

GLM-5-Turbo est un nouveau LLM de base de Zhipu AI spécifiquement entraîné et ajusté pour des workflows de type agent (l’entreprise appelle l’écosystème cible scénarios OpenClaw / « lobster »). Il offre un contexte très long (jusqu’à ~200K tokens), des sorties en streaming et structurées, des taux d’erreur d’appels d’outils plus faibles (rapportés ~0,67 % dans des tests tiers) et un coût par jeton sensiblement plus bas. Le modèle vise à échanger une petite part de débit crête sur un tour unique contre une bien meilleure stabilité, une fiabilité accrue des outils, une gestion des tâches planifiées/persistantes et une exécution sur de longues chaînes — utile pour des agents autonomes, des systèmes d’orchestration et des pipelines multi-outils.
Qu’est-ce que GLM-5-Turbo ?
GLM-5-Turbo est présenté par Zhipu comme un modèle de base conçu pour l’orchestration d’agents et des workflows automatisés complexes, plutôt qu’un modèle généraliste de chat ou multimodal. Les choix de conception mettent l’accent sur :
- Un entraînement nativement favorable aux agents (usage d’outils, suivi de commandes, tâches temporisées/persistantes).
- De très grandes fenêtres de contexte et capacités de sortie pour soutenir de longues sessions, la mémoire et la planification de type chain-of-thought.
- Une inférence stable et à haut débit pour de longs flux métier et des tâches planifiées.
Contrairement aux LLM traditionnels optimisés pour le chat ou la génération de texte, GLM-5-Turbo est :
- Axé sur les agents (pas sur le chat)
- Conçu pour les environnements OpenClaw (« lobster »)
- Pensé pour des workflows autonomes multi-étapes
🦞 Que signifie « Lobster Agent » ?
Le concept « lobster » renvoie à OpenClaw, l’écosystème d’agents IA de Zhipu dans lequel les modèles :
- Utilisent des outils de manière dynamique
- Exécutent de longues chaînes de tâches
- Maintiennent une mémoire persistante
- Opèrent à travers terminaux, applications et API
GLM-5-Turbo est profondément optimisé pour ce paradigme, en résolvant des problèmes clés des agents tels que :
- La fiabilité des appels d’outils
- La décomposition des tâches
- La planification à long horizon
- La stabilité d’exécution
Fonctionnalités clés et pourquoi elles comptent
Long contexte + énorme capacité de sortie (200K / 128K)
Une fenêtre de contexte de 200K tokens et une capacité de sortie de 128K permettent à GLM-5-Turbo de :
- Conserver une mémoire étendue du contexte antérieur (conversations, sorties d’outils, résultats intermédiaires).
- Produire de très longs artefacts générés (plans multi-étapes, rapports longs, bases de code) sans recoller sans cesse le contexte.
- Héberger des agents multi-tours qui doivent retenir tout l’historique d’exécution pour une prise de décision précise.
Il s’agit d’un choix technique délibéré pour les agents — au lieu de scinder les tâches en prompts courts, les agents peuvent maintenir un état cohérent sur des milliers de tours ou d’étapes.
Des primitives d’agent intégrées à l’entraînement
Plutôt que d’adapter a posteriori un modèle généraliste aux tâches d’agent, GLM-5-Turbo a été entraîné avec des objectifs de type agent (p. ex. comportement d’invocation d’outils, analyse de commandes/arguments). L’effet revendiqué est moins d’hallucinations lors des appels d’outils, des plans multi-étapes plus stables, et une latence améliorée lors de longues exécutions — autant d’atouts lorsque l’automatisation doit enchaîner de nombreuses API ou outils externes de manière fiable.
Débit et stabilité d’exécution
La variante GLM-5-Turbo améliore la stabilité d’exécution et le débit pour de longs flux métier par rapport à des modèles généraux — le discours marketing met l’accent sur une « exécution à haut débit » et une « stabilité de réponse de premier plan » parmi des modèles similaires. Ces points sont significatifs pour les déploiements d’agents en entreprise, où une étape échouée peut casser tout un pipeline. Des benchmarks tiers indépendants sont encore en cours d’émergence.
Données de benchmark de GLM-5-Turbo
Remarque : Zhipu a publié des évaluations internes, et des benchmarks tiers/académiques pour GLM-5 sont disponibles. GLM-5-Turbo vient d’être lancé ; les exécutions de benchmark indépendantes par la communauté prendront du temps à apparaître. Ci-dessous, nous listons les chiffres publiés les plus défendables et le contexte.
