

Wan2.7-Image de Alibaba, lanzado el 1 de abril de 2026, marca un avance mayor en la generación visual por IA. Este modelo unificado integra creación de texto a imagen, edición interactiva, composición multiimagen y comprensión semántica en una única arquitectura. A diferencia de los flujos tradicionales separados para generación y edición, elimina incoherencias como “caras de IA estandarizadas”, texto ilegible y colores impredecibles.
Creadores, diseñadores, mercadólogos y empresas ahora logran resultados fotorrealistas y fieles a las instrucciones con menos iteraciones. El modelo admite hasta 12 imágenes secuenciales, 9 fusiones de referencias, renderizado de texto en 12 idiomas (hasta 3,000 tokens) y control a nivel de píxel.
¿Qué es Wan2.7-Image?
Wan2.7-Image es el modelo de imágenes unificado insignia del Tongyi Lab de Alibaba dentro de la serie Wan (Tongyi Wanxiang). Aborda flujos visuales de extremo a extremo: generación de texto a imagen, transformación de imagen a imagen, edición basada en comandos e iteraciones interactivas a nivel de píxel, todo en un espacio latente compartido.
Lanzado el 1 de abril de 2026, se construye sobre los modelos de video Wan 2.x (que encabezaron los benchmarks de VBench) al desplazar el foco hacia la precisión de imagen. Aborda directamente la “fatiga estética” por rostros repetitivos, colores inestables y escasa alineación con el prompt, comunes en herramientas de IA anteriores. La familia del modelo incluye dos nombres especialmente relevantes para los usuarios: wan2.7-image y wan2.7-image-pro. La versión estándar está ajustada para mayor velocidad de generación, mientras que la versión Pro apunta a resultados profesionales, con soporte 4K de alta definición.
Diferenciador clave: arquitectura unificada. Los modelos tradicionales usan etapas desconectadas (codificador → difusión → decodificador), requiriendo inpainting por separado para editar. Wan2.7-Image mapea la semántica directamente en un espacio compartido, habilitando comprensión real en lugar de simple coincidencia de patrones de píxeles.
Por qué importa Wan2.7-Image (Contexto del sector)
Las herramientas de imagen por IA tradicionales adolecen de:
| Problema | Explicación |
|---|---|
| Flujo fragmentado | Herramientas separadas para generación, edición, inpainting |
| “Síndrome de cara de IA” | Rostros humanos repetitivos e irreales |
| Débil alineación con instrucciones | Los prompts no se siguen con precisión |
| Renderizado de texto deficiente | Texto distorsionado o ilegible |
| Salida multiimagen inconsistente | Los personajes cambian entre fotogramas |
Wan2.7-Image aborda directamente estas limitaciones con una arquitectura unificada + capa de comprensión semántica.
5 funciones clave de Wan2.7-Image
1. Personalización de avatares a nivel de estructura ósea para rostros verdaderamente únicos
Wan2.7-Image destaca en “un rostro único para cada individuo”. Admite control detallado de la estructura ósea, la forma de los ojos (almendrados, “phoenix”, hundidos, hinchados, sonrientes), contornos faciales y detalles sutiles. Esto elimina el problema de las “caras de IA estandarizadas” que plagaba modelos anteriores.

Prompt de ejemplo: “Retrato fotorrealista de una mujer de 28 años de Asia Oriental, rostro ovalado, ojos almendrados, sonrisa sutil, textura de piel detallada, iluminación natural.” Los resultados muestran una diversidad realista ideal para influencers virtuales, NPCs de juegos o branding personalizado.
2. Control de paleta de colores de precisión
Una de las funciones más prácticas es el nuevo control de paleta de colores. Alibaba afirma que los usuarios pueden introducir códigos de color específicos y proporciones para replicar estilos artísticos o fijar colores de marca. La documentación de la API formaliza esto con el parámetro color_palette, que acepta de 3 a 10 colores, con 8 recomendados. Para equipos de marca, esta es una de las funciones más claramente orientadas a empresa en el lanzamiento. Se acabaron los cambios de color aleatorios: consistencia perfecta en toda la campaña.
Cita oficial: “Dile adiós a la generación aleatoria de colores. Logra relaciones de color precisas y da vida a tu visión creativa.” — Tongyi Wanxiang.
