
Gemini 2.5 Flash API คือโมเดล AI มัลติโหมดล่าสุดของ Google ที่ได้รับการออกแบบมาสำหรับงานความเร็วสูง ประหยัดต้นทุน พร้อมด้วยความสามารถในการใช้เหตุผลที่ควบคุมได้ ช่วยให้นักพัฒนาสามารถเปิดหรือปิดคุณสมบัติ "การคิด" ขั้นสูงได้ผ่าน Gemini API โมเดลล่าสุดคือ gemini-2.5-flash.
ภาพรวมของ Gemini 2.5 Flash
Gemini 2.5 Flash ได้รับการออกแบบมาให้ตอบสนองรวดเร็วโดยไม่กระทบต่อคุณภาพของผลลัพธ์ รองรับอินพุตแบบหลายโหมด ได้แก่ ข้อความ รูปภาพ เสียง และวิดีโอ ทำให้เหมาะสำหรับการใช้งานที่หลากหลาย โมเดลนี้เข้าถึงได้ผ่านแพลตฟอร์มต่างๆ เช่น Google AI Studio และ Vertex AI โดยมอบเครื่องมือที่จำเป็นสำหรับการบูรณาการเข้ากับระบบต่างๆ ได้อย่างราบรื่นให้กับนักพัฒนา
ข้อมูลพื้นฐาน (คุณสมบัติ)
Gemini 2.5 Flash เปิดตัวฟีเจอร์เด่นๆ หลายอย่าง ที่ ที่ทำให้แตกต่างจากตระกูล Gemini 2.5 คือ:
- การใช้เหตุผลแบบไฮบริด: นักพัฒนาสามารถตั้งค่าได้ การคิดงบประมาณ พารามิเตอร์ในการควบคุมอย่างละเอียดว่าโมเดลจะอุทิศโทเค็นจำนวนเท่าใดให้กับการใช้เหตุผลภายในก่อนส่งออก
- ชายแดนปาเรโต: ตั้งอยู่ ณ จุดคุ้มทุน-ประสิทธิภาพที่เหมาะสมที่สุดFlash นำเสนออัตราส่วนราคาต่อสติปัญญาที่ดีที่สุดในบรรดารุ่น 2.5
- การสนับสนุนหลายรูปแบบ: กระบวนการ ข้อความ, ภาพ, วีดีโอและ เสียง โดยพื้นฐานแล้ว ช่วยให้สามารถสนทนาและวิเคราะห์ได้หลากหลายยิ่งขึ้น
- บริบท 1 ล้านโทเค็น:ความยาวบริบทที่ไม่ตรงกันช่วยให้สามารถวิเคราะห์เชิงลึกและเข้าใจเอกสารยาวๆ ได้ในคำขอเดียว
การกำหนดเวอร์ชันของโมเดล
Gemini 2.5 Flash ได้ผ่านคีย์ต่อไปนี้ รุ่น:
- gemini-2.5-flash-lite-preview-09-2025: ปรับปรุงการใช้งานเครื่องมือ: เพิ่มประสิทธิภาพในการทำงานที่ซับซ้อนและมีหลายขั้นตอน โดยเพิ่มคะแนน SWE-Bench Verified ขึ้น 5% (จาก 48.9% เป็น 54%) เพิ่มประสิทธิภาพ: เมื่อเปิดใช้งานการใช้เหตุผล จะทำให้ได้ผลลัพธ์ที่มีคุณภาพสูงขึ้นโดยใช้โทเค็นน้อยลง ลดความหน่วงและต้นทุน
- ตัวอย่าง 04-17:การเปิดตัวการเข้าถึงล่วงหน้าพร้อมความสามารถในการ "คิด" มีให้บริการผ่าน เจมินี่-2.5-แฟลช-พรีวิว-04-17.