GLM-5 (référence) — métriques publiées représentatives
GLM-5 de Zhipu (le prédécesseur phare de Turbo) affiche de solides classements dans de nombreuses tâches d’ingénierie/workflow — par exemple :
- SWE-bench Verified : 77,8 (rapporté dans la documentation GLM-5 comme un score leader parmi les modèles ouverts).
- Terminal Bench 2.0 : 56,2 (rapporté comme la meilleure performance open-model sur la distribution donnée).
Ces chiffres établissent GLM-5 comme une base élevée en ingénierie logicielle et tâches d’exécution ; GLM-5-Turbo est positionné pour échanger une partie de l’accent sur la taille/le nombre de paramètres contre une meilleure fiabilité d’agent et un meilleur débit. GLM-5-Turbo a montré ~0,67 % d’erreur d’appel d’outils dans leurs comparaisons, sensiblement plus bas que des exécutions GLM-5 de comparaison allant de ~2,33 % à 6,41 %.
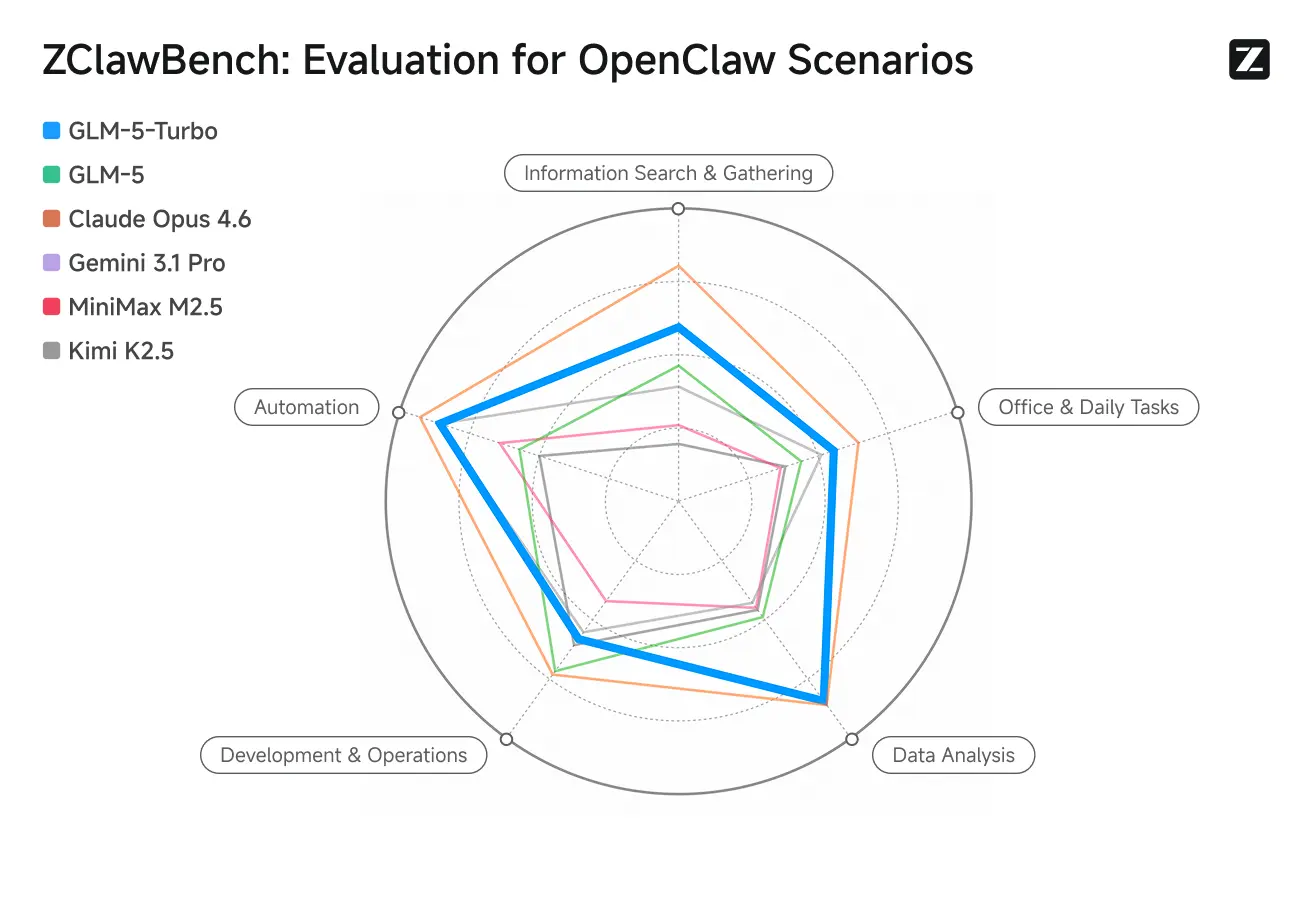
ZClawBench : Benchmark Test for OpenClaw Proxy Scenarios
Zhipu a également publié le benchmark ZClawBench pour l’évaluation d’agents intelligents. Dans des tests à l’aveugle couvrant des domaines variés comme le développement de code, l’analyse de données et la création de contenu, le nouveau modèle nom de code Pony-Alpha-2 a obtenu la préférence de 90 % des répondants.
Tarification et disponibilité (qui le vend et à quel prix)
Zhipu a appliqué une augmentation de prix API d’environ ~20 % pour l’offre GLM-5-Turbo au lancement et a simultanément introduit des paliers d’abonnement « Lobster Package » destinés à lisser le prix par jeton pour les déploiements d’agents.
Paliers d’abonnement signalés (forfaits d’exemple)
Deux forfaits Lobster illustratifs (prix convertis et approximatifs) :
- Offre Lobster d’entrée :
39 CNY / mois (US$5.66) pour 35,000,000 tokens. - Offre Lobster intermédiaire :
99 CNY / mois (US$14.36) pour 100,000,000 tokens.
À partir de ces chiffres publiés, le coût par 1 million de tokens est approximativement :
- Offre d’entrée : ~US$0.162 par 1M tokens.
- Offre intermédiaire : ~US$0.144 par 1M tokens.
Ces montants par 1M sont de simples conversions du coût d’abonnement publié et du plafond de tokens, et illustrent l’économie pour des charges d’agents à grand volume. (Calculs basés sur les devises et quantités de tokens rapportées par la presse.)
Prix API
Annonce représentative sur la place de marché (CometAPI) : $0.96 par 1M de tokens en entrée et $3.20 par 1M de tokens en sortie pour GLM-5-Turbo.
La page de tarification développeur de Zhipu (Z.ai) indique un tarif direct légèrement plus élevé pour GLM-5-Turbo : $1.20 par 1M de tokens en entrée et $4.00 par 1M de tokens en sortie (les tarifs en entrée mis en cache sont plus bas).
GLM-5-Turbo vs GLM-5 — comparaison côte à côte
À un niveau élevé :
- GLM-5 = modèle de base phare polyvalent (raisonnement, code, benchmarks)
- GLM-5-Turbo = variante optimisée pour les agents de GLM-5 (axée sur les longs workflows, l’usage d’outils, la stabilité)
GLM-5-Turbo n’est pas une architecture de modèle complètement nouvelle, mais une version spécialisée et optimisée pour la production de GLM-5 conçue pour des systèmes d’agents comme OpenClaw.
Positionnement central
| Modèle | Positionnement |
|---|---|
| GLM-5 | Modèle LLM phare polyvalent (raisonnement, code, benchmarks) |
| GLM-5-Turbo | Modèle axé agents (automatisation, orchestration, usage d’outils) |
👉 En termes simples :
- Utilisez GLM-5 → lorsque vous voulez une intelligence maximale
- Utilisez GLM-5-Turbo → lorsque vous voulez une automatisation/agents stables
Comparaison des capacités d’agent (LE PLUS IMPORTANT)
GLM-5 (capacité agent) prend déjà en charge :
- L’utilisation d’outils
- Le raisonnement multi-étapes
- Les agents de codage
Mais limites :
- Peut perdre du contexte sur de longues chaînes
- Les appels d’outils peuvent se dégrader avec le temps
- Nécessite plus de logique d’orchestration
GLM-5-Turbo est explicitement optimisé pour les agents :
Améliorations clés :
- Fiabilité des appels d’outils ↑
- Décomposition des tâches (planification) ↑
- Cohérence sur longues chaînes ↑
- Support d’exécution persistante ↑
Exemple d’amélioration :
- Exécution stable sur 10+ étapes sans perte de contexte
👉 C’est crucial pour :
- Les systèmes de type AutoGPT
- Les workflows multi-agents
- L’automatisation SaaS
Vitesse et efficacité
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Vitesse d’inférence | Modérée | Plus rapide |
| Débit | Standard | Plus élevé |
| Latence sur longues tâches | Peut se dégrader | Optimisée |
GLM-5-Turbo est conçu pour résoudre un vrai problème de l’industrie :
Les grands modèles ralentissent ou se brisent durant de longs workflows
Comparaison des prix
| Modèle | Entrée ($/1M tokens) | Sortie ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo est plus cher (~20 % de plus)
Pourquoi plus cher ?
