

GLM-5-Turbo는 Zhipu AI가 에이전트형 워크플로(회사에서는 대상 생태계를 OpenClaw / “lobster” 시나리오라고 부름)에 특화해 학습·튜닝한 새로운 기반 LLM이다. 매우 긴 컨텍스트(최대 ~200K 토큰), 스트리밍 및 구조화 출력, 더 낮은 도구 호출 오류율(서드파티 테스트 보고 ~0.67%), 그리고 실질적으로 더 낮은 토큰당 가격을 제공한다. 모델은 단일 턴의 최대 처리량 일부를 감수하는 대신 훨씬 더 나은 안정성, 도구 신뢰성, 스케줄링/지속 작업 처리, 장기 체인 실행을 목표로 하며, 이는 자율 에이전트, 오케스트레이션 시스템, 멀티툴 파이프라인에 유용하다.
GLM-5-Turbo란?
GLM-5-Turbo는 일반적인 챗/멀티모달 모델이 아니라, 에이전트 오케스트레이션과 복잡한 자동화 워크플로를 위해 설계된 기반 모델로 Zhipu가 소개한다. 설계 선택은 다음에 중점을 둔다.
- 네이티브 에이전트 친화적 학습(도구 사용, 커맨드 팔로잉, 타이머/지속 작업)
- 긴 세션, 메모리, 사고의 연쇄 계획을 지원하는 매우 큰 컨텍스트 윈도우와 출력 용량
- 장시간 비즈니스 플로와 예약 작업을 위한 안정적이고 고처리량의 추론
대화나 텍스트 생성에 최적화된 전통적 LLM과 달리, GLM-5-Turbo는 다음과 같다.
- 챗 우선이 아닌 에이전트 우선(Agent-first)
- OpenClaw(“lobster”) 환경을 위해 구축
- 다단계 자율 워크플로에 최적화
🦞 “Lobster Agent”란?
“lobster” 개념은 모델이 다음을 수행하는 Zhipu의 AI 에이전트 생태계인 OpenClaw를 가리킨다.
- 동적으로 도구 사용
- 긴 작업 체인 실행
- 지속적 메모리 유지
- 터미널, 앱, API 전반에서 작동
GLM-5-Turbo는 이 패러다임에 깊이 최적화되어 다음과 같은 핵심 에이전트 문제를 해결한다.
- 도구 호출 신뢰성
- 작업 분해
- 장기 계획
- 실행 안정성
핵심 기능과 의의
긴 컨텍스트 + 거대한 출력 용량(200K / 128K)
200K 토큰 컨텍스트 윈도우와 128K 출력 능력으로 GLM-5-Turbo는 다음을 가능하게 한다.
- 이전 컨텍스트(대화, 도구 출력, 중간 결과)에 대한 확장된 메모리 유지
- 컨텍스트를 반복 재결합하지 않고도 매우 긴 산출물(다단계 계획, 장문 보고서, 코드베이스) 생성
- 정확한 의사결정을 위해 전체 실행 이력을 유지해야 하는 멀티턴 에이전트 호스팅
이는 에이전트를 위한 의도적 기술 선택이다 — 작업을 짧은 프롬프트로 쪼개는 대신, 에이전트가 수천 턴/단계를 거쳐 일관된 상태를 유지할 수 있다.
에이전트 프리미티브를 학습 단계에서 내장
범용 모델을 에이전트 작업에 사후 적용하는 대신, GLM-5-Turbo는 에이전트형 목적(예: 도구 호출 동작, 명령/인자 파싱)으로 학습되었다. 그 효과로 주장되는 바는 도구 호출 중 환각 감소, 더 안정적인 다단계 계획, 장시간 실행에서의 지연 개선 등으로, 외부 API나 도구를 신뢰성 있게 연쇄 호출해야 하는 자동화 환경에서 가치가 크다.
처리량과 실행 안정성
GLM-5-Turbo 변형은 범용 대형 모델 대비 장시간 비즈니스 플로에서 실행 안정성과 처리량을 개선한다 — 마케팅 언어는 동급 대비 “고처리량 실행”과 “선도적 응답 안정성”을 강조한다. 이는 한 단계 실패가 전체 파이프라인을 깨뜨릴 수 있는 엔터프라이즈 에이전트 배포에서 의미가 크다. 독립 서드파티 벤치마크는 아직 진행 중이다.
