

xAI stilletjes uitgebracht Grok 4.1 (17–18 november 2025) — een gerichte upgrade naar Grok 4 die prioriteit geeft emotionele intelligentie, creatieve expressie en verminderde hallucinatie Met behoud van de messcherpe redenering van eerdere Grok-releases. Het verschijnt in twee modi (Denken/Niet-Denken), werd begin november in stilte uitgerold, toont topscores op LMArena en is beschikbaar via grok.com, de Grok-apps en de API.
Wat is Grok 4.1?
Grok 4.1 is de incrementele, productiegerichte opvolger van Grok 4: een familielid gebouwd op dezelfde grootschalige reinforcement learning-basis, maar verfijnd en opnieuw getraind met uitgebreide post-training optimalisaties gericht op stijl, persoonlijkheid, afstemming en betrouwbaarheid in de praktijk. Het wordt gepositioneerd als een pragmatische, "bruikbare" stap voorwaarts: slimmer in blinde menselijke voorkeurstests, emotioneel intelligenter, beter in creatief schrijven en meetbaar minder vatbaar voor het soort zelfverzekerde-maar-onjuiste "hallucinaties" die eerdere, goed presterende LLM's hebben geplaagd.
Grok 4.1 realiseert kwalitatieve veranderingen in de volgende vier dimensies:
- Creativiteit: toont een sterke taalstijl en verbeeldingskracht bij het schrijven, vertellen van verhalen en in sociale contexten;
- Emotionele intelligentie: Herkent veranderingen in toon en emoties, reageert met een meer menselijke emotionele logica en genereert geruststellende en begripvolle reacties;
- Persoonlijkheidscoherentie: behoudt een consistente toon en persoonlijkheid in lange gesprekken, en vertoont niet langer het inconsistente gedrag van eerdere modellen;
- Samenwerkend: Behoudt de samenhang en het doelbewustzijn in dialogen met meerdere beurten of bij samenwerking aan taken.
xAI vat de kenmerken ervan samen in één zin: "Het is opmerkzamer, empathischer en meer een coherent persoon."
Hoe werkt Grok 4.1 onder de motorkap?
Grok 4.1 kan het beste worden begrepen als dezelfde vooraf getrainde backbone die wordt gebruikt in de hele Grok 4-familie, plus een gelaagde post-trainingspijplijn die zich richt op beloningsmodellering, stijlafstemming en agent-evaluatoren.
Wat zijn de trainings- en uitlijningsfasen?
Grok 4.1 werkt met een meerfasenpijplijn die typisch is voor moderne grens-LLM's, aangepast met twee belangrijke wijzigingen voor 4.1:
- Pre-training + mid-training: Grote corpus-pre-training over webdata + gerichte tussentijdse training om de domeinkennis en multimodale mogelijkheden te vergroten.
- Begeleide fine-tuning (SFT): Menselijke demonstraties van gewenst gedrag (reacties, weigeringsstrategieën).
- Beloningsmodellering (nieuwe toepassing): xAI trainde beloningsmodellen niet alleen op menselijke voorkeurslabels, maar gebruikte ook grensagentische redeneringsmodellen als beloningsbeoordelaars – waardoor zeer capabele, modelgebaseerde evaluatoren de output van kandidaten op grote schaal konden beoordelen. Dit maakte optimalisatie van niet-verifieerbare kenmerken mogelijk, zoals stijl, persoonlijkheidscohesie, empathie en behulpzaamheid zonder dat er een onmogelijk groot budget voor menselijk etiketteren nodig is.
- Beleidsoptimalisatie (RLHF / RL van modelbeloningen): Standaardbeleidsoptimalisatie waarbij de geleerde beloningssignalen worden gebruikt om het geïmplementeerde beleid te produceren (het model waarmee consumenten interacteren).
Wat is er nieuw in de beloningsmodelleringsaanpak?
Bij traditionele RLHF verzamel je menselijke voorkeurslabels (A/B), train je een beloningsmodel om die labels te voorspellen en optimaliseer je vervolgens het basismodel met RL (of afwijzingssteekproef) op basis van die geleerde beloning. Maar twee praktische innovaties die xAI benadrukt:
- Agentische beloningsmodellen: In plaats van puur menselijke beoordelaars, gebruikte xAI capabele "agentische" redeneermodellen als beoordelaars om subtielere eigenschappen (toon, emotionele nuance, creativiteit) te beoordelen. De beoordelaars kunnen snel duizenden paarsgewijze vergelijkingen uitvoeren, waardoor ingenieurs sneller kunnen itereren. Dit is het mechanisme voor aanzienlijke verbeteringen in stijl en emotionele intelligentie.
