GLM-4.6 est la dernière version majeure de la famille GLM de Z.ai (anciennement Zhipu AI) : un modèle MoE (Mélange d’experts) de 4e génération, modèle de langage de grande taille, optimisé pour les workflows agentiques, le raisonnement sur long contexte et le codage en conditions réelles. Cette version met l’accent sur l’intégration pratique agents/outils, une très grande fenêtre de contexte, et la disponibilité de poids ouverts pour un déploiement local.
Fonctionnalités clés
- Contexte long — fenêtre de contexte native de 200K tokens (étendue depuis 128K). (docs.z.ai)
- Capacités de codage et agentiques — améliorations annoncées sur les tâches de codage en conditions réelles et meilleure invocation d’outils par les agents.
- Efficacité — ~30% de consommation de tokens en moins rapportés vs GLM-4.5 dans les tests de Z.ai.
- Déploiement et quantification — première intégration annoncée en FP8 et Int4 pour les puces Cambricon ; prise en charge FP8 native sur Moore Threads via vLLM.
- Taille du modèle et type de tenseur — les artefacts publiés indiquent un modèle à ~357B paramètres (tenseurs BF16 / F32) sur Hugging Face.
Détails techniques
Modalités et formats. GLM-4.6 est un LLM uniquement texte (modalités d’entrée et de sortie : texte). Longueur de contexte = 200K tokens ; sortie maximale = 128K tokens.
Quantification et prise en charge matérielle. L’équipe indique une quantification FP8/Int4 sur les puces Cambricon et une exécution FP8 native sur les GPU Moore Threads utilisant vLLM pour l’inférence — important pour réduire le coût d’inférence et permettre des déploiements sur site et sur des clouds domestiques.
Outils et intégrations. GLM-4.6 est distribué via l’API de Z.ai, des réseaux de fournisseurs tiers (par ex. CometAPI), et intégré dans des agents de codage (Claude Code, Cline, Roo Code, Kilo Code).
Détails techniques
Modalités et formats. GLM-4.6 est un LLM uniquement texte (modalités d’entrée et de sortie : texte). Longueur de contexte = 200K tokens ; sortie maximale = 128K tokens.
Quantification et prise en charge matérielle. L’équipe indique une quantification FP8/Int4 sur les puces Cambricon et une exécution FP8 native sur les GPU Moore Threads utilisant vLLM pour l’inférence — important pour réduire le coût d’inférence et permettre des déploiements sur site et sur des clouds domestiques.
Outils et intégrations. GLM-4.6 est distribué via l’API de Z.ai, des réseaux de fournisseurs tiers (par ex. CometAPI), et intégré dans des agents de codage (Claude Code, Cline, Roo Code, Kilo Code).
Performances de référence
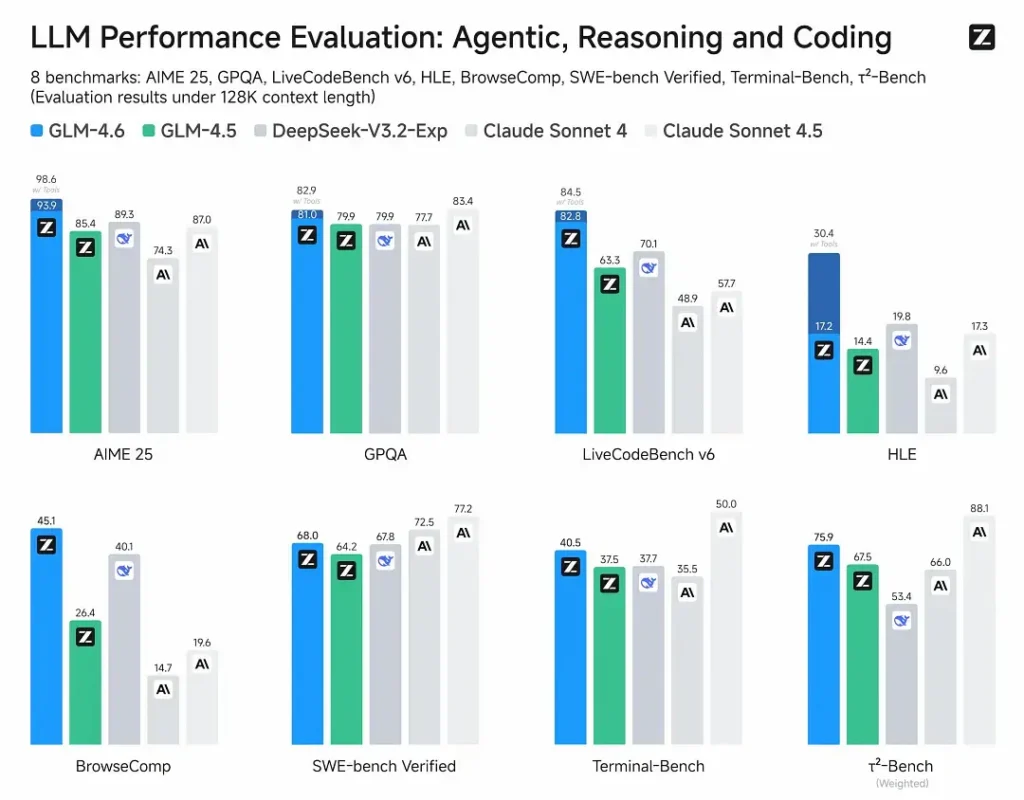
- Évaluations publiées : GLM-4.6 a été testé sur huit benchmarks publics couvrant les agents, le raisonnement et le codage et montre des gains nets par rapport à GLM-4.5. Sur des tests de codage en conditions réelles évalués par des humains (CC-Bench étendu), GLM-4.6 utilise ~15% de tokens en moins vs GLM-4.5 et affiche un taux de victoire de ~48.6% vs Claude Sonnet 4 d’Anthropic (quasi-parité sur de nombreux classements).
