
grok-code-fast-1 is xAI’s speed-focused, cost-efficient agentic coding model ontworpen om IDE-integraties en geautomatiseerde code-agents aan te sturen. Het model legt de nadruk op lage latentie, agent-gedreven gedragingen (tool-calls, stapsgewijze redeneersporen) en een compact kostenprofiel voor dagelijkse developer-workflows.
Belangrijkste functies (in één oogopslag)
- Hoge throughput / lage latentie: gericht op zeer snelle token-output en snelle completions voor IDE-gebruik.
- Agentische function-calling & tooling: ondersteunt functieaanroepen en orkestratie van externe tools (tests, linters, bestandsophalen) om meerstaps code-agents mogelijk te maken.
- Groot contextvenster: ontworpen om grote codebases en contexten met meerdere bestanden te verwerken (providers vermelden 256k-contextvensters in marketplace-adapters).
- Zichtbare redenering / sporen: reacties kunnen stapsgewijze redeneersporen bevatten, bedoeld om beslissingen van de agent inspecteerbaar en debugbaar te maken.
Technische details
Architectuur & training: xAI zegt dat grok-code-fast-1 vanaf de grond is gebouwd met een nieuwe architectuur en een pretraining-corpus rijk aan programmeerinhoud; het model heeft vervolgens natrainingscuratie gekregen op hoogwaardige, real-world pull-request-/code-datasets. Deze engineeringpijplijn is erop gericht het model praktisch inzetbaar te maken binnen agent-gedreven workflows (IDE + toolgebruik).
Serving & context: grok-code-fast-1 en typische gebruikspatronen gaan uit van streaming-uitvoer, functieaanroepen en rijke contextinjectie (bestandsuploads/-collecties). Diverse cloudmarktplaatsen en platformadapters vermelden het al met grote contextondersteuning (256k-contexten in sommige adapters).
Gebruiksgemakken: Zichtbare redeneersporen (het model toont zijn planning/toolgebruik), richtlijnen voor prompt-engineering en voorbeeldintegraties, en vroege launchpartner-integraties (bijv. GitHub Copilot, Cursor).
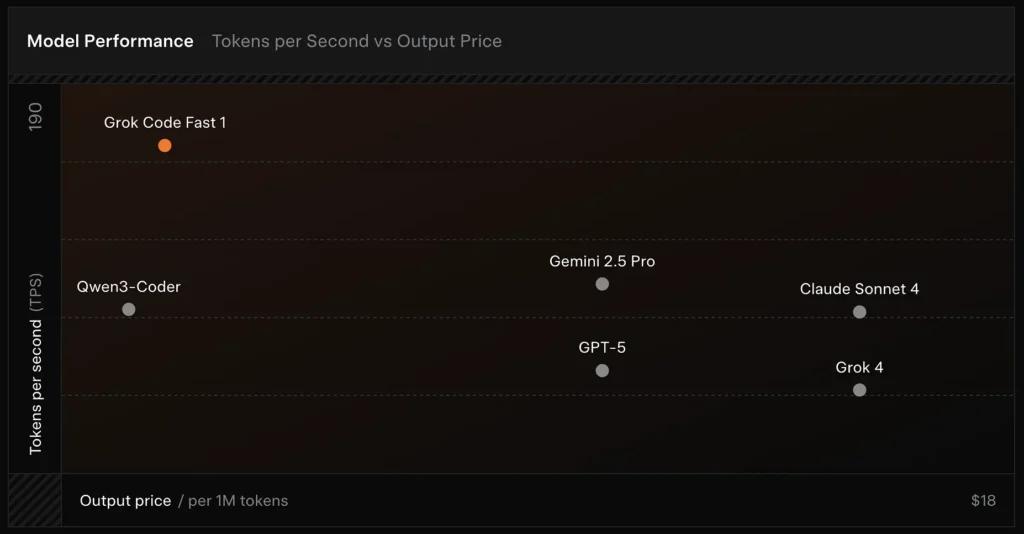
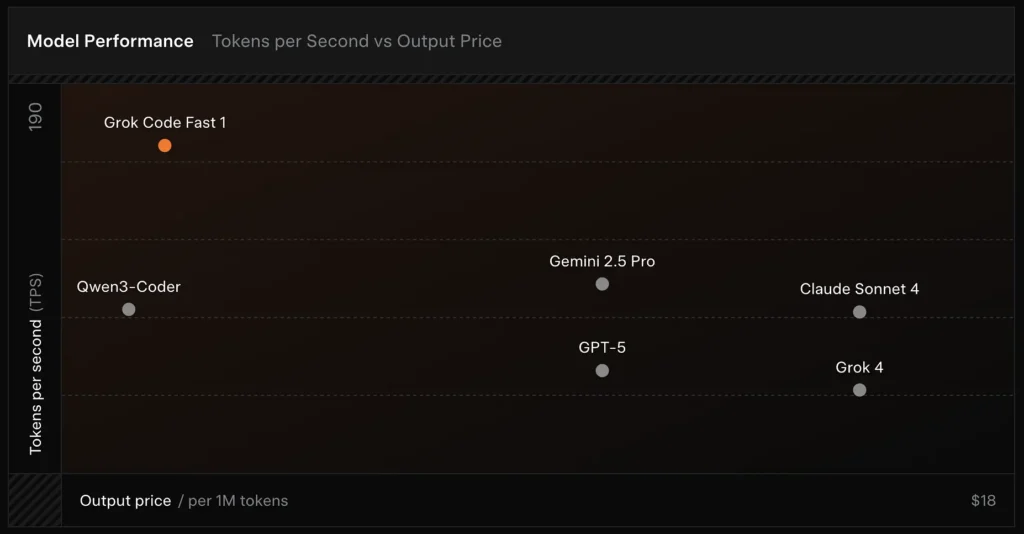
Benchmarkprestaties (waar het op scoort)
SWE-Bench-Verified: xAI rapporteert een 70.8% score op hun interne harness over de SWE-Bench-Verified-subset — een benchmark die vaak wordt gebruikt voor vergelijkingen van software-engineeringmodellen. Een recente hands-on evaluatie rapporteerde een gemiddelde menselijke beoordeling ≈ 7.6 op een gemengde codingsuite — competitief met enkele high-value modellen (bijv. Gemini 2.5 Pro) maar achter grotere multimodale/“best-reasoner”-modellen zoals Claude Opus 4 en xAI’s eigen Grok 4 op taken met hoge moeilijkheidsgraad qua redeneren. Benchmarks tonen ook variatie per taak: uitstekend voor veelvoorkomende bugfixes en beknopte codegeneratie, zwakker op sommige niche- of library-specifieke problemen (Tailwind CSS-voorbeeld).
Vergelijking:
- vs Grok 4: Grok-code-fast-1 levert wat in op absolute correctheid en diepere redenering in ruil voor veel lagere kosten en snellere throughput; Grok 4 blijft de optie met hogere capaciteit.
- vs Claude Opus / GPT-klasse: Die modellen lopen vaak voorop bij complexe, creatieve of moeilijke redeneertaken; Grok-code-fast-1 presteert goed bij grootschalige, routinematige developertaken waarbij latentie en kosten tellen.
Beperkingen & risico’s
Tot nu toe waargenomen praktische beperkingen:
- Domeingaps: prestatiezakkingen op nichebibliotheken of ongebruikelijk geformuleerde problemen (voorbeelden omvatten randgevallen in Tailwind CSS).
- Trade-off tussen redeneertokens en kosten: omdat het model interne redeneertokens kan uitsturen, kan zeer agentisch/uitvoerig redeneren de lengte van de uitvoer (en dus de kosten) verhogen.
- Nauwkeurigheid / randgevallen: hoewel sterk bij routinetaken, kan Grok-code-fast-1 hallucineren of onjuiste code produceren voor nieuwe algoritmen of adversariële probleemstellingen; het kan achterblijven bij topmodellen gericht op redeneren op veeleisende algoritmische benchmarks.
Typische gebruiksscenario’s
- IDE-assistentie & snelle prototyping: snelle completions, incrementeel code schrijven en interactieve debugging.
- Geautomatiseerde agents / code-workflows: agents die tests orkestreren, commando’s uitvoeren en bestanden bewerken (bijv. CI-helpers, bot-reviewers).
- Dagelijkse engineeringtaken: genereren van codeskeletten, refactors, bugtriagevoorstellen en projectopzet over meerdere bestanden waarbij lage latentie de ontwikkelaarsflow merkbaar verbetert.
Hoe de grok-code-fast-1-API aanroepen via CometAPI
grok-code-fast-1 API-prijzen in CometAPI, 20% korting op de officiële prijs:
- Inputtokens: $0.16/ M tokens
- Outputtokens: $2.0/ M tokens
Vereiste stappen
- Log in op cometapi.com. Als je nog geen gebruiker bent, registreer je dan eerst
- Haal de toegangssleutel (API key) van de interface op. Klik op “Add Token” bij de API token in het persoonlijk centrum, haal de tokensleutel op: sk-xxxxx en dien in.
Gebruiksmethode
- Selecteer het “
grok-code-fast-1”-endpoint om het API-verzoek te sturen en stel de request body in. De requestmethode en request body zijn te vinden in onze website-API-doc. Onze website biedt ook Apifox-tests voor je gemak. - Vervang <YOUR_API_KEY> door je daadwerkelijke CometAPI-sleutel uit je account.
- Plaats je vraag of verzoek in het content-veld — daarop zal het model reageren.
- . Verwerk de API-respons om het gegenereerde antwoord te krijgen.
CometAPI biedt een volledig compatibele REST-API — voor naadloze migratie. Belangrijke details naar API doc:
- Basis-URL: https://api.cometapi.com/v1/chat/completions
- Modelnamen: “
grok-code-fast-1“ - Authenticatie: Bearer-token via de header
Authorization: Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
API-integratie & voorbeelden
Python-fragment voor een ChatCompletion-aanroep via CometAPI:
pythonimport openai
openai.api_key = "YOUR_CometAPI_API_KEY"
openai.api_base = "https://api.cometapi.com/v1/chat/completions"
messages = [
{"role": "system", "content": "Je bent een behulpzame assistent."},
{"role": "user", "content": "Vat de belangrijkste functies van grok-code-fast-1 samen."}
]
response = openai.ChatCompletion.create(
model="grok-code-fast-1",
messages=messages,
temperature=0.7,
max_tokens=500
)
print(response.choices.message)
Zie ook Grok 4