

GLM-5-Turbo is een nieuw foundation-LLM van Zhipu AI, speciaal getraind en afgestemd voor agentgerichte werkstromen (het bedrijf noemt het doelecosysteem OpenClaw / “lobster”-scenario’s). Het biedt een zeer lange context (tot ~200K tokens), streaming- en gestructureerde outputs, lagere foutpercentages bij tool-aanroepen (gerapporteerd ~0,67% in tests door derden) en materieel lagere prijs per token. Het model ruilt een kleine hoeveelheid piekdoorvoer per enkele beurt in voor veel betere stabiliteit, toolbetrouwbaarheid, afhandeling van geplande/persistente taken en uitvoering van lange ketens — nuttig voor autonome agents, orkestratiesystemen en pipelines met meerdere tools.
Wat is GLM-5-Turbo?
GLM-5-Turbo wordt door Zhipu gepresenteerd als een foundationmodel dat doelgericht is gebouwd voor agent-orkestratie en complexe geautomatiseerde werkstromen, en niet als een algemeen chat- of multimodaal model. De ontwerpkeuzes leggen nadruk op:
- Native agentvriendelijke training (toolgebruik, het opvolgen van commando’s, getimede/persistente taken).
- Zeer grote contextvensters en uitvoercapaciteit om lange sessies, geheugen en keten-van-denken-planning te ondersteunen.
- Stabiele, high-throughput inferentie voor lange bedrijfsflows en geplande taken.
In tegenstelling tot traditionele LLM’s die zijn geoptimaliseerd voor chat of tekstopwekking, is GLM-5-Turbo:
- Agent-first (niet chat-first)
- Gebouwd voor OpenClaw (“lobster”)-omgevingen
- Ontworpen voor multistap autonome werkstromen
🦞 Wat betekent “Lobster Agent”?
Het “lobster”-concept verwijst naar OpenClaw, Zhipu’s AI-agentecosysteem waarin modellen:
- Dynamisch tools gebruiken
- Lange ketens van taken uitvoeren
- Persistente geheugenfuncties behouden
- Opereren over terminals, apps en API’s
GLM-5-Turbo is hier diep voor geoptimaliseerd en lost sleutelproblemen voor agents op, zoals:
- Betrouwbaarheid van tool-aanroepen
- Taakdecompositie
- Langetermijnplanning
- Uitvoeringsstabiliteit
Belangrijkste functies en waarom ze ertoe doen
Lange context + enorme uitvoercapaciteit (200K / 128K)
Een contextvenster van 200K tokens en 128K uitvoercapaciteit stellen GLM-5-Turbo in staat om:
- Uitgebreid geheugen van eerdere context te behouden (gesprekken, tool-outputs, tussenresultaten).
- Zeer lange gegenereerde artefacten te produceren (meerfasige plannen, lange rapporten, codebases) zonder herhaaldelijk context “stitchen”.
- Meerslagagents te hosten die de volledige uitvoeringsgeschiedenis moeten behouden voor nauwkeurige besluitvorming.
Dit is een bewuste technische keuze voor agents — in plaats van taken op te knippen in korte prompts, kunnen agents een coherente status aanhouden over duizenden gespreksrondes of stappen.
Agent-primitieven ingebakken in de training
In plaats van een generiek model achteraf aan te passen voor agenttaken, is GLM-5-Turbo getraind met agentachtige doelstellingen (bijv. toolaanroepgedrag, parse van commando’s/argumenten). Het beoogde effect is minder hallucinaties tijdens tool-aanroepen, stabielere multistapplannen en verbeterde latentie bij lange runs — allemaal waardevol wanneer automatisering betrouwbaar veel externe API’s of tools moet aaneenschakelen.
Doorvoer en uitvoeringsstabiliteit
De GLM-5-Turbo-variant verbetert de uitvoeringsstabiliteit en doorvoer voor lange bedrijfsflows vergeleken met gegeneraliseerde grote modellen — de marketingtaal benadrukt “hoge doorvoeruitvoering” en “toonaangevende responsstabiliteit” onder vergelijkbare modellen. Dit is betekenisvol voor enterprise agent-deployments waarbij een mislukte stap een hele pipeline kan breken. Onafhankelijke benchmarks door de community zijn nog in opkomst.
Benchmarkgegevens van GLM-5-Turbo
Opmerking: Zhipu heeft interne evaluaties gepubliceerd, en er zijn third-party/academische benchmarks voor GLM-5 beschikbaar. GLM-5-Turbo is nieuw uitgebracht; onafhankelijke community-benchmarks zullen mettertijd verschijnen. Hieronder vermelden we de meest verdedigbare, gepubliceerde cijfers en context.