3. Renderizado avanzado de texto multilingüe (12 idiomas, 3,000 tokens)
Renderiza texto ultralargo, tablas, fórmulas, gráficos y material infográfico con nitidez de calidad de impresión (equivalente a A4). Admite chino, inglés, japonés, coreano y 8 idiomas más. Artículos académicos, carteles, etiquetas de producto y banners multilingües logran una legibilidad casi perfecta, resolviendo una debilidad histórica de la IA.
4. Edición interactiva con precisión de píxel mediante selección de marquesina
Usa cuadros delimitadores (editRegions) o herramientas de marquesina para cambios dirigidos. Sube hasta 9 referencias e indica ediciones como “cambiar el fondo a un atardecer en la playa manteniendo el rostro, la pose y la ropa”. La precisión a nivel de píxel garantiza la preservación de la identidad.
5. Generación composicional multiimagen (hasta 12 imágenes secuenciales)
El modelo está diseñado para más que una sola generación por prompt. Alibaba indica que se puede trabajar con hasta nueve imágenes de referencia y generar hasta 12 imágenes a la vez, ideal para guiones gráficos coherentes, arquitectura y series de e‑commerce. El flujo “clic para editar” permite seleccionar áreas específicas y realizar cambios con precisión a nivel de píxel, y la documentación de la API añade edición precisa interactiva mediante un parámetro de cuadro delimitador para ediciones locales.
¿Cómo funciona Wan2.7-Image? (Análisis técnico en profundidad)
Alibaba describe Wan2.7-Image como un marco que conecta lenguaje y visuales entrenándose con conjuntos de datos amplios y diversos. En términos sencillos, el modelo no solo aprende a dibujar imágenes; también aprende cómo los prompts se mapearon a estructura visual, composición, iluminación y colocación de texto. Eso permite que el modelo interprete la intención del usuario con mayor precisión que un sistema básico de texto a imagen.
La API también muestra que el modelo está preparado para entrada multimodal. En la práctica, las solicitudes se envían mediante una estructura de mensajes de un solo turno, y el contenido puede incluir elementos de texto e imagen. Para edición, los usuarios pueden pasar múltiples imágenes más instrucciones como “mover”, “reemplazar” o “fusionar” para guiar el resultado. Es una señal clara de que Wan2.7 está diseñado como un sistema de prompt y referencias en lugar de un generador de un solo disparo.
Los documentos también exponen un ajuste de modo de razonamiento. Está habilitado por defecto y puede mejorar la calidad de salida, pero Alibaba señala que aumenta el tiempo de generación. Es una pista útil sobre el flujo del modelo: las salidas de mayor calidad pueden requerir más tiempo de inferencia interna, especialmente cuando la solicitud es textual o visualmente compleja.
Wan2.7-Image emplea un marco unificado de generación-edición en un espacio latente compartido:
- Etapa de entrada: Prompt de texto (hasta 3,000 tokens) + imágenes de referencia opcionales (hasta 9).
- Análisis semántico y modo de razonamiento (potenciado en Pro): el razonamiento en cadena analiza composición, relaciones espaciales, iluminación y lógica antes de la generación de píxeles.
- Mapeo en espacio latente compartido: la semántica se mapea directamente a rasgos visuales, sin brechas desconectadas de codificador/decodificador.
- Inferencia unificada: la generación o edición ocurre en un flujo optimizado. Las regiones de edición usan cuadros delimitadores; las paletas de color imponen proporciones.
- Salida: imágenes de alta fidelidad (768–2048×2048 estándar; 4K en Pro), con opciones JPG/PNG/WEBP, semillas para reproducibilidad y controles de seguridad.
