

GLM-5-Turbo è un nuovo LLM foundation di Zhipu AI, specificamente addestrato e ottimizzato per flussi di lavoro in stile agent (l’azienda definisce l’ecosistema di riferimento OpenClaw / scenari “lobster”). Offre un contesto molto ampio (fino a ~200K token), output in streaming e strutturati, tassi di errore inferiori nelle chiamate agli strumenti (riportati a ~0,67% in test di terze parti) e un prezzo per token significativamente più basso. Il modello punta a sacrificare una piccola parte del throughput di picco in interazioni singole in cambio di una stabilità molto migliore, maggiore affidabilità nell’uso degli strumenti, migliore gestione di attività pianificate/persistenti ed esecuzione di catene lunghe—utile per agenti autonomi, sistemi di orchestrazione e pipeline multi-tool.
Che cos’è GLM-5-Turbo?
GLM-5-Turbo è presentato da Zhipu come un modello foundation progettato appositamente per l’orchestrazione di agenti e flussi di lavoro automatizzati complessi piuttosto che come un modello generico per chat o multimodale. Le scelte progettuali enfatizzano:
- Addestramento nativo orientato agli agenti (uso di strumenti, esecuzione di comandi, attività temporizzate/persistenti).
- Finestre di contesto molto ampie e grande capacità di output per supportare sessioni lunghe, memoria e pianificazione chain-of-thought.
- Inferenza stabile e ad alto throughput per flussi aziendali lunghi e attività pianificate.
A differenza dei tradizionali LLM ottimizzati per la chat o la generazione di testo, GLM-5-Turbo è:
- Agent-first (non chat-first)
- Costruito per ambienti OpenClaw (“lobster”)
- Progettato per flussi di lavoro autonomi multi-step
🦞 Che cosa significa “Lobster Agent”?
Il concetto di “lobster” si riferisce a OpenClaw, l’ecosistema di agenti AI di Zhipu in cui i modelli:
- Usano gli strumenti in modo dinamico
- Eseguono lunghe catene di attività
- Mantengono memoria persistente
- Operano tra terminali, app e API
GLM-5-Turbo è profondamente ottimizzato per questo paradigma, risolvendo problemi chiave degli agenti come:
- Affidabilità delle chiamate agli strumenti
- Scomposizione dei compiti
- Pianificazione a lungo orizzonte
- Stabilità di esecuzione
Caratteristiche principali e perché contano
Contesto lungo + enorme capacità di output (200K / 128K)
Una finestra di contesto da 200K token e una capacità di output da 128K consentono a GLM-5-Turbo di:
- Conservare una memoria estesa del contesto precedente (conversazioni, output degli strumenti, risultati intermedi).
- Produrre artefatti generati molto lunghi (piani multi-fase, report lunghi, codebase) senza dover ricucire ripetutamente il contesto.
- Supportare agenti multi-turno che devono mantenere l’intera cronologia di esecuzione per prendere decisioni accurate.
Si tratta di una scelta tecnica deliberata per gli agenti — invece di suddividere i compiti in prompt brevi, gli agenti possono mantenere uno stato coerente attraverso migliaia di turni conversazionali o passaggi.
Primitive agent integrate nell’addestramento
Invece di adattare in un secondo momento un modello general-purpose a compiti da agente, GLM-5-Turbo è stato addestrato con obiettivi in stile agent (ad esempio comportamento di invocazione degli strumenti, parsing di comandi/argomenti). L’effetto dichiarato è meno allucinazioni durante le chiamate agli strumenti, piani multi-step più stabili e latenza migliorata in esecuzioni lunghe — tutti aspetti preziosi quando l’automazione deve concatenare in modo affidabile molte API o strumenti esterni.
Throughput e stabilità di esecuzione
La variante GLM-5-Turbo migliora la stabilità di esecuzione e il throughput per flussi aziendali lunghi rispetto ai grandi modelli generalisti — il linguaggio di marketing enfatizza “esecuzione ad alto throughput” e “stabilità di risposta leader” tra modelli simili. Sono aspetti rilevanti per deployment enterprise di agenti, dove un passaggio fallito può interrompere un’intera pipeline. I benchmark indipendenti di terze parti sono ancora in fase di pubblicazione.
Dati di benchmark di GLM-5-Turbo
Nota: Zhipu ha pubblicato valutazioni interne e sono disponibili benchmark accademici/di terze parti per GLM-5. GLM-5-Turbo è stato rilasciato da poco; i benchmark indipendenti della community richiederanno tempo per emergere. Di seguito elenchiamo i dati e il contesto pubblicati più difendibili.
GLM-5 (riferimento) — metriche pubblicate rappresentative
Il GLM-5 di Zhipu (il predecessore di punta di Turbo) riporta ottimi risultati in molte attività di engineering/workflow — ad esempio:
- SWE-bench Verified: 77,8 (riportato nella documentazione GLM-5 come punteggio leader tra i modelli open).
- Terminal Bench 2.0: 56,2 (riportato come miglior prestazione tra i modelli open sulla distribuzione indicata).
Questi numeri stabiliscono GLM-5 come una base elevata in attività di ingegneria software ed esecuzione; GLM-5-Turbo è posizionato per sacrificare parte dell’enfasi su dimensione grezza/parametri a favore di migliore affidabilità agent e throughput. GLM-5-Turbo ha mostrato un errore nelle chiamate agli strumenti di ~0,67% nelle loro esecuzioni comparative, significativamente inferiore rispetto alle esecuzioni del provider GLM-5 comparato che variavano da ~2,33% a 6,41%.
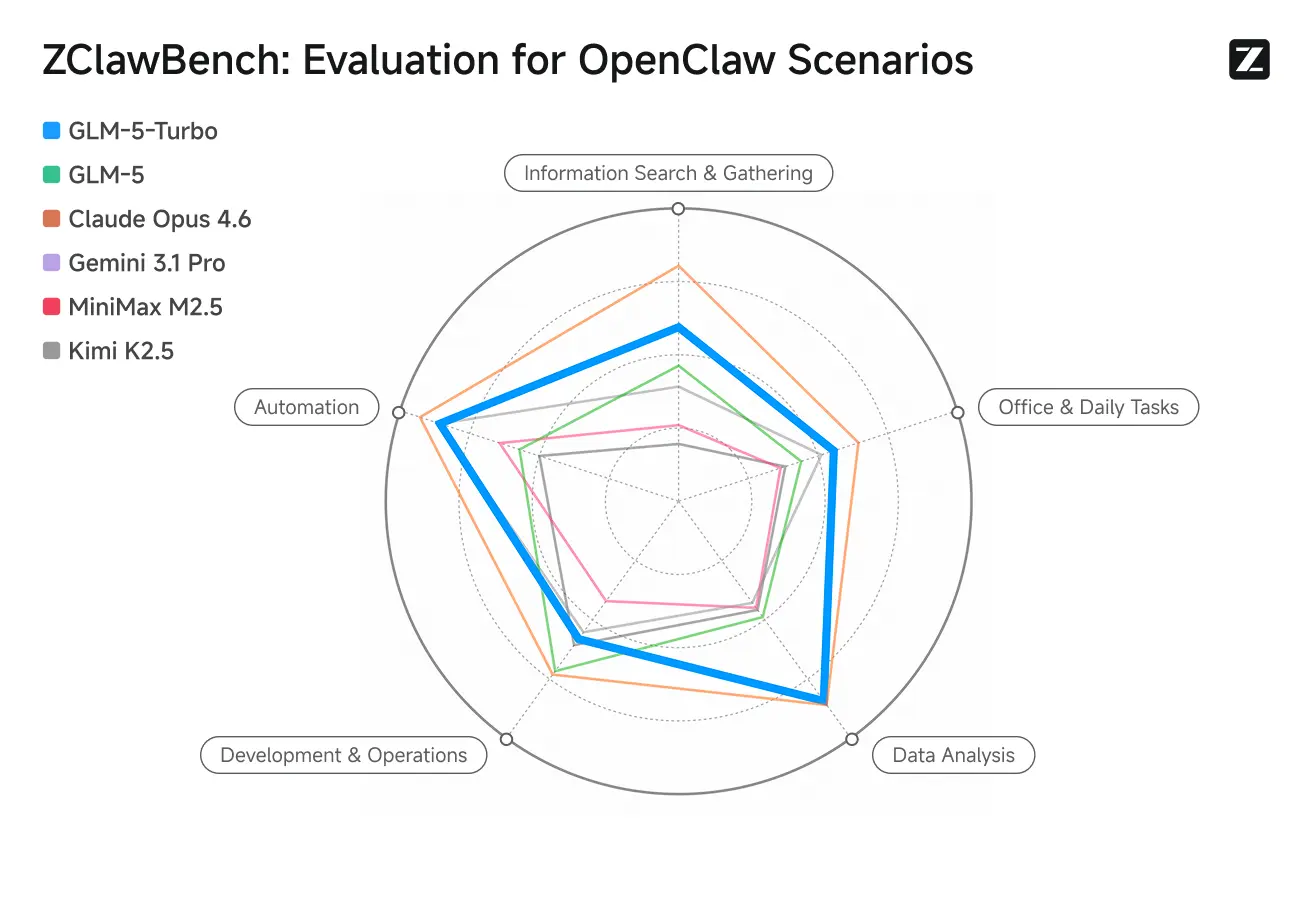
ZClawBench: benchmark test per scenari proxy OpenClaw
Zhipu ha inoltre rilasciato il benchmark ZClawBench per valutare agenti intelligenti. In test alla cieca che coprivano ambiti diversi come sviluppo software, analisi dei dati e creazione di contenuti, il nuovo modello in codice Pony-Alpha-2 ha ottenuto il favore del 90% dei partecipanti.
Prezzi e disponibilità (chi lo vende e quanto costa)
Zhipu ha implementato un aumento del prezzo API di ~20% per l’offerta GLM-5-Turbo al rilascio e ha contemporaneamente introdotto livelli di abbonamento “Lobster Package” pensati per rendere più regolare il costo dei token per i deployment agent.
Livelli di abbonamento riportati (pacchetti di esempio)
Due pacchetti Lobster illustrativi (i prezzi sono conversioni riportate e approssimative):
- Piano Entry Lobster: ~39 CNY / mese (~US$5,66) per 35.000.000 token.
- Piano Mid Lobster: ~99 CNY / mese (~US$14,36) per 100.000.000 token.
Usando questi numeri pubblicati, il costo per 1 milione di token è approssimativamente:
- Piano Entry: ~US$0,162 per 1M token.
- Piano Mid: ~US$0,144 per 1M token.
Questi valori per 1M sono semplici conversioni del costo di abbonamento pubblicato e del limite di token, e illustrano l’economia per carichi agent ad alto volume. (Calcoli basati su valuta e quantità di token riportate dalla stampa.)
Prezzo API
Listing rappresentativo sul marketplace (CometAPI): $0,96 per 1M token di input e $3,20 per 1M token di output per GLM-5-Turbo.
La pagina prezzi per sviluppatori di Zhipu (Z.ai) indica una tariffa diretta leggermente più alta per GLM-5-Turbo: $1,20 per 1M token di input e $4,00 per 1M token di output (le tariffe per input in cache sono inferiori).
GLM-5-Turbo vs GLM-5 — confronto affiancato
A grandi linee:
- GLM-5 = modello foundation di punta general-purpose (forte in ragionamento, coding, benchmark)
- GLM-5-Turbo = variante ottimizzata per agenti di GLM-5 (focalizzata su flussi lunghi, uso degli strumenti, stabilità)
GLM-5-Turbo non è un’architettura di modello completamente nuova, ma una versione specializzata e ottimizzata per la produzione di GLM-5 progettata per sistemi agent come OpenClaw.
Posizionamento core
| Model | Positioning |
|---|---|
| GLM-5 | Modello LLM flagship general-purpose (ragionamento, coding, benchmark) |
| GLM-5-Turbo | Modello agent-first (automazione, orchestrazione, uso di strumenti) |
👉 In termini semplici:
- Usa GLM-5 → quando vuoi massima intelligenza
- Usa GLM-5-Turbo → quando vuoi automazione / agenti stabili
Confronto delle capacità agent (PIÙ IMPORTANTE)
GLM-5 (capacità agent), supporta già:
- Uso di strumenti
- Ragionamento multi-step
- Agenti di coding
Ma presenta limiti:
- Può perdere contesto in catene lunghe
- Le chiamate agli strumenti possono degradarsi nel tempo
- Richiede più logica di orchestrazione
GLM-5-Turbo è esplicitamente ottimizzato per gli agenti:
Miglioramenti principali:
- Affidabilità delle chiamate agli strumenti ↑
- Scomposizione del compito (pianificazione) ↑
- Coerenza su catene lunghe ↑
- Supporto all’esecuzione persistente ↑
Esempio di miglioramento:
- Esecuzione stabile su oltre 10 passaggi senza perdere contesto
👉 Questo è fondamentale per:
- Sistemi in stile AutoGPT
- Flussi di lavoro multi-agent
- Automazione SaaS
Velocità ed efficienza
| Aspetto | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Velocità di inferenza | Moderata | Più veloce |
| Throughput | Standard | Più alto |
| Latenza in compiti lunghi | Può degradarsi | Ottimizzata |
GLM-5-Turbo è progettato per risolvere un problema reale del settore:
I modelli di grandi dimensioni rallentano o si interrompono durante flussi di lavoro lunghi
Confronto prezzi
| Model | Input ($/1M token) | Output ($/1M token) |
|---|---|---|
| GLM-5 | ~$1,00 | ~$3,20 |
| GLM-5-Turbo | ~$1,20 | ~$4,00 |
👉 GLM-5-Turbo è più costoso (~20% in più)
Perché costa di più?
Perché offre:
- Migliore affidabilità di orchestrazione
- Maggiore stabilità in produzione
- Ottimizzazioni specifiche per agenti
👉 In ambito enterprise:
- Paghi di più per token
- Ma riduci costo dei fallimenti + retry
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Obiettivo principale | Modello foundation flagship generalista (capacità ampie, forte coding/benchmark) | Modello foundation ottimizzato per agent/“OpenClaw” / lobster |
| Finestra di contesto | (riportata alta; GLM-5 si concentra su ~200K (GLM-5 supporta anch’esso un contesto lungo) | 200.000 token (esplicitamente documentato). |
| Token massimi in output | (ampia, dipendente dal modello) | 128.000 token (documentato). |
| Punteggi di benchmark notevoli | SWE-bench: 77,8; Terminal Bench 2.0: 56,2 (numeri riportati per GLM-5). | Le valutazioni interne dichiarano maggiore stabilità su catene lunghe e throughput per flussi agent; benchmark pubblici indipendenti in attesa. |
| Modalità | Testo (primario), la famiglia GLM ha varianti vision in modelli affini | Solo testo (secondo la documentazione) — ottimizzato per agent basati su strumenti. |
| Casi d’uso consigliati | Ampi: chat, codice, ragionamento, contenuti | Orchestrazione di agenti, invocazione di strumenti, automazione a lungo orizzonte |
| Prezzo | Prezzi GLM-5 esistenti (variabili in base al piano) | Nuovo lancio — riportato aumento del prezzo API di ~20%; introdotti nuovi livelli di abbonamento Lobster |
Come usare GLM-5-Turbo
CometAPI — accesso API unico a molti modelli (compatibile OpenAI)
CometAPI elenca GLM-5-Turbo come disponibile e fornisce una base URL e SDK compatibili con OpenAI. Usa la stringa modello che pubblicano (il loro sito elenca GLM-5-Turbo con prezzi simili). Esempi adattati dalla documentazione CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
Il valore di CometAPI è la comodità da aggregatore (un’unica integrazione per molti modelli). Conferma l’esatto model slug nel dashboard CometAPI prima di effettuare la chiamata.
Best practice nella costruzione di agenti Lobster / OpenClaw con GLM-5-Turbo
- Progetta per l’affidabilità, non per la latenza pura: il vantaggio di Turbo è il minor tasso di fallimento delle chiamate agli strumenti in catene lunghe. Struttura le esecuzioni agent in modo da preferire completamenti robusti (retry, chiamate idempotenti agli strumenti) rispetto a minimi guadagni sul first-token.
- Usa streaming e chiamate agli strumenti incrementali: sfrutta output in streaming/chunked per ridurre il lavoro da rifare e consentire l’invocazione anticipata degli strumenti dove opportuno. GLM-5-Turbo supporta lo streaming.
- Output strutturati per i parser: preferisci JSON o risultati ben formattati per un parsing deterministico da parte degli strumenti downstream. Turbo supporta output strutturati.
- Pianifica scheduling / persistenza: se il tuo agente deve controllare periodicamente o eseguire task in background, usa le migliori semantiche temporali e funzionalità di caching di Turbo per evitare di ripianificare a ogni ciclo.
- Strumenta chiamate agli strumenti e fallback: registra le chiamate agli strumenti e progetta fallback eleganti (ad esempio retry con lieve variazione di temperature o chiamata a uno strumento di backup), poiché i flussi agentici sono fragili se una singola API esterna fallisce. Turbo riduce i tassi di errore ma non elimina i guasti esterni
Gli sviluppatori possono accedere subito alle API di GLM-5 e GLM-5 turbo tramite CometAPI. Per iniziare, consulta la guida API per istruzioni dettagliate. Prima di accedere, assicurati di aver effettuato l’accesso a CometAPI e di aver ottenuto la chiave API. CometAPI offre un prezzo molto più basso rispetto al prezzo ufficiale per aiutarti nell’integrazione.
Pronto a partire?→ Registrati oggi stesso a GLM-5 e GLM-5 turbo !