

Dalam landskap kecerdasan buatan yang berkembang pesat, 2025 telah menyaksikan kemajuan ketara dalam model bahasa besar (LLM). Antara yang mendahului ialah Qwen2.5 Alibaba, model V3 dan R1 DeepSeek, dan ChatGPT OpenAI. Setiap model ini membawa keupayaan unik dan inovasi ke meja. Artikel ini menyelidiki perkembangan terkini sekitar Qwen2.5, membandingkan ciri dan prestasinya dengan DeepSeek dan ChatGPT untuk menentukan model mana yang sedang mengetuai perlumbaan AI.
Apakah Qwen2.5?
Pengenalan
Qwen 2.5 ialah model bahasa besar padat, penyahkod sahaja terbaharu Alibaba Cloud, tersedia dalam pelbagai saiz antara parameter 0.5B hingga 72B. Ia dioptimumkan untuk mengikut arahan, output berstruktur (cth, JSON, jadual), pengekodan dan penyelesaian masalah matematik. Dengan sokongan untuk lebih 29 bahasa dan panjang konteks sehingga 128K token, Qwen2.5 direka bentuk untuk aplikasi berbilang bahasa dan khusus domain.
Ciri-ciri utama
- Sokongan berbilang bahasa: Menyokong lebih 29 bahasa, memenuhi keperluan asas pengguna global.
- Panjang Konteks Lanjutan: Mengendalikan sehingga 128K token, membolehkan pemprosesan dokumen panjang dan perbualan.
- Varian Khusus: Termasuk model seperti Qwen2.5-Coder untuk tugas pengaturcaraan dan Qwen2.5-Math untuk penyelesaian masalah matematik.
- Capaian: Tersedia melalui platform seperti Hugging Face, GitHub dan antara muka web yang baru dilancarkan di chat.qwenlm.ai.
Bagaimana untuk menggunakan Qwen 2.5 secara tempatan?
Di bawah ialah panduan langkah demi langkah untuk 7 B Sembang pusat pemeriksaan; saiz yang lebih besar berbeza hanya dalam keperluan GPU.
1. Prasyarat perkakasan
| model | vRAM untuk 8-bit | vRAM untuk 4-bit (QLoRA) | Saiz cakera |
|---|---|---|---|
| Qwen 2.5‑7B | 14GB | 10GB | 13GB |
| Qwen 2.5‑14B | 26GB | 18GB | 25GB |
Satu RTX 4090 (24 GB) cukup untuk 7 B inferens pada ketepatan 16-bit penuh; dua kad sedemikian atau CPU off-load ditambah kuantiti boleh mengendalikan 14 B.
2. pemasangan
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Skrip inferens pantas
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
. trust_remote_code=True bendera diperlukan kerana Qwen menghantar adat Pembenaman Kedudukan Putar pembalut.
4. Penalaan halus dengan LoRA
Terima kasih kepada penyesuai LoRA yang cekap parameter, anda boleh melatih Qwen secara khusus pada ~50 K pasangan domain (katakan, perubatan) dalam masa kurang dari empat jam pada satu GPU 24 GB:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Fail penyesuai yang terhasil (~120 MB) boleh digabungkan kembali atau dimuatkan atas permintaan.
Pilihan: Jalankan Qwen 2.5 sebagai API
CometAPI bertindak sebagai hab berpusat untuk API beberapa model AI terkemuka, menghapuskan keperluan untuk terlibat dengan berbilang penyedia API secara berasingan. CometAPI menawarkan harga yang jauh lebih rendah daripada harga rasmi untuk membantu anda menyepadukan Qwen API , dan anda akan mendapat $1 dalam akaun anda selepas mendaftar dan log masuk! Selamat datang untuk mendaftar dan mengalami CometAPI.Untuk pembangun yang bertujuan untuk memasukkan Qwen 2.5 ke dalam aplikasi:
Langkah 1: Pasang perpustakaan yang diperlukan:
bash
pip install requests
Langkah 2: dapatkan Kunci API
- Navigasi ke CometAPI.