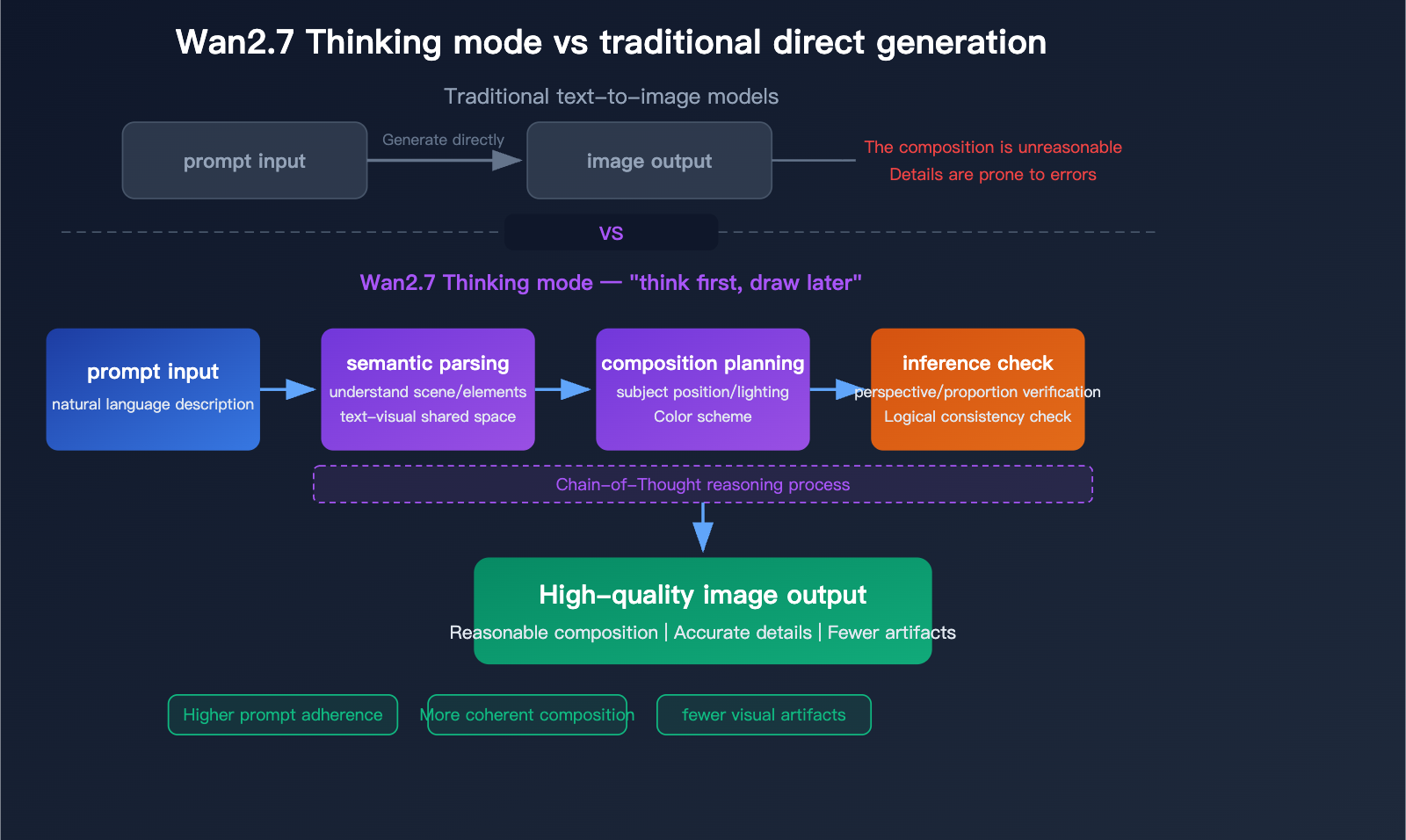
Análisis en profundidad de Wan2.7-Image-Pro: un nuevo referente en generación de imágenes por IA con calidad 4K, modo de razonamiento y renderizado de texto en 12 idiomas - Blog de Apiyi.com
El diagrama de flujo del modo de razonamiento (Pro) muestra análisis semántico → planificación de composición → verificación de inferencia, produciendo menos artefactos y mayor adherencia al prompt frente a la generación directa.
El entrenamiento con conjuntos de datos diversos habilita una comprensión profunda de la intención, la iluminación y el diseño. El aprendizaje de contexto largo (referenciado en estudios de arXiv) potencia el manejo de texto extendido.
Wan2.7-Image vs Wan2.7-Image-Pro: diferencias clave
Ambas versiones se lanzan simultáneamente, pero Pro apunta a necesidades profesionales.
| Función | Wan2.7-Image (Estándar) | Wan2.7-Image-Pro | Ideal para |
|---|---|---|---|
| Resolución máxima | 2048×2048 | 4096×4096 (4K) | Impresión/producción (Pro) |
| Modo de razonamiento | Disponible (por defecto más rápido) | Mejorado/por defecto con razonamiento más profundo | Escenas complejas (Pro) |
| Estabilidad compositiva | Sólida | Comprensión semántica superior | Proyectos comerciales (Pro) |
| Velocidad vs calidad | Iteración más rápida | Mayor fidelidad, tiempo ligeramente mayor | Prototipos (Estándar) |
| Caso de uso | Creadores generales, contenido social | Diseño empresarial, académico/impresión | Escalabilidad vs precisión |
La versión estándar se adapta a prototipos rápidos; Pro ofrece 4K listo para impresión con consistencia superior.