GLM-5 (referentie) — representatieve gepubliceerde metrics
Zhipu’s GLM-5 (de vlaggenschipvoorganger van Turbo) rapporteert sterke resultaten op veel engineering-/workflowtaken — bijvoorbeeld:
- SWE-bench Verified: 77,8 (gerapporteerd in GLM-5-documentatie als een leidende open-modelscore).
- Terminal Bench 2.0: 56,2 (gerapporteerd als top open-modelprestatie op de gegeven distributie).
Die cijfers vestigen GLM-5 als een hoge baseline in software-engineering en uitvoeringstaken; GLM-5-Turbo is gepositioneerd om wat ruwe grootte/parameterfocus in te ruilen voor betere agentbetrouwbaarheid en doorvoer. GLM-5-Turbo toonde ~0,67% toolingaanroepfouten in hun vergelijkingsruns, materieel lager dan vergelijkbare GLM-5-providers die varieerden van ~2,33% tot 6,41%.
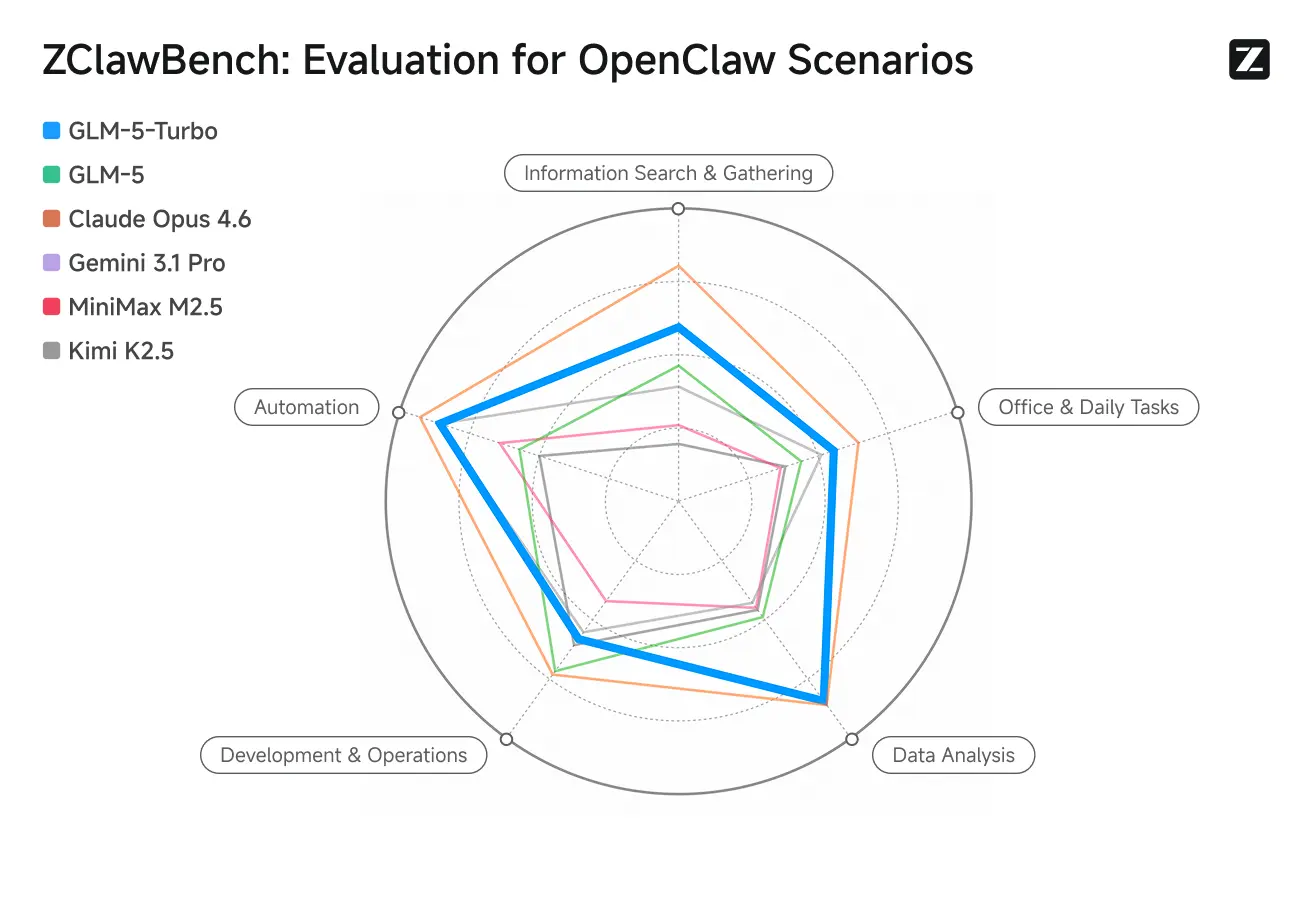
ZClawBench: Benchmarktest voor OpenClaw-proxyscenario’s
Zhipu publiceerde ook de ZClawBench-benchmark voor het evalueren van intelligente agents. In blinde tests die diverse domeinen bestrijken, zoals codeontwikkeling, data-analyse en contentcreatie, kreeg het nieuwe model met codenaam Pony-Alpha-2 de voorkeur van 90% van de respondenten.
Prijzen & beschikbaarheid (wie verkoopt het en wat kost het)
Zhipu voerde een ~20% API-prijsverhoging door voor de GLM-5-Turbo-aanbieding bij lancering en introduceerde tegelijkertijd “Lobster Package”-abonnementstiers om tokenprijzen voor agent-deployments te egaliseren.
Gerapporteerde abonnementsniveaus (voorbeeldpakketten)
Twee illustratieve Lobster-pakketten (prijzen zijn omgerekend en bij benadering):
- Entry Lobster-plan: ~39 CNY / maand (~US$5,66) voor 35.000.000 tokens.
- Mid Lobster-plan: ~99 CNY / maand (~US$14,36) voor 100.000.000 tokens.
Op basis van deze gepubliceerde aantallen is de kosten per 1 miljoen tokens ongeveer:
- Entry-plan: ~US$0,162 per 1M tokens.
- Mid-plan: ~US$0,144 per 1M tokens.
Die per-1M cijfers zijn simpele conversies van de gepubliceerde abonnementsprijs en tokencap en illustreren de economie voor agentworkloads met hoog volume. (Berekeningen gebaseerd op de in de pers gerapporteerde valuta en tokenhoeveelheden.)
API-prijs
Representatieve marktplaats (CometAPI) vermelding: $0,96 per 1M inputtokens en $3,20 per 1M outputtokens voor GLM-5-Turbo.
Zhipu’s eigen (Z.ai) ontwikkelaarsprijspagina vermeldt een iets hoger direct tarief voor GLM-5-Turbo: $1,20 per 1M inputtokens en $4,00 per 1M outputtokens (gecachete inputtarieven zijn lager).
GLM-5-Turbo vs GLM-5 — vergelijking naast elkaar
Op hoofdlijnen:
- GLM-5 = vlaggenschip foundationmodel voor algemeen gebruik (sterk in redeneren, coderen, benchmarks)
- GLM-5-Turbo = agent-geoptimaliseerde variant van GLM-5 (gericht op lange werkstromen, toolgebruik, stabiliteit)
GLM-5-Turbo is geen volledig nieuwe modelarchitectuur, maar een gespecialiseerde, productie-geoptimaliseerde versie van GLM-5 die is ontworpen voor agentsystemen zoals OpenClaw.
Kernpositionering
| Model | Positionering |
|---|---|
| GLM-5 | Foundation-LLM voor algemeen gebruik (redeneren, coderen, benchmarks) |
| GLM-5-Turbo | Agent-first model (automatisering, orkestratie, toolgebruik) |
👉 Simpel gezegd:
- Gebruik GLM-5 → wanneer je maximale intelligentie wilt
- Gebruik GLM-5-Turbo → wanneer je stabiele automatisering/agents wilt
Agentcapaciteiten vergelijking (MEEST BELANGRIJK)
GLM-5 (agentcapaciteit) ondersteunt al:
- Toolgebruik
- Multistapredeneren
- Code-agents
Maar beperkingen:
- Kan context verliezen in lange ketens
- Tool-aanroepen kunnen na verloop van tijd degraderen
- Vereist meer orkestratielogica
GLM-5-Turbo is expliciet geoptimaliseerd voor agents:
Belangrijkste verbeteringen:
- Betrouwbaarheid van tool-aanroepen ↑
- Taakdecompositie (planning) ↑
- Consistentie over lange ketens ↑
- Ondersteuning voor persistente uitvoering ↑
Voorbeeldverbetering:
- Stabiele uitvoering over 10+ stappen zonder contextverlies
👉 Dit is cruciaal voor:
- Systemen in AutoGPT-stijl
- Werkstromen met meerdere agents
- SaaS-automatisering
Snelheid & efficiëntie
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inferentiesnelheid | Gemiddeld | Sneller |
| Doorvoer | Standaard | Hoger |
| Latentie bij lange taken | Kan degraderen | Geoptimaliseerd |
GLM-5-Turbo is ontworpen om een echt industrieprobleem op te lossen:
Grote modellen vertragen of breken tijdens lange werkstromen
Prijsvergelijking
| Model | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1,00 | ~$3,20 |
| GLM-5-Turbo | ~$1,20 | ~$4,00 |
👉 GLM-5-Turbo is duurder (~20% hoger)
Waarom duurder?