- ความพร้อมใช้งานทั่วไปที่เสถียร (GA):ณ วันที่ 17 มิถุนายน 2025 จุดสิ้นสุดที่เสถียร เจมินี่-2.5-แฟลช แทนที่การแสดงตัวอย่าง เพื่อให้มั่นใจถึงความน่าเชื่อถือในระดับการผลิตโดยไม่มีการเปลี่ยนแปลง API จากการดูตัวอย่างวันที่ 20 พฤษภาคม
- การเลิกใช้งานการดูตัวอย่าง:จุดสิ้นสุดการแสดงตัวอย่างมีกำหนดปิดระบบในวันที่ 15 กรกฎาคม พ.ศ. 2025 ผู้ใช้จะต้องย้ายไปยังจุดสิ้นสุด GA ก่อนวันที่นี้
ณ เดือนกรกฎาคม พ.ศ. 2025 Gemini 2.5 Flash พร้อมให้บริการสาธารณะและมีเสถียรภาพแล้ว (ไม่มีการเปลี่ยนแปลงจาก เจมินี่-2.5-แฟลช-พรีวิว-05-20 ).หากคุณกำลังใช้ gemini-2.5-flash-preview-04-17ราคาตัวอย่างที่มีอยู่จะยังคงอยู่ต่อไปจนกว่าจะมีการยุติการให้บริการรุ่นปลายทางตามกำหนดการในวันที่ 15 กรกฎาคม 2025 ซึ่งจะเป็นวันที่ปิดให้บริการ คุณสามารถย้ายไปยังรุ่นที่มีให้ใช้งานทั่วไปได้gemini-2.5-flash"
เร็วกว่า, ถูกกว่า, ฉลาดกว่า:
- เป้าหมายการออกแบบ: ความหน่วงต่ำ + ปริมาณงานสูง + ต้นทุนต่ำ
- ความเร็วโดยรวมในการทำงานด้านการใช้เหตุผล การประมวลผลหลายโหมด และงานข้อความยาวๆ
- การใช้โทเค็นลดลง 20–30% ซึ่งช่วยลดต้นทุนการใช้เหตุผลได้อย่างมาก
รายระเอียดทางเทคนิค
หน้าต่างบริบทอินพุต: โทเค็นสูงสุด 1 ล้านรายการ ช่วยให้สามารถเก็บรักษาบริบทได้อย่างครอบคลุม
โทเค็นเอาต์พุต: สามารถสร้างโทเค็นได้มากถึง 8,192 โทเค็นต่อการตอบกลับ
รูปแบบที่รองรับ: ข้อความ รูปภาพ เสียง และวิดีโอ
แพลตฟอร์มการรวมระบบ: พร้อมใช้งานผ่าน Google AI Studio และ Vertex AI
การกำหนดราคา: รูปแบบการกำหนดราคาตามโทเค็นที่มีการแข่งขัน ช่วยให้การปรับใช้มีประสิทธิภาพด้านต้นทุน