Parce qu’il apporte :
- Une meilleure fiabilité d’orchestration
- Une stabilité de production supérieure
- Des optimisations spécifiques aux agents
👉 En entreprise :
- Vous payez plus par jeton
- Mais vous réduisez le coût des échecs + les reprises
| Attribut | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Objectif principal | Modèle de base phare généraliste (capacités larges, code/benchmarks) | Modèle de base optimisé pour les agents/« OpenClaw » / lobster |
| Fenêtre de contexte | (annoncée comme élevée ; GLM-5 met l’accent sur ~200K (GLM-5 prend aussi en charge un long contexte) | 200,000 tokens (documenté). |
| Nombre max. de tokens en sortie | (grand, selon le modèle) | 128,000 tokens (documenté). |
| Scores de benchmark notables | SWE-bench : 77,8 ; Terminal Bench 2.0 : 56,2 (chiffres rapportés de GLM-5). | Les évaluations internes revendiquent une stabilité et un débit améliorés sur longues chaînes pour les workflows d’agents ; benchmarks publics indépendants en attente. |
| Modalités | Texte (principal), la famille GLM possède des variantes vision dans des modèles frères | Texte uniquement (selon la doc) — optimisé pour des agents basés sur des outils. |
| Cas d’usage recommandés | Large : chat, code, raisonnement, contenu | Orchestration d’agents, invocation d’outils, automatisation à long horizon |
| Tarification | Tarifs GLM-5 existants (varient selon le plan) | Nouveau lancement — ~20 % de hausse de prix API rapportée ; nouveaux paliers d’abonnement Lobster introduits |
Comment utiliser GLM-5-Turbo
CometAPI — un accès API unique à de nombreux modèles (compatible OpenAI)
CometAPI liste GLM-5-Turbo comme disponible et fournit une base URL et un SDK compatibles OpenAI. Utilisez la chaîne de modèle qu’ils publient (leur site liste GLM-5-Turbo à un prix similaire). Exemples adaptés de la documentation CometAPI :
curl (CometAPI) :
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
La valeur de CometAPI réside dans la commodité d’un agrégateur (intégration unique pour de nombreux modèles). Confirmez l’identifiant exact du modèle dans le tableau de bord CometAPI avant l’appel.
Bonnes pratiques pour construire des agents Lobster / OpenClaw avec GLM-5-Turbo
- Concevez pour la fiabilité, pas pour la latence brute : l’avantage de Turbo est un taux d’échec d’appels d’outils plus faible sur de longues chaînes. Structurez les exécutions d’agent pour privilégier des complétions robustes (reprises, appels d’outils idempotents) plutôt que de minuscules gains sur le premier jeton.
- Utilisez le streaming et des appels d’outils incrémentaux : adoptez des sorties en flux/segmentées pour réduire le retravail et permettre une invocation d’outils précoce lorsque pertinent. GLM-5-Turbo prend en charge le streaming.
- Sorties structurées pour les parseurs : préférez le JSON ou des résultats bien formatés pour un parsing déterministe en aval. Turbo prend en charge les sorties structurées.
- Planifiez la mise en agenda / la persistance : si votre agent doit vérifier périodiquement ou exécuter des tâches en arrière-plan, utilisez les meilleures sémantiques de temps et les fonctionnalités de cache de Turbo pour éviter de replanifier à chaque cycle.
- Instrumentez les appels d’outils et les solutions de repli : journalisez les appels d’outils et concevez des repli gracieux (p. ex. retenter avec une légère température ou appeler un outil de secours) car les workflows agentiques sont fragiles si une seule API externe échoue. Turbo réduit les taux d’erreur mais n’élimine pas les défaillances externes.
Les développeurs peuvent accéder aux API GLM-5 et GLM-5-Turbo via CometAPI dès maintenant. Pour commencer, consultez le guide API pour des instructions détaillées. Avant d’y accéder, assurez-vous d’être connecté à CometAPI et d’avoir obtenu la clé API. CometAPI offre un prix bien inférieur au tarif officiel pour vous aider à intégrer.
Prêt à démarrer ? → Inscrivez-vous à GLM-5 et GLM-5-Turbo dès aujourd’hui !