- Log masuk dengan akaun CometAPI anda.
- Pilih Papan Pemuka.
- Klik pada "Dapatkan Kunci API" dan ikut gesaan untuk menjana kunci anda.
Langkah 3: Laksanakan Panggilan API
Gunakan bukti kelayakan API untuk membuat permintaan kepada Qwen 2.5.Ganti dengan kunci CometAPI sebenar anda daripada akaun anda.
Sebagai contoh, dalam Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Penyepaduan ini membolehkan penggabungan lancar keupayaan Qwen 2.5 ke dalam pelbagai aplikasi, meningkatkan fungsi dan pengalaman pengguna. Pilih “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” titik akhir untuk menghantar permintaan API dan menetapkan badan permintaan. Kaedah permintaan dan badan permintaan diperoleh daripada dokumen API tapak web kami. Laman web kami juga menyediakan ujian Apifox untuk kemudahan anda.
Sila rujuk kepada API Maks Qwen 2.5 untuk butiran penyepaduan.CometAPI telah mengemas kini yang terkini API QwQ-32B.Untuk lebih banyak maklumat Model dalam Comet API sila lihat Dokumen API.
Amalan dan petua terbaik
| senario | Cadangan |
|---|---|
| Soal Jawab dokumen panjang | Potong petikan ke dalam token ≤16 K dan gunakan gesaan ditambah perolehan dan bukannya konteks 100 K naif untuk mengurangkan kependaman. |
| Keluaran berstruktur | Awalan mesej sistem dengan: You are an AI that strictly outputs JSON. Latihan penjajaran Qwen 2.5 cemerlang pada penjanaan terhalang. |
| Penyelesaian kod | Tetapkan temperature=0.0 and top_p=1.0 untuk memaksimumkan determinisme, kemudian sampel berbilang rasuk (num_return_sequences=4) untuk kedudukan. |
| Penapisan keselamatan | Gunakan himpunan regex “Qwen‑Guardrails” sumber terbuka Alibaba atau teks‑moderation‑004 OpenAI sebagai pas pertama. |
Batasan yang diketahui bagi Qwen 2.5
- Kecenderungan suntikan segera. Audit luaran menunjukkan kadar kejayaan jailbreak sebanyak 18 % pada Qwen 2.5‑VL—peringatan bahawa saiz model semata-mata tidak memberi imunisasi terhadap arahan lawan.
- Bunyi OCR bukan Latin. Apabila diperhalusi untuk tugasan bahasa penglihatan, saluran paip hujung-ke-hujung model kadangkala mengelirukan glif Cina tradisional lwn mudah, yang memerlukan lapisan pembetulan khusus domain.
- Tebing memori GPU pada 128 K. FlashAttention‑2 mengimbangi RAM, tetapi hantaran hadapan padat 72 B merentasi token 128 K masih memerlukan >120 GB vRAM; pengamal harus window‑attend atau KV‑cache.
Pelan hala tuju & ekosistem komuniti
Pasukan Qwen telah membayangkan Qwen 3.0, menyasarkan tulang belakang penghalaan hibrid (Dense + MoE) dan pralatihan teks penglihatan-pertuturan bersatu. Sementara itu, ekosistem sudah menjadi tuan rumah:
- Q‑Agen – ejen rantaian pemikiran gaya ReAct menggunakan Qwen 2.5‑14B sebagai polisi.
- Alpaca Kewangan Cina – LoRA pada Qwen2.5‑7B dilatih dengan pemfailan peraturan 1 M.
- Buka pemalam Jurubahasa – menukar GPT‑4 untuk pusat pemeriksaan Qwen tempatan dalam Kod VS.
Semak halaman "Koleksi Qwen2.5" Muka Memeluk untuk mendapatkan senarai pusat pemeriksaan, penyesuai dan abah-abah penilaian yang dikemas kini secara berterusan.