GLM-5-Turbo의 벤치마크 데이터
참고: Zhipu는 내부 평가를 공개했으며, GLM-5에 대한 서드파티/학술 벤치마크가 존재한다. GLM-5-Turbo는 신규 출시 모델로, 커뮤니티의 독립 벤치마크는 시간이 필요하다. 아래는 가장 신뢰 가능한 공개 수치와 맥락이다.
GLM-5(참조) — 대표적 공개 지표
Zhipu의 GLM-5(터보의 전신 플래그십)는 많은 엔지니어링/워크플로 작업에서 강한 리더보드를 보고한다 — 예를 들어:
- SWE-bench Verified: 77.8(오픈 모델 선도 점수로 GLM-5 문서에 보고)
- Terminal Bench 2.0: 56.2(해당 분포에서 오픈 모델 최고 성능으로 보고)
이 수치는 소프트웨어 엔지니어링과 실행 작업에서 GLM-5가 높은 기준선임을 보여준다. GLM-5-Turbo는 원시 크기/파라미터 강조를 일부 희생하는 대신 에이전트 신뢰성과 처리량을 개선하도록 포지셔닝된다. GLM-5-Turbo는 비교 실행에서 도구 호출 오류가 약 ~0.67%로 나타났으며, 비교 대상 GLM-5 제공자 실행의 ~2.33%~6.41%보다 유의하게 낮았다.
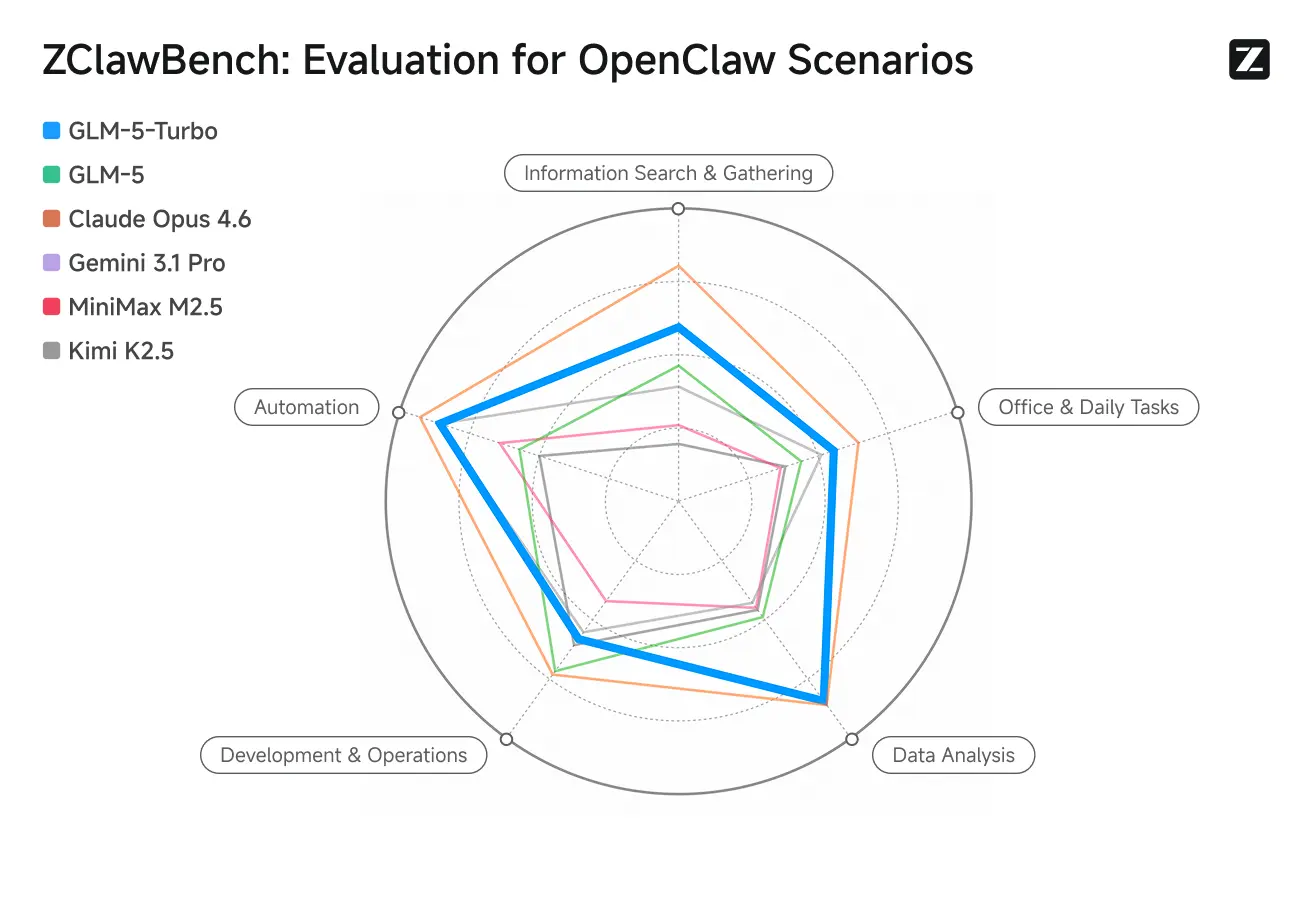
ZClawBench: OpenClaw 프록시 시나리오용 벤치마크 테스트
Zhipu는 지능형 에이전트를 평가하기 위한 ZClawBench도 공개했다. 코드 개발, 데이터 분석, 콘텐츠 제작 등 다양한 분야를 포괄하는 블라인드 테스트에서 Pony-Alpha-2라는 코드명의 신규 모델이 90% 응답자의 선호를 받았다.
