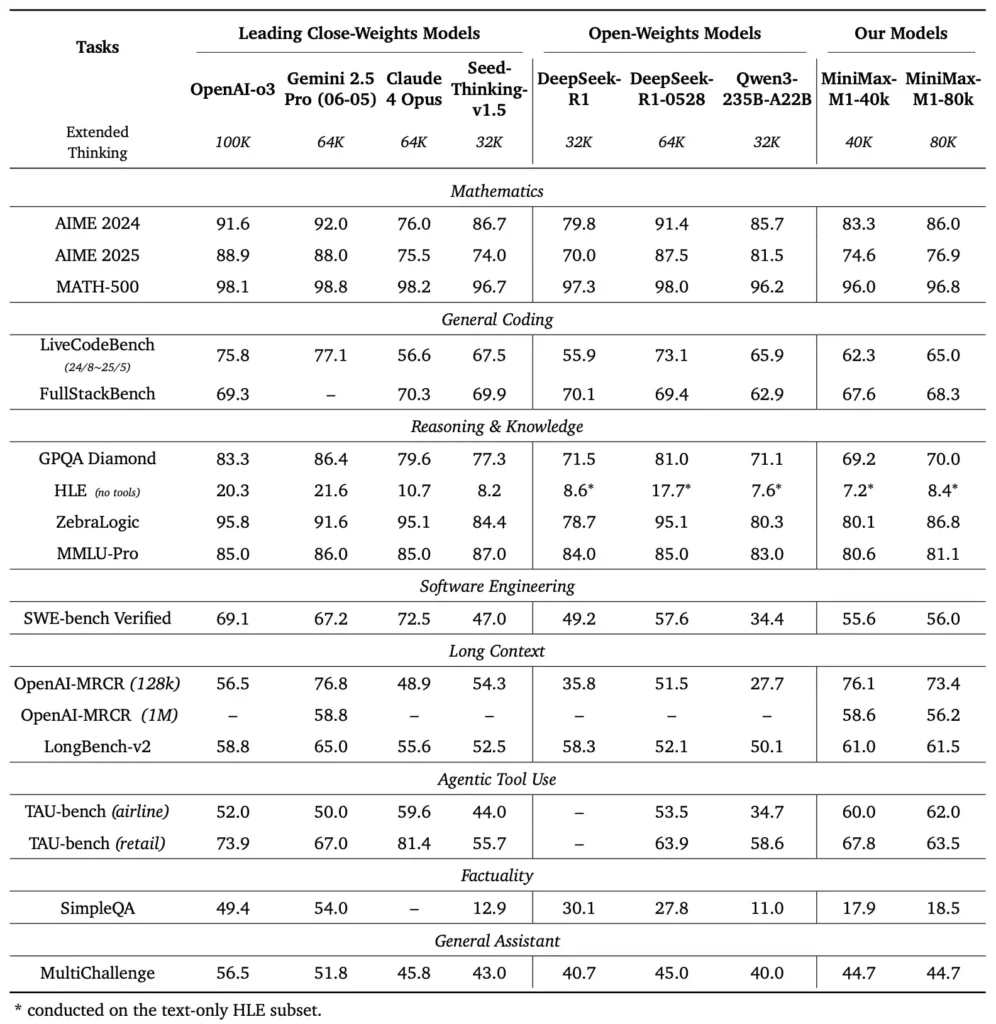
MiniMax-M1 在各種標準和特定領域的基準測試中表現出色,展現了其在處理長上下文推理、數學問題解決和程式碼生成方面的強大能力。
長上下文推理任務
在廣泛的文檔理解測試中,MiniMax-M1 可處理多達 1,000,000 個 token 的上下文窗口,其最大上下文長度比 DeepSeek-R1 高出八倍,且 100 個 token 序列的計算需求減少了一半。在 NarrativeQA 擴展上下文評估等基準測試中,該模型獲得了最佳理解分數,這歸功於其閃電注意力機制能夠有效捕捉局部和全局依賴關係。
軟體工程和工具利用
MiniMax-M1 專門在沙盒軟體工程環境中使用大規模強化學習進行訓練,使其能夠以驚人的精度生成和調試程式碼。在 HumanEval 和 MBPP 等編碼基準測試中,該模型的通過率與 Qwen3-235B 和 DeepSeek-R1 相當甚至超過後者,尤其是在多檔案程式碼庫和需要交叉引用長程式碼段的任務中。此外,MiniMaxAI 的早期演示展示了該模型與開發者工具整合的能力,從生成 CI/CD 管線到自動文件編寫工作流程,無所不包。
開發者如何存取MiniMax-M1?