รายละเอียดทางเทคนิค
ภายใต้ฝากระโปรง Gemini 2.5 Flash เป็น แบบใช้หม้อแปลงไฟฟ้า โมเดลภาษาขนาดใหญ่ที่ฝึกอบรมด้วยข้อมูลผสมผสานระหว่างเว็บ โค้ด รูปภาพ และวิดีโอ คีย์ วิชาการ ข้อกำหนดรวมถึง:
การฝึกอบรมต่อเนื่องหลายรูปแบบ:ได้รับการฝึกฝนให้จัดแนวโหมดต่างๆ มากมาย Flash สามารถผสมข้อความได้อย่างราบรื่น ภาพ, วีดีโอหรือ เสียงมีประโยชน์สำหรับงานเช่นการสรุปวิดีโอหรือคำบรรยายเสียง
กระบวนการคิดแบบไดนามิก: ใช้งานวงจรการใช้เหตุผลภายในโดยที่แบบจำลอง แผน และ แบ่งคำกระตุ้นที่ซับซ้อนออก ก่อนผลลัพธ์สุดท้าย
งบประมาณการคิดที่กำหนดค่าได้: การคิดงบประมาณ สามารถตั้งค่าได้จาก 0 (ไม่มีเหตุผล) สูงถึง โทเค็น 24,576ช่วยให้สามารถแลกเปลี่ยนระหว่างความหน่วงและคุณภาพของคำตอบได้
การรวมเครื่องมือ: รองรับ การต่อสายดินด้วยการค้นหาของ Google, การรันโค้ด, บริบท URLและ การเรียกใช้ฟังก์ชันช่วยให้สามารถดำเนินการในโลกแห่งความเป็นจริงได้โดยตรงจากคำแนะนำภาษาธรรมชาติ
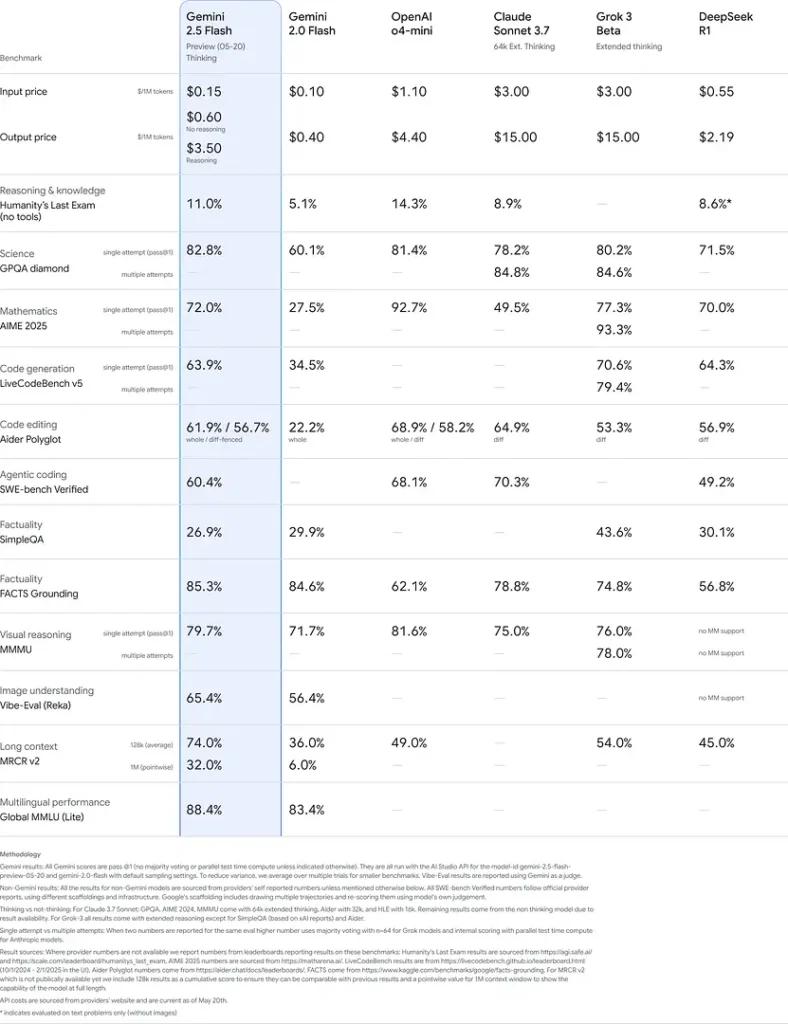
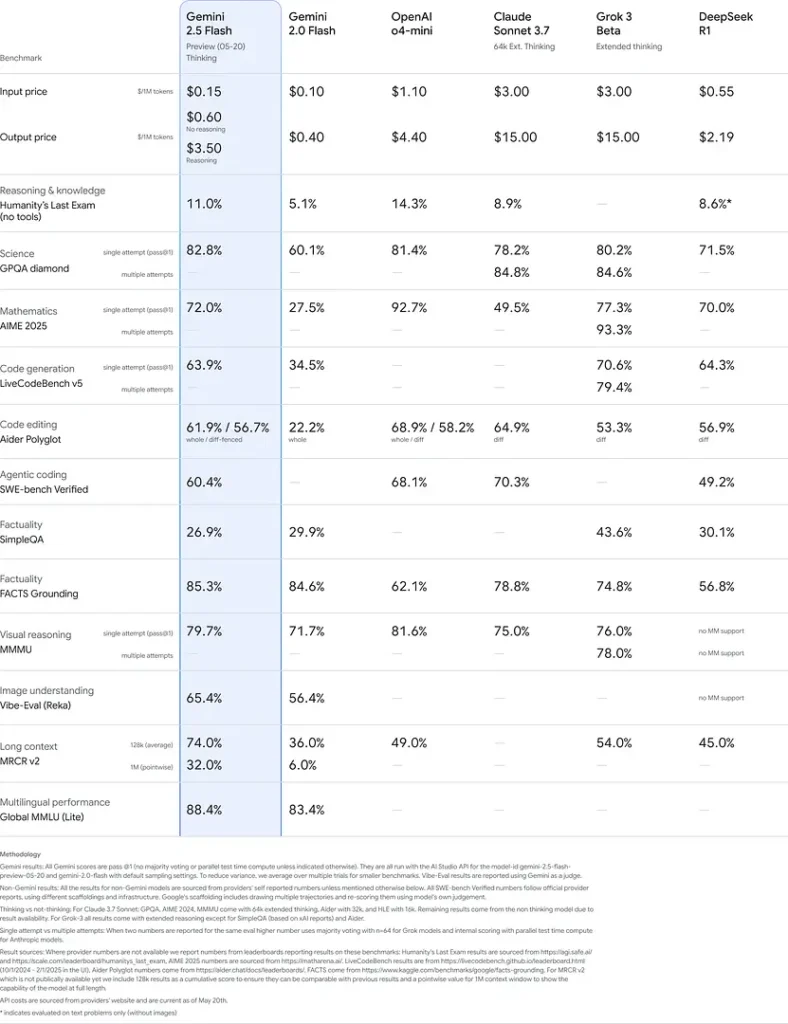
ประสิทธิภาพมาตรฐาน
ในการประเมินอย่างเข้มงวด Gemini 2.5 Flash แสดงให้เห็น ชั้นนำของอุตสาหกรรม ประสิทธิภาพ:
- LMArena ฮาร์ดพรอมต์: ได้คะแนนแล้ว รองจาก 2.5 Pro เท่านั้น ในการทดสอบ Hard Prompts ที่ท้าทาย แสดงให้เห็นถึงความสามารถในการใช้เหตุผลแบบหลายขั้นตอนที่แข็งแกร่ง
- คะแนน MMLU เท่ากับ 0.809: เกินประสิทธิภาพของรุ่นเฉลี่ยด้วย 0.809 ความแม่นยำของ MMLU สะท้อนให้เห็นถึงความรู้ในโดเมนที่กว้างขวางและความสามารถในการใช้เหตุผล