Omdat het biedt:
- Betere orkestratiebetrouwbaarheid
- Hogere productiestabiliteit
- Agent-specifieke optimalisaties
👉 In enterprise:
- Je betaalt meer per token
- Maar verlaagt faalkosten + retries
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primair doel | Vlaggenschip foundationmodel (brede capaciteiten, sterk in coderen/benchmarks) | Agent-/“OpenClaw”-/lobster-geoptimaliseerd foundationmodel |
| Contextvenster | (hoog gerapporteerd; GLM-5 richt zich op ~200K (GLM-5 ondersteunt ook lange context) | 200.000 tokens (expliciet gedocumenteerd). |
| Maximale outputtokens | (groot, modelafhankelijk) | 128.000 tokens (gedocumenteerd). |
| Opvallende benchmarkcijfers | SWE-bench: 77,8; Terminal Bench 2.0: 56,2 (gerapporteerde GLM-5-nummers). | Interne evaluaties claimen verbeterde langeketenstabiliteit en doorvoer voor agentwerkstromen; onafhankelijke publieke benchmarks in afwachting. |
| Modaliteiten | Tekst (primair), GLM-familie heeft visuele varianten in zuster modellen | Alleen tekst (volgens docs) — geoptimaliseerd voor tool-gebaseerde agents. |
| Aanbevolen use-cases | Breed: chat, code, redeneren, content | Agent-orkestratie, tool-aanroepen, langetermijnautomatisering |
| Prijzen | Bestaande GLM-5-prijzen (variëren per plan) | Nieuwe lancering — gerapporteerde ~20% API-prijsverhoging; nieuwe Lobster-abonnementsniveaus geïntroduceerd |
Hoe gebruik je GLM-5-Turbo
CometAPI — één API-toegang tot veel modellen (OpenAI-compatibel)
CometAPI vermeldt GLM-5-Turbo als beschikbaar en biedt een OpenAI-compatibele basis-URL en SDK. Gebruik de modelstring die zij publiceren (hun site vermeldt GLM-5-Turbo met vergelijkbare prijzen). Voorbeelden aangepast uit de CometAPI-documentatie:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
De waarde van CometAPI is aggregator-gemak (één integratie voor veel modellen). Bevestig de exacte model-slug in het CometAPI-dashboard voordat je aanroept.
Best practices bij het bouwen van Lobster-/OpenClaw-agents met GLM-5-Turbo
- Ontwerp voor betrouwbaarheid, niet ruwe latentie: het voordeel van Turbo is een lager faalpercentage van tool-aanroepen in lange ketens. Structureer agentruns om robuuste completions (retries, idempotente tool-aanroepen) te prefereren boven minieme first-token-winsten.
- Gebruik streaming & incrementele tool-aanroepen: omarm streaming/gechunkte outputs om herwerk te verminderen en vroege toolaanroep mogelijk te maken waar passend. GLM-5-Turbo ondersteunt streaming.
- Gestructureerde outputs voor parsers: geef de voorkeur aan JSON of goed geformatteerde resultaten voor deterministische downstream tool-parsing. Turbo ondersteunt gestructureerde outputs.
- Plan voor scheduling/persistentie: als je agent periodiek moet controleren of achtergrondtaken moet draaien, gebruik de betere tijdsemantiek en cachingfuncties van Turbo om te voorkomen dat je elke cyclus opnieuw moet plannen.
- Instrumenteer tool-aanroepen & fallbacks: log tool-aanroepen en ontwerp gracieuze fallbacks (bijv. opnieuw proberen met iets andere temperature of een back-uptool aanroepen), aangezien agentische werkstromen fragiel zijn als een enkele externe API faalt. Turbo verlaagt foutpercentages maar elimineert externe storingen niet.
Developers kunnen nu via CometAPI toegang krijgen tot de GLM-5- en GLM-5-Turbo-API. Raadpleeg om te beginnen de API-gids voor gedetailleerde instructies. Zorg ervoor dat je bent ingelogd op CometAPI en een API-sleutel hebt verkregen voordat je toegang aanvraagt. CometAPI biedt een prijs die aanzienlijk lager is dan de officiële prijs om je integratie te helpen.
Ready to Go?→ Meld je vandaag aan voor GLM-5 en GLM-5-Turbo !