Cómo usar Wan2.7-Image (Paso a paso)
1. Acceso a la plataforma
Disponible vía:
- Alibaba Cloud (plataforma BaiLian)
- Herramientas oficiales de Wanxiang
- CometAPI
2. Elige el modo de flujo de trabajo
Modo A: Texto a imagen
Ejemplo de prompt:
A cinematic portrait of a cyberpunk woman, neon lighting, ultra-detailed, 8K
Modo B: Edición de imagen
- Sube la imagen
- Selecciona el área
- Introduce la instrucción
Ejemplo:
Replace background with a futuristic city
Modo C: Composición de múltiples imágenes
- Sube múltiples referencias
- Define reglas de composición
3. Ajusta parámetros finos
- Paleta de colores
- Consistencia de estilo
- Renderizado de texto
4. Exporta la salida
- Imágenes de alta resolución
- Recursos listos para uso comercial
Rendimiento en benchmarks y comparación con competidores
En pruebas ciegas de preferencia humana, Wan2.7-Image supera a GPT-Image-1.5 en calidad de texto a imagen e iguala o excede a Nano Banana Pro en renderizado de texto, fotorrealismo y conocimiento del mundo.
Tabla comparativa:
| Modelo | Renderizado de texto | Cumplimiento de instrucciones | Personalización de avatares | Referencias multiimagen | Generación/edición unificada | Resolución | Código abierto/API |
|---|---|---|---|---|---|---|---|
| Wan2.7-Image | Excelente (12 idiomas) | Superior (Modo de razonamiento) | A nivel óseo | 9 | Sí | 2K–4K | Sí/API |
| Midjourney V8 | Bueno | Moderado | Artístico sólido | Limitado | No | Alta | Solo Discord |
| FLUX | Bueno | Fuerte (simple) | Bueno | Limitado | No | Alta | Sí |
| DALL-E 3 | Moderado | Bueno | Moderado | No | No | 2K | API |
| Nano Banana Pro | Fuerte | Edición potente | Bueno | Fuerte | Parcial | Alta | Cerrado |
Wan2.7-Image lidera en flujo de trabajo unificado, texto multilingüe y control preciso, especialmente valioso para mercados no angloparlantes y pipelines profesionales.
CometAPI es una plataforma de agregación integral de APIs de grandes modelos que ofrece integración y gestión de servicios API sin fricciones. Admite múltiples APIs de generación de imágenes, como GPT-image-1.5, serie Nano Banana, Midjourney y Qwen Image Series, entre otros, a un precio inferior al del sitio oficial.
Quién debería usar Wan2.7-Image
Wan2.7-Image es especialmente relevante para equipos que necesitan velocidad y flexibilidad, no solo generación puntual de arte. Esto incluye mercadólogos de performance, diseñadores de producto, estudios de e‑commerce, equipos de contenido social y agencias que producen muchas variantes a partir del mismo brief. El soporte del modelo para entrada multiimagen, generación multi‑salida y edición basada en instrucciones lo hace especialmente atractivo para flujos donde la consistencia, la velocidad y el control del prompt importan.
Casos de uso reales
- Gaming/Entretenimiento: Genera 100 NPCs únicos en minutos.
- Marketing/E‑commerce: Carruseles coherentes con la marca y paletas exactas.
- Educación/Academia: Pósteres listos para impresión con fórmulas y tablas.
- Agencias de diseño: Guiones gráficos y revisiones del cliente mediante edición interactiva.
Las ganancias de productividad provienen de menos iteraciones y una integración de referencias sin fricciones.
Conclusión:
Alibaba Wan2.7-Image redefine la creatividad por IA al unificar generación, edición y comprensión. Sus 5 funciones clave, el espacio latente compartido y las mejoras Pro entregan resultados profesionales que los competidores aún luchan por igualar. Ya sea prototipando contenido social o produciendo visuales académicos listos para impresión, ofrece precisión y eficiencia inigualables.
Empieza hoy en wan.video o vía API en CometAPI. Para desarrolladores y empresas, la combinación de potencia, accesibilidad y superioridad respaldada por datos convierte a Wan2.7-Image en el líder indiscutible de los modelos unificados de imagen por IA para 2026 y más allá.