為了促進其廣泛應用,MiniMaxAI 已將 MiniMax-M1 作為開放權重模型免費開放。開發者可以透過官方 GitHub 程式碼庫存取預先訓練的檢查點、模型權重和推理程式碼。
GitHub 上的 Open-weight 版本
MiniMaxAI 在 GitHub 上以寬鬆的開源授權授權發布了 MiniMax-M1 的模型檔案及配套腳本。有興趣的用戶可以複製 https://github.com/MiniMax-AI/MiniMax-M1 上的程式碼庫,該程式碼庫包含 40 萬和 80 萬代幣預算版本的檢查點,以及 PyTorch 和 TensorFlow 等常見機器學習框架的整合範例。
API 端點和雲端集成
除了本地部署外,MiniMaxAI 還與主流雲端供應商合作,提供託管 API 服務。透過這些合作,開發人員可以透過 RESTful 端點呼叫 MiniMax-M1,並提供 Python、JavaScript 和 Java 版本的 SDK。這些 API 包含上下文長度、專家路由閾值和令牌預算等可配置參數,可讓使用者根據用例自訂效能,同時即時監控計算消耗。
如何在實際應用中整合並使用MiniMax-M1?
要利用 MiniMax-M1 的功能,需要了解其 API 模式、長上下文提示的最佳實踐以及工具編排策略。
基本 API 使用範例
典型的 API 呼叫會傳送包含輸入文字和可選配置覆蓋的 JSON 負載。例如:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
回應傳回一個結構化的 JSON,其中包含產生的文字、令牌使用情況統計資訊和路由日誌,從而實現對專家啟動的細粒度監控。
工具使用和 MiniMax Agent
除了核心模型之外,MiniMaxAI 還引入了 MiniMax Agent,這是一個測試版代理框架,可以在背景中呼叫外部工具(從程式碼執行環境到網路爬蟲)。開發人員可以實例化一個代理會話,將模型推理與工具呼叫連結起來,例如,檢索即時資料、執行計算或更新資料庫。這種代理範式簡化了端到端應用程式開發,使 MiniMax-M1 能夠充當複雜工作流程中的協調器。
最佳實踐和陷阱
- 針對長上下文的快速工程:將輸入分解為連貫的片段,以邏輯間隔嵌入摘要,並利用「先總結後推理」的策略來保持模型焦點。
- 計算與效能的權衡:對於延遲敏感的應用程序,請嘗試降低專家閾值或減少思考預算(例如 40K 變體)。
- 監控和治理:使用路由日誌和令牌統計資料來審核專家利用率並確保符合成本預算,尤其是在生產環境中。
透過遵循這些準則,開發人員可以利用 MiniMax-M1 的優勢——廣泛的上下文處理和高效的推理——同時降低與大規模模型部署相關的風險。
如何使用 MiniMax-M1?
安裝後,可以透過簡單的 Python 腳本或互動筆記本呼叫 M1。
基本推理腳本是什麼樣的?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
此範例呼叫 40 k 預算變體;交換到 "MiniMax-AI/MiniMax-M1-80k" 解鎖全部 80 k 推理預算 ()。
如何處理超長上下文?
對於超出典型緩衝區大小的輸入,M1 支援流式標記化。使用 stream=True 標記器中的標誌以區塊的形式提供標記,並利用檢查點重啟推理來維持百萬標記序列的效能。
如何微調或調整 M1?
雖然基礎檢查點足以應對大多數任務,但研究人員可以使用程式碼庫中包含的 CISPO 程式碼進行強化學習微調。透過提供自訂獎勵函數(從程式碼正確性到語義保真度),實踐者可以將 M1 調整到特定領域的工作流程。
結論
MiniMax-M1 是一款突破性的 AI 模型,突破了長上下文語言理解和推理的界限。憑藉其混合 MoE 架構、閃電注意力機制以及 CISPO 支援的訓練方案,該模型在從法律分析到軟體工程等各種任務上均表現出色,同時顯著降低了計算成本。由於其開放權重版本和雲端 API 產品,MiniMax-M1 可供眾多渴望建置下一代 AI 應用的開發者和組織使用。隨著 AI 社群不斷探索大脈絡模型的潛力,MiniMax-M1 的創新將影響整個產業未來的研究和產品開發。
入門
CometAPI 提供了一個統一的 REST 接口,該接口在一致的端點下聚合了數百個 AI 模型(包括 ChatGPT 系列),並具有內建的 API 金鑰管理、使用配額和計費儀表板。而不需要處理多個供應商 URL 和憑證。
首先,探索模型在 游乐场 並諮詢 API指南 以獲得詳細說明。造訪前請確保您已經登入CometAPI並取得API金鑰。
最新的整合 MiniMax‑M1 API 即將出現在 CometAPI 上,敬請期待!在我們完成 MiniMax‑M1 模型上傳的同時,您可以探索我們在 模型頁面 或者嘗試一下 人工智能遊樂場. MiniMax 在 CometAPI 中的最新模型是 Minimax ABAB7-預覽 API MiniMax 視訊-01 API ,請參閱:
