
Qwen2.5-Omni-7B API は、モデルと対話するための OpenAI 互換のメソッドを開発者に提供し、テキスト、画像、音声、ビデオ入力の処理を可能にし、テキストと自然な音声応答の両方をリアルタイムで生成します。
Qwen2.5-Omni-7Bとは何ですか?
Qwen2.5-Omni-7B は、7 億のパラメータを誇る Alibaba の主力マルチモーダル AI モデルです。複数のデータ モダリティを処理および理解するように設計されており、テキスト、画像、オーディオ、ビデオの入力をサポートしています。このモデルは、リアルタイムの音声およびビデオ インタラクションを容易にし、さまざまなアプリケーションに使用できる多目的ツールとなっています。
Qwen2.5-Omni-7Bの主な特徴
- マルチモーダル処理: テキスト、画像、音声、ビデオなど、多様な入力を処理でき、包括的なデータの理解を可能にします。
- リアルタイムのインタラクション: 低遅延処理をサポートし、リアルタイムの音声およびビデオ会話を可能にします。
- 考える人と話す人のアーキテクチャ: 「Thinker」がデータの処理と理解を管理し、「Talker」が流暢な音声出力を生成するデュアルアーキテクチャシステムを採用しています。
- 時間調整マルチモーダル RoPE (TMRoPE): TMRoPE を利用して、さまざまなモダリティ間で時間データを正確に同期し、一貫した理解と応答の生成を保証します。
パフォーマンスメトリクス
ベンチマークの成果
Qwen2.5-Omni-7Bは、さまざまなベンチマークで優れたパフォーマンスを発揮しました。
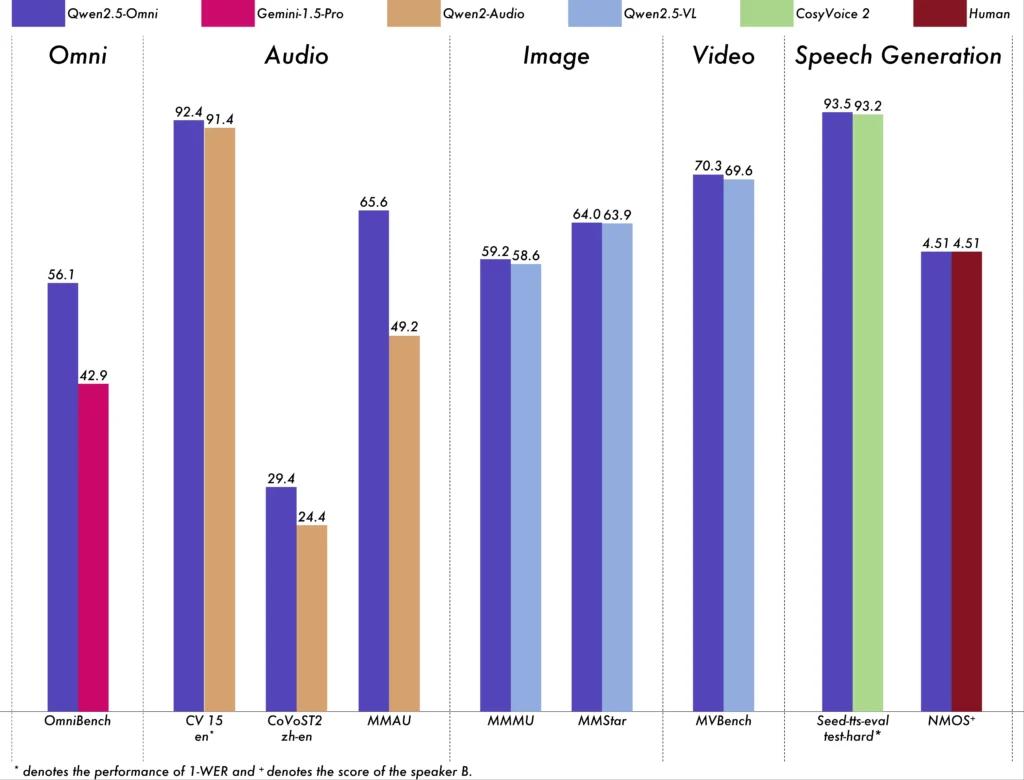
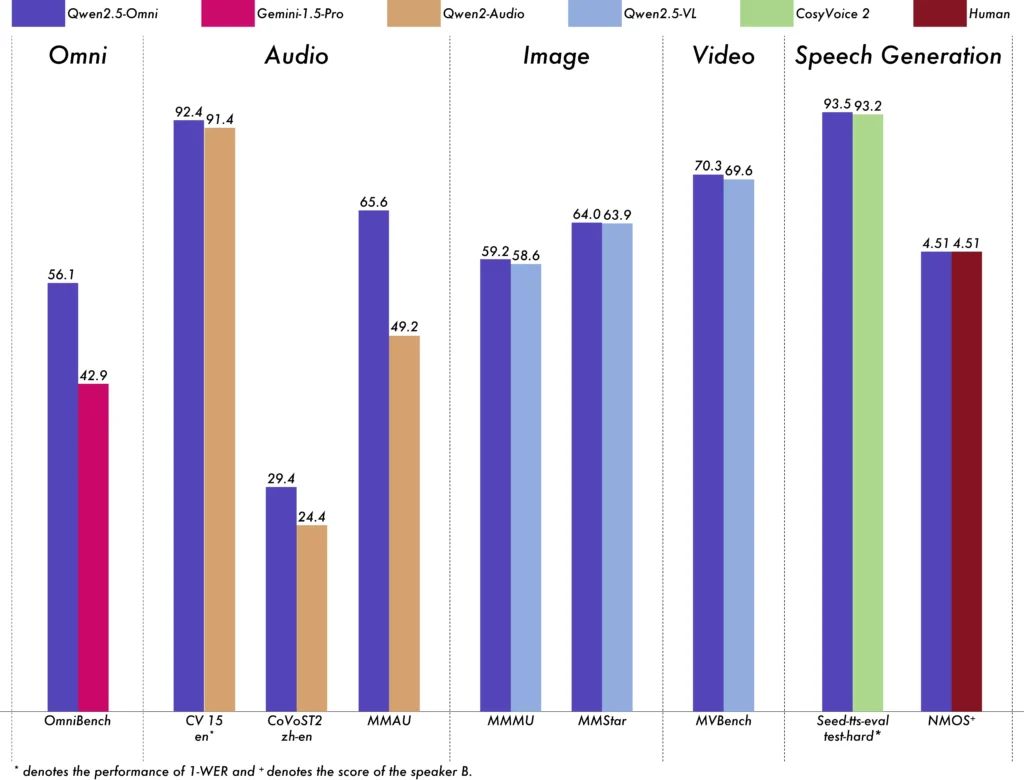
- オムニベンチ: 平均スコア 56.13% を達成し、Gemini-1.5-Pro (42.91%) や MIO-Instruct (33.80%) などのモデルを上回りました。
- 音声認識: Librispeech データセットでは、Whisper-large-v1.6 などの特殊なモデルに匹敵する 3.5% ~ 3% の単語エラー率を達成しました。
- サウンドイベント認識: Meld データセットで 0.570 のスコアを獲得し、この分野の新たなベンチマークを設定しました。
- 音楽理解: GiantSteps Tempo ベンチマークで 0.88 のスコアを達成し、音楽理解能力の高さを証明しました。
リアルタイム処理機能
リアルタイム アプリケーション向けに設計された Qwen2.5-Omni-7B は、ブロック単位のストリーミングをサポートし、最小限の遅延で即時のオーディオ生成を可能にします。この機能は、仮想アシスタントやインタラクティブ AI システムなど、迅速な応答を必要とするアプリケーションに特に役立ちます。
技術仕様
建築設計
- 考える人と話す人のフレームワーク: 「Thinker」コンポーネントは、マルチモーダル入力を処理および理解し、高レベルの意味表現とテキスト出力を生成します。「Talker」は、これらの表現を自然で流暢な音声に変換し、AI システムとユーザー間のシームレスなコミュニケーションを保証します。
- TMRoPEメカニズム: ビデオとオーディオの入力のタイムスタンプを揃えることで、さまざまなソースからの時間データを同期するという課題に対処し、一貫したマルチモーダル理解を促進します。
トレーニング方法論
モデルは 3 段階のトレーニング プロセスを経ました。
- フェーズ1: マルチモーダル理解を強化するために、広範なオーディオとテキスト、および画像とテキストのペアを使用してビジュアルおよびオーディオ エンコーダーをトレーニングする際の言語モデル パラメーターを修正しました。
- フェーズXNUMX: すべてのパラメータを解凍し、画像、ビデオ、オーディオ、テキストを含む多様なデータセットでトレーニングすることで、包括的なマルチモーダル理解をさらに向上させます。
- フェーズXNUMX: 複雑で拡張された入力を処理するモデルの能力を強化するために、長いシーケンス データのトレーニングに重点を置きました。
Qwenモデルの進化
Qwen から Qwen2.5 への進化
Qwen から Qwen2.5 への進化は、AI モデル開発における大きな飛躍を意味します。
- 強化されたパラメータ: Qwen2.5 は最大 72 億のパラメータを持つモデルに拡張され、多様なアプリケーションにスケーラブルなソリューションを提供します。
- 拡張コンテキスト処理: 最大 128,000 トークンを処理する機能を導入し、膨大な文書や複雑な会話の処理を容易にしました。
- コーディング機能: Qwen2.5-Coder バリアントは 92 を超えるプログラミング言語をサポートし、コード生成、デバッグ、および最適化タスクを支援します。
Qwen2.5-Omni-7Bの利点
包括的なマルチモーダル統合
Qwen2.5-Omni-7B は、テキスト、画像、オーディオ、ビデオを効果的に処理することで、幅広いアプリケーションに適した総合的な AI ソリューションを提供します。
リアルタイムの相互作用
低遅延処理により即時応答が保証され、インタラクティブ アプリケーションでのユーザー エクスペリエンスが向上します。
オープンソースのアクセシビリティ
Qwen2.5-Omni-7B はオープンソース モデルであるため、透明性が促進され、開発者は独自の制限なしにモデルをカスタマイズしてさまざまなプラットフォームに統合できます。
テクニカル指標
- モデルパラメータ: 7億
- 入力方法: テキスト、画像、音声、ビデオ
- 出力形式: テキスト、音声