Analisis Perbandingan: Qwen2.5 lwn DeepSeek dan ChatGPT
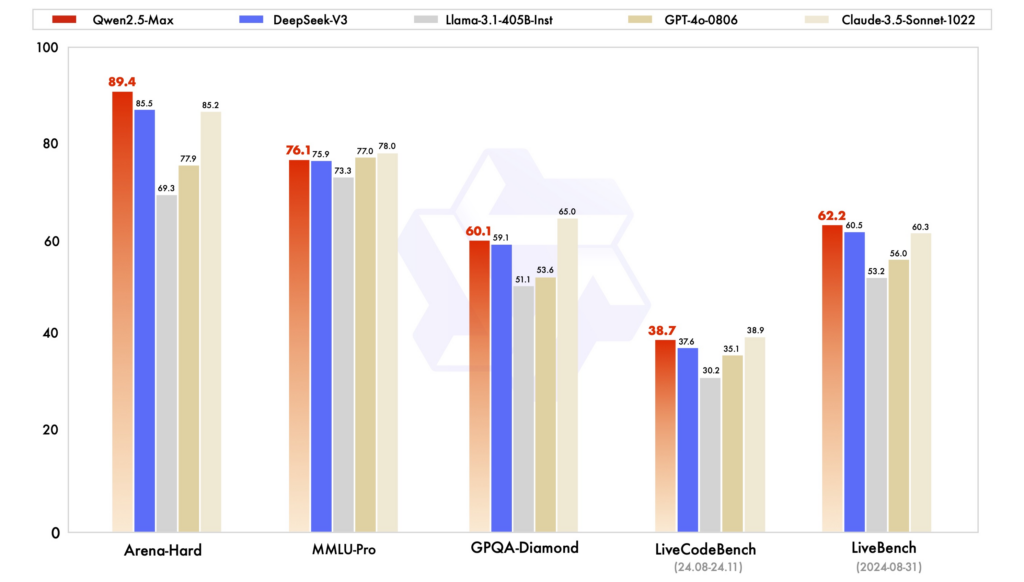
Penanda Aras Prestasi: Dalam pelbagai penilaian, Qwen2.5 telah menunjukkan prestasi yang kukuh dalam tugasan yang memerlukan penaakulan, pengekodan dan pemahaman berbilang bahasa. DeepSeek-V3, dengan seni bina MoEnya, cemerlang dalam kecekapan dan skalabiliti, memberikan prestasi tinggi dengan sumber pengiraan yang dikurangkan. ChatGPT kekal sebagai model yang teguh, terutamanya dalam tugas bahasa tujuan umum.
Kecekapan dan Kos: Model DeepSeek terkenal dengan latihan dan inferens yang kos efektif, memanfaatkan seni bina MoE untuk mengaktifkan hanya parameter yang diperlukan bagi setiap token. Qwen2.5, walaupun padat, menawarkan varian khusus untuk mengoptimumkan prestasi untuk tugas tertentu. Latihan ChatGPT melibatkan sumber pengiraan yang banyak, mencerminkan kos operasinya.
Kebolehcapaian dan Ketersediaan Sumber Terbuka: Qwen2.5 dan DeepSeek telah menerima prinsip sumber terbuka pada tahap yang berbeza-beza, dengan model tersedia pada platform seperti GitHub dan Hugging Face. Pelancaran antara muka web Qwen2.5 baru-baru ini meningkatkan kebolehcapaiannya. ChatGPT, walaupun bukan sumber terbuka, boleh diakses secara meluas melalui platform dan integrasi OpenAI.
Kesimpulan
Qwen 2.5 terletak di tempat yang menarik antara perkhidmatan premium tertutup and model hobi terbuka sepenuhnya. Gabungan pelesenan permisif, kekuatan berbilang bahasa, kecekapan konteks panjang dan pelbagai skala parameter menjadikannya asas yang menarik untuk penyelidikan dan pengeluaran.
Semasa landskap LLM sumber terbuka perlumbaan ke hadapan, projek Qwen menunjukkannya ketelusan dan prestasi boleh wujud bersama. Bagi pembangun, saintis data dan pembuat dasar, menguasai Qwen 2.5 hari ini adalah pelaburan dalam masa depan AI yang lebih pluralistik dan mesra inovasi.