- Positionnement : les résultats affirment que GLM-4.6 est compétitif face aux principaux modèles domestiques et internationaux (exemples cités : DeepSeek-V3.1 et Claude Sonnet 4).
Limites et risques
- Hallucinations et erreurs : comme tous les LLM actuels, GLM-4.6 peut commettre des erreurs factuelles — la documentation de Z.ai avertit explicitement que les sorties peuvent contenir des erreurs. Les utilisateurs doivent appliquer des vérifications et du retrieval/RAG pour les contenus critiques.
- Complexité du modèle et coût de service : un contexte de 200K et des sorties très grandes augmentent fortement les exigences de mémoire et de latence et peuvent accroître les coûts d’inférence ; une quantification/ingénierie d’inférence est nécessaire pour fonctionner à l’échelle.
- Écarts selon les domaines : bien que GLM-4.6 rapporte de solides performances agent/codage, certains rapports publics signalent qu’il reste derrière certaines versions de modèles concurrents sur des microbenchmarks spécifiques (par ex., certaines métriques de codage vs Sonnet 4.5). Évaluer par tâche avant de remplacer des modèles en production.
- Sécurité et politique : des poids ouverts augmentent l’accessibilité mais soulèvent aussi des questions de gouvernance (les mitigations, garde-fous et red-teaming restent à la charge de l’utilisateur).
Cas d’usage
- Systèmes agentiques et orchestration d’outils : longues traces d’agent, planification multi-outils, invocation dynamique d’outils ; l’optimisation agentique du modèle est un argument clé.
- Assistants de codage en conditions réelles : génération de code multi-tours, revue de code et assistants IDE interactifs (intégrés dans Claude Code, Cline, Roo Code — selon Z.ai). Les améliorations d’efficacité en tokens le rendent attractif pour des plans développeur à usage intensif.
- Workflows de documents longs : résumé, synthèse multi-documents, longues revues juridiques/techniques grâce à la fenêtre de 200K.
- Création de contenu et personnages virtuels : dialogues prolongés, maintien cohérent de persona dans des scénarios multi-tours.
Comparaison de GLM-4.6 avec d’autres modèles
- GLM-4.5 → GLM-4.6 : changement d’échelle de la taille de contexte (128K → 200K) et de l’efficacité en tokens (~15% de tokens en moins sur CC-Bench) ; meilleure utilisation des agents/outils.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5 : Z.ai rapporte une quasi-parité sur plusieurs classements et un taux de victoire de ~48.6% sur les tâches de codage réelles de CC-Bench (concurrence serrée, avec certains microbenchmarks où Sonnet reste en tête). Pour de nombreuses équipes d’ingénierie, GLM-4.6 est positionné comme une alternative rentable.
- GLM-4.6 vs autres modèles à long contexte (DeepSeek, variantes Gemini, famille GPT-4) : GLM-4.6 met l’accent sur le grand contexte et les workflows de codage agentiques ; les forces relatives dépendent des métriques (efficacité en tokens/intégration des agents vs précision de synthèse de code brute ou pipelines de sécurité). La sélection empirique doit être guidée par la tâche.
Zhipu AI’s dernier modèle phare GLM-4.6 publié : 355B de paramètres au total, 32B actifs. Surpasse GLM-4.5 dans toutes les capacités clés.
- Codage : S’aligne avec Claude Sonnet 4, meilleur en Chine.
- Contexte : Étendu à 200K (depuis 128K).
- Raisonnement : Amélioré, prend en charge l’appel d’outils pendant l’inférence.
- Recherche : Appel d’outils et performances des agents améliorés.
- Rédaction : Mieux aligné sur les préférences humaines en matière de style, lisibilité et jeu de rôle.
- Multilingue : Traduction entre langues améliorée.