- 処理能力: リアルタイムの音声とビデオのインタラクション
- パフォーマンスのベンチマーク:
- オムニベンチ: 平均スコア56.13%
- Librispeech(単語誤り率): 検査クリーン: 1.8%、検査その他: 3.4%
アプリケーションシナリオ
インタラクティブ仮想アシスタント
Qwen2.5-Omni-7B のリアルタイム処理とマルチモーダル理解は、自然に見て、聞いて、反応できる仮想アシスタントに最適です。
マルチメディアコンテンツの作成
コンテンツ作成者は、このモデルを活用して、テキスト、画像、オーディオをシームレスに組み合わせた魅力的なマルチメディア コンテンツを生成できます。
支援技術
このモデルの機能は、視覚的なコンテンツを説明する音声を提供するなど、障害を持つ人々を支援することができます。
使い方のヒント
パフォーマンスの最適化
特にリアルタイム アプリケーションで最適なパフォーマンスを実現するには、ハードウェア アクセラレータを活用し、十分な GPU メモリを確保することをお勧めします。
既存システムとの統合
開発者は、互換性を確保し、効率を最大化するために、既存のアプリケーションと統合する際にモデルの入力および出力形式を考慮する必要があります。
最新の状態に保つ
Qwen2.5-Omni-7B の機能を最大限に活用するには、公式リポジトリとドキュメントを定期的にチェックして、更新情報とベスト プラクティスを確認してください。
関連するトピック Qwen2.5-Omni-7Bモデルの実行方法
結論
Qwen2.5-Omni-7B は、高度な AI 研究と実用化の融合を体現したものであり、さまざまな業界のさまざまなタスクに対応する多用途で効率的なソリューションを提供します。オープンソースであるため、アクセス性と適応性を維持し、マルチモーダル AI の将来のイノベーションへの道を開きます。
CometAPI から Qwen2.5-Omni-7B API を呼び出す方法
1.ログイン 〜へ コムタピまだユーザーでない場合は、まず登録してください
2.アクセス認証情報APIキーを取得する インターフェースの。パーソナルセンターのAPIトークンで「トークンの追加」をクリックし、トークンキー:sk-xxxxxを取得して送信します。
-
このサイトの URL を取得します。 https://api.cometapi.com/
-
APIリクエストを送信するためにQwen2.5-Omni-7Bエンドポイントを選択し、リクエストボディを設定します。リクエストメソッドとリクエストボディは以下から取得されます。 当社のウェブサイトAPIドキュメント弊社のウェブサイトでは、お客様の便宜を図るため、Apifox テストも提供しています。
-
API レスポンスを処理して、生成された回答を取得します。API リクエストを送信すると、生成された補完を含む JSON オブジェクトが受信されます。