- เวลาแฝงและปริมาณงาน: บรรลุผล 271.4 โทเค็น/วินาที ความเร็วในการถอดรหัสด้วย 0.29 วินาที เวลาในการรับโทเค็นแรกทำให้เหมาะอย่างยิ่งสำหรับภาระงานที่มีความละเอียดอ่อนต่อความล่าช้า
- ผู้นำด้านราคาต่อประสิทธิภาพ: ที่ $0.26/1 M โทเค็นFlash ด้อยกว่าคู่แข่งหลายรายในขณะที่ยังเทียบเคียงหรือแซงหน้าในเกณฑ์มาตรฐานสำคัญ
ผลลัพธ์เหล่านี้บ่งชี้ถึงความได้เปรียบในการแข่งขันของ Gemini 2.5 Flash ในด้านการใช้เหตุผล ความเข้าใจทางวิทยาศาสตร์ การแก้ปัญหาทางคณิตศาสตร์ การเข้ารหัส การตีความภาพ และความสามารถด้านหลายภาษา
ข้อ จำกัด
แม้จะมีประสิทธิภาพ แต่ Gemini 2.5 Flash ก็มีคุณสมบัติบางอย่าง ข้อ จำกัด:
- ความเสี่ยงด้านความปลอดภัย:โมเดลนี้สามารถแสดง น้ำเสียง “เทศนา” และอาจสร้างผลลัพธ์ที่ฟังดูน่าเชื่อถือ แต่ไม่ถูกต้องหรือลำเอียง (ภาพหลอน) โดยเฉพาะอย่างยิ่งในคำถามที่มีลักษณะเฉพาะ การกำกับดูแลโดยมนุษย์อย่างเข้มงวดยังคงเป็นสิ่งจำเป็น
- ขีดจำกัดอัตรา:การใช้งาน API ถูกจำกัดด้วยอัตราจำกัด (10 RPM, 250,000 TPM, 250 RPD บนระดับเริ่มต้น) ซึ่งอาจส่งผลกระทบต่อการประมวลผลแบบแบตช์หรือแอปพลิเคชันที่มีปริมาณงานสูง
- ชั้นข่าวกรอง:ในขณะที่มีความสามารถพิเศษในการ แฟลช แบบจำลองยังคงมีความแม่นยำน้อยกว่า โปร 2.5 สำหรับงานที่ต้องใช้ตัวแทนจำนวนมาก เช่น การเข้ารหัสขั้นสูงหรือการประสานงานระหว่างตัวแทนหลายราย
- การแลกเปลี่ยนต้นทุน: แม้ว่าจะเสนอสิ่งที่ดีที่สุด ราคา-ประสิทธิภาพการใช้อย่างกว้างขวางของ คิด โหมดนี้จะเพิ่มการใช้โทเค็นโดยรวม ทำให้ต้นทุนในการกระตุ้นการใช้เหตุผลเชิงลึกเพิ่มขึ้น