- Uitlijning na de training voor niet-verifieerbare signalen: voor eigenschappen die je niet met een deterministische metriek kunt meten (bijvoorbeeld 'warmte' of 'coherente persoonlijkheid') introduceerden ze gespecialiseerde beloningsdoelstellingen en schaalbare curricula, zodat het model de stijl van uitkomsten zonder dat dit ten koste gaat van de feitelijke nauwkeurigheid.
Hoe werkt ‘denken’ versus ‘niet-denken’ technisch gezien?
- Grok 4.1 Denken (codenaam
quasarflux) — legt expliciete redeneerstappen (denktokens) bloot voordat het definitieve antwoord wordt geproduceerd; geoptimaliseerd voor complexe taken en hogere Elo in LMArena. De extra tokens kosten inferentietijd, maar helpen bij meerstaps redeneertaken, debuggen en uitlegbaarheid. - Grok 4.1 Niet-denken (codenaam
tensor) omzeilt expliciete tussenliggende tokens en geeft recht op één onmiddellijke, definitieve respons. Dit vermindert de latentie en tokenkosten, terwijl de voordelen van dezelfde verfijnde beleidsgewichten behouden blijven. De niet-denkende modus is geoptimaliseerd voor een extreem lage latentie en toch zeer capabel.
Optimalisatie van de uitlijning van sentiment en stijl
Naast simpele signalen van "waarachtigheid", omvat Grok 4.1 gerichte optimalisatie van de afstemming op sentiment, toon en interpersoonlijke stijl. Dit betekent dat de trainingspijplijn belonings- of verliescomponenten bevat die expliciet een afwijkende toon afstraffen (bijvoorbeeld onnodig kortaf zijn wanneer empathie gepast is) en reacties belonen die passen bij een gewenst stijl- of sentimentprofiel. In Grok 4.1 introduceerde AI voor het eerst de optimalisatiedoelstelling "Persoonlijkheidsafstemming".
Het doel is om het model te helpen een consistent en stabiel identiteitsgevoel te behouden. Vergeleken met Grok 4 voegt 4.1 het volgende toe aan de trainingsdoelen:
- Positieve beloningen voor de dimensie van emotionele expressie (beloning voor emotionele uitlijning);
- Een persoonlijkheidscoherentiemetriek.
Hoe werd Grok 4.1 geëvalueerd en hoe presteerde het?
Wat lieten blinde menselijke voorkeurstesten zien?
Tijdens een stille uitrol kreeg Grok 4.1 in 64.78% van de gevallen de voorkeur boven het vorige productiemodel in live verkeer. Dit is een sterk menselijk voorkeurssignaal dat duidt op betere conversatie-uitkomsten in het echte verkeer.
Staat Grok 4.1 bovenaan de ranglijsten?
xAI meldt dat Grok 4.1's het denken modus zit op #1 op LMArena's Text Arena, met een gerapporteerde Elo van 1483en de niet-redenerende (snelle) modus staat op nummer 2 met 1465 Elo — sterke plaatsingen op de publieke ranglijst voor zowel nauwkeurigheid als presentatie (stijlcontrole speelt een rol).
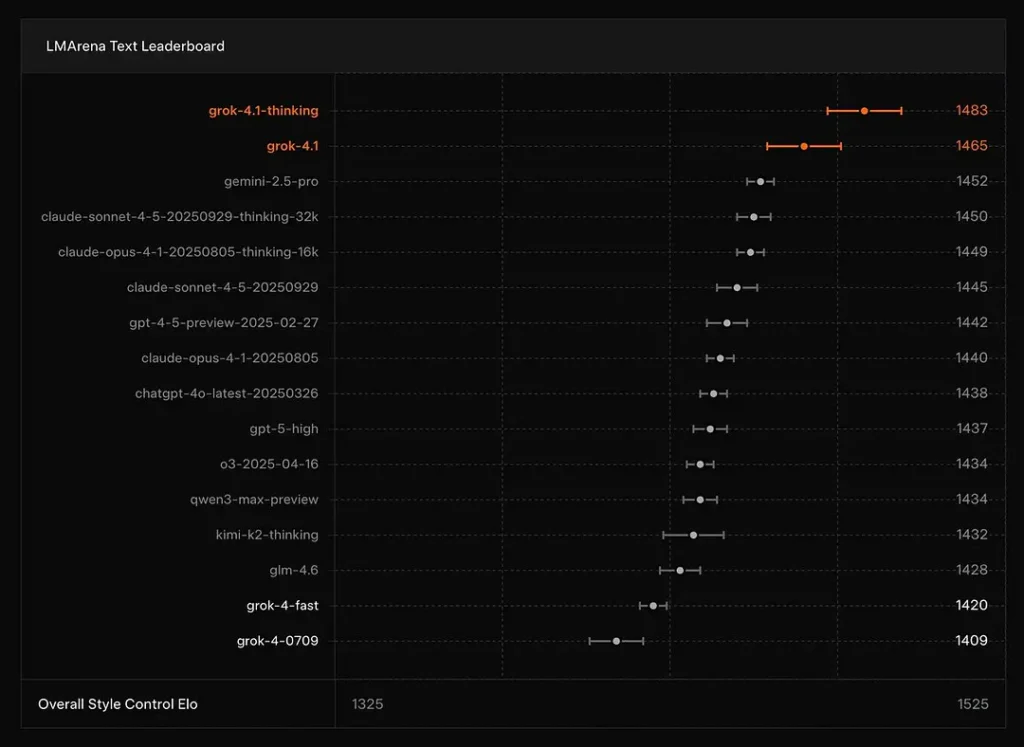
Conclusie: Grok 4.1 overtreft de gangbare GPT-4.5 en Claude-seriemodellen op het gebied van tekstbegrip, generatie en algehele kwaliteit. Alleen de GPT-5 Advanced Preview-versie presteert beter.
Emotionele intelligentie
xAI voerde EQ-Bench3 uit, een gespecialiseerde test voor emotionele intelligentie die 45 uitdagende rollenspelscenario's omvatte. Hieruit blijkt dat Grok 4.1 een sterke verbetering laat zien in empathie, tempo en interpersoonlijk inzicht. Grok 4.1 scoorde het hoogst op het gebied van begrip van contexten van verdriet, empathie en troost.

Creatief schrijven – is het daadwerkelijk fantasierijker?
Grok 4.1 werd geëvalueerd op Creatief schrijven v3 (32 prompts in 3 iteraties met rubric + Elo-score). xAI meldt dat de schrijfstijl, de consistentie van de stem en de verhalende creativiteit van 4.1 aanzienlijk zijn verbeterd, waardoor het bijna bovenaan de recente ranglijsten voor creatieve taken staat (voorbeeldprompts zijn opgenomen in de release). Onafhankelijke rapportages bevestigden deze bevindingen: recensenten zagen een duidelijk meer "onderscheidende stem" en een betere coherentie van lange teksten. Qua schrijfkwaliteit staat Grok 4.1 op de tweede plaats na de modellen uit de GPT-5-serie en overtreft het de volledige productlijnen van Claude, Gemini en Kimi.

Verminderde hallucinatie / eerlijkheid
xAI claimt een opmerkelijke vermindering van hallucinatiepercentages: ze meldden (in de aankondiging en sociale berichten) dat Grok 4.1 ~ is3x minder kans op hallucinaties Vergeleken met eerdere Grok-modellen, verwijzend naar productieverkeersanalyses en evaluaties in FActScore-stijl (bijv. bio/biografie-vragensets, hoe lager hoe beter). Vooral in de "niet-redenerende modus", waar externe zoektools beschikbaar zijn, is de consistentie van feiten stabieler.

Waarom verplettert Grok 4.1 andere modellen? Is dat overdreven?
"Crushes" is een marketingtruc, maar er zitten objectieve beweringen achter de bewering:
- leaderboards: Grok 4.1 staat bovenaan op de openbare LMArena-ranglijsten voor tekstgeneratie (1483 Elo voor de Thinking-modus) en scoort sterk op het gebied van creativiteit en EQ-benchmarks volgens de release van xAI. Dit zijn vergelijkbare concurrentiecijfers die binnen de community worden gebruikt.
- Voorkeur voor echt verkeer wint: xAI meldt dat menselijke voorkeuren winnen in blinde vergelijkingen (~65% voorkeur ten opzichte van het vorige productiemodel) dankzij een stille uitrol op live verkeer. Dit weerspiegelt verbeteringen door echte gebruikers, niet alleen op papier.
- Praktische nieuwe mogelijkheid: De combinatie van model-graders, RL op niet-verifieerbare signalen en strengere invoerfilters is een pragmatische technische stap die de gebruikerservaring direct verbetert bij conversatie-, empathische en creatieve taken, waarbij concurrenten historisch gezien ondermaats presteren.
Dus hoewel “verpletteren” een kleurrijke manier is om te zeggen “leads in meerdere openbare en interne evaluaties”, ondersteunen de onderliggende openbare statistieken die xAI publiceerde die conclusie
Hoe krijg ik toegang tot Grok 4.1?
Toegang voor consumenten/apps
xAI heeft Grok 4.1 periodiek gratis toegankelijk gemaakt in de "Auto"-modus of als promotievenster, maar premium-niveaus (SuperGrok, SuperGrok Heavy) en API-toegang met hogere quota bestaan en blijven beschikbaar als betaalde aanbiedingen.
Grok 4.1 is beschikbaar voor alle gebruikers on grok.com, **X (voorheen Twitter)**en de iOS- en Android-Grok-apps, die direct in de automatische modus worden uitgerold en ook expliciet als "Grok 4.1" in de modelkiezer kunnen worden geselecteerd.
API-toegang en ontwikkelaarsabonnementen
Grok 4.1-eindpunten zijn beschikbaar via de xAI API. Op het moment van publicatie van dit artikel was de officiële GPT 4.1 API nog niet uitgebracht.
KomeetAPI belooft de nieuwste modeldynamiek bij te houden, inclusief Grok 4.1 API, die gelijktijdig met de officiële release zal verschijnen. Kijk ernaar uit en blijf CometAPI in de gaten houden. Terwijl u wacht, kunt u ook de andere modellen van Grok bekijken, zoals Grok-code-fast-1 en Grok 4, verken hun mogelijkheden in de Playground en raadpleeg de API-gids voor gedetailleerde instructies om aan te roepen. Voordat u toegang krijgt, moet u ervoor zorgen dat u bent ingelogd op CometAPI en de API-sleutel hebt verkregen.
Praktische tips voor het gebruik van Grok 4.1 in productie
Hoe het risico op hallucinaties te verminderen
- Live zoeken inschakelen of een geverifieerde tool chain voor informatiezoekende vragen.
- Verificatiestappen bieden: vraag het model om bronnen en bewijs voor feitelijke beweringen te retourneren; gebruik de
responsemetadata om citaten te controleren (indien beschikbaar). - Voer deterministische controles uit (factchecking LLMs, gestructureerde datavalidators) als nabewerkingsstap voor belangrijke uitkomsten.
Hoe je toon en stijl beheerst
- Gebruik expliciete systeemprompts om de stem te corrigeren (“Je bent formeel en empathisch.”).
- Gebruik begeleide prompts en kleine lokale sjablonen voor een consistente spraak in alle toepassingen.
- Maak indien mogelijk gebruik van de stijlbedieningsoptie en beloningsgestuurde stuurknoppen van xAI.
Eindconclusie: is Grok 4.1 een grote verandering?
Grok 4.1 is niet een geheel nieuwe architectuur; het is eerder een verfijnde en doordachte na de training / uitlijning release die zich richt op wat mensen daadwerkelijk belangrijk vinden in de chat: persoonlijkheid, emotionele intelligentie, creativiteit en minder feitelijke foutenMeetbare winst op scoreborden, grootschalige voorkeuren voor real-traffic en verbeterde veiligheidstools. Voor applicaties die afhankelijk zijn van hoogwaardige conversaties, creatieve samenwerking of toongevoelige assistentie, is Grok 4.1 een grote stap voorwaarts en presteerde het in verschillende communitybenchmarks het best op het moment van release.
CometAPI is een commercieel API-aggregatieplatform dat ontwikkelaars uniforme REST-toegang in OpenAI-stijl biedt tot honderden AI-modellen van meerdere leveranciers – tekst-LLM's, beeld-/videogenerators, embeddings en meer – via één consistente interface. In plaats van aparte SDK's of op maat gemaakte eindpunten voor OpenAI, Anthropic, Google, Meta of kleinere gespecialiseerde modelleveranciers te gebruiken, kunt u met CometAPI verschillende modellen aanroepen door modelstrings en een paar parameters te wijzigen.
Klaar om te proberen?→ Meld u vandaag nog aan voor CometAPI !
Als u meer tips, handleidingen en nieuws over AI wilt weten, volg ons dan op VK, X en Discord!