가격 및 제공처(누가 판매하며 비용은 얼마인가)
Zhipu는 GLM-5-Turbo 출시와 함께 API 가격을 약 ~20% 인상하는 한편, 에이전트 배포의 토큰 가격을 평준화하기 위한 “Lobster Package” 구독 티어를 도입했다.
보고된 구독 티어(예시 패키지)
다음은 예시적 Lobster 패키지(가격은 환산치이며 대략적):
- Entry Lobster plan: ~39 CNY / month(~US$5.66), 35,000,000 tokens
- Mid Lobster plan: ~99 CNY / month(~US$14.36), 100,000,000 tokens
위 공개 수치를 기준으로 100만 토큰당 비용은 대략 다음과 같다.
- Entry plan: ~US$0.162 per 1M tokens
- Mid plan: ~US$0.144 per 1M tokens
이 100만 토큰당 수치는 공개된 구독 비용과 토큰 한도를 단순 환산한 것으로, 대량 에이전트 워크로드의 경제성을 보여준다(보도된 통화 및 토큰 수량 기반 계산).
API 가격
대표 마켓플레이스(CometAPI) 기준: GLM-5-Turbo의 입력 100만 토큰당 $0.96, 출력 100만 토큰당 $3.20.
Zhipu 자체(Z.ai) 개발자 가격 페이지에는 GLM-5-Turbo의 직접 요금이 소폭 더 높게 표기되어 있다: 입력 100만 토큰당 $1.20, 출력 100만 토큰당 $4.00(캐시된 입력 요금은 더 낮음).
GLM-5-Turbo vs GLM-5 — 나란히 비교
전반적 요약:
- GLM-5 = 플래그십 범용 기반 모델(추론, 코딩, 벤치마크 강점)
- GLM-5-Turbo = 에이전트 최적화 GLM-5 변형(긴 워크플로, 도구 사용, 안정성 중점)
GLM-5-Turbo는 완전히 새로운 모델 아키텍처가 아니라, OpenClaw 같은 에이전트 시스템을 위해 설계된 GLM-5의 특화·프로덕션 최적화 버전이다.
코어 포지셔닝
| Model | Positioning |
|---|---|
| GLM-5 | 범용 플래그십 LLM(추론, 코딩, 벤치마크) |
| GLM-5-Turbo | 에이전트 우선 모델(자동화, 오케스트레이션, 도구 사용) |
👉 한마디로:
- GLM-5 → 최대한의 지능이 필요할 때
- GLM-5-Turbo → 안정적인 자동화/에이전트가 필요할 때
에이전트 기능 비교(가장 중요)
GLM-5(에이전트 기능)는 이미 다음을 지원한다.
- 도구 사용
- 다단계 추론
- 코딩 에이전트
하지만 한계:
- 긴 체인에서 컨텍스트 손실 가능
- 시간이 지남에 따라 도구 호출 품질 저하 가능
- 더 많은 오케스트레이션 로직 요구
GLM-5-Turbo는 에이전트에 명시적으로 최적화됨:
핵심 개선:
- 도구 호출 신뢰성 ↑
- 작업 분해(플래닝) ↑
- 장기 체인 일관성 ↑
- 지속 실행 지원 ↑
개선 예:
- 컨텍스트 손실 없이 10+ 단계에 걸친 안정적 실행
👉 다음에 특히 중요:
- AutoGPT 스타일 시스템
- 멀티 에이전트 워크플로
- SaaS 자동화
속도 및 효율
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inference speed | 보통 | 더 빠름 |
| Throughput | 표준 | 더 높음 |
| Long-task latency | 저하 가능 | 최적화됨 |
GLM-5-Turbo는 실제 업계 문제를 해결하도록 설계되었다:
대형 모델은 긴 워크플로에서 느려지거나 중단된다
가격 비교
| Model | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo는 더 비싸다(~20% 인상)
왜 더 비싼가?
제공하는 가치:
- 더 나은 오케스트레이션 신뢰성
- 더 높은 프로덕션 안정성
- 에이전트 특화 최적화
👉 엔터프라이즈에서는:
- 토큰당 비용은 더 높지만
- 실패 비용과 재시도 비용을 줄인다
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primary goal | 범용 플래그십 기반 모델(광범위한 기능, 강력한 코딩/벤치마크) | 에이전트/“OpenClaw”/lobster 최적화 기반 모델 |
| Context window | (보고치 높음; GLM-5는 ~200K에 초점(GLM-5 또한 긴 컨텍스트 지원) | 200,000 tokens(문서에 명시). |
| Maximum output tokens | (대용량, 모델별 상이) | 128,000 tokens(문서화됨). |
| Notable benchmark scores | SWE-bench: 77.8; Terminal Bench 2.0: 56.2(GLM-5 보고 수치). | 내부 평가는 에이전트 워크플로에서 장기 체인 안정성과 처리량 개선을 주장; 공개 독립 벤치마크는 대기 중. |
| Modalities | 텍스트(주요), GLM 패밀리는 형제 모델에 비전 변형 존재 | 텍스트 전용(문서 기준) — 도구 기반 에이전트에 최적화 |
| Recommended use cases | 광범위: 챗, 코드, 추론, 콘텐츠 | 에이전트 오케스트레이션, 도구 호출, 장기 자동화 |
| Pricing | 기존 GLM-5 요금(플랜별 상이) | 신규 론치 — API 가격 약 ~20% 인상 보고; 신규 Lobster 구독 티어 도입 |
GLM-5-Turbo 사용 방법
CometAPI — 다수 모델에 대한 단일 API 액세스(OpenAI 호환)
CometAPI에는 GLM-5-Turbo가 등재되어 있으며 OpenAI 호환 베이스 URL과 SDK를 제공한다. 그들이 공개한 모델 문자열을 사용하라(사이트에는 GLM-5-Turbo가 유사한 가격으로 표기됨). 아래 예시는 CometAPI 문서를 기반으로 각색:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
CometAPI의 가치는 애그리게이터의 편의성(여러 모델에 대한 단일 통합)에 있다. 호출 전 CometAPI 대시보드에서 정확한 모델 슬러그를 확인하라.
GLM-5-Turbo로 Lobster / OpenClaw 에이전트를 구축할 때 모범 사례
- 속도보다 신뢰성을 우선 설계: Turbo의 강점은 긴 체인에서 낮은 도구 호출 실패율이다. 미미한 첫 토큰 지연보다 견고한 완료(재시도, 멱등적 도구 호출)를 선호하도록 에이전트 실행을 설계하라.
- 스트리밍 및 점진적 도구 호출 활용: 재작업을 줄이고 적절할 때 조기 도구 호출을 가능케 하기 위해 스트리밍/청크 출력을 수용하라. GLM-5-Turbo는 스트리밍을 지원한다.
- 파서를 위한 구조화 출력: 하위 도구의 결정적 파싱을 위해 JSON 또는 잘 정형화된 결과를 선호하라. Turbo는 구조화 출력을 지원한다.
- 스케줄링/지속성 계획: 에이전트가 주기적으로 확인하거나 백그라운드 작업을 수행해야 한다면, 매 사이클마다 재계획하지 않도록 Turbo의 더 나은 시간 의미론과 캐싱 기능을 활용하라.
- 도구 호출 계측 및 폴백: 도구 호출을 로깅하고 우아한 폴백(예: 미세한 temperature로 재시도 또는 백업 도구 호출)을 설계하라. 에이전트형 워크플로는 외부 API가 한 번만 실패해도 취약하다. Turbo는 오류율을 낮추지만 외부 실패를 제거하진 못한다.
개발자는 지금 CometAPI를 통해 GLM-5와 GLM-5 turbo API에 접속할 수 있다. 시작하려면 자세한 지침을 위해 API guide를 참고하라. 접속 전에 CometAPI에 로그인하고 API 키를 발급받았는지 확인하라. CometAPI는 공식 가격보다 훨씬 낮은 가격을 제공해 통합을 돕는다.
Ready to Go?→ Sign up for GLM-5 and GLM-5 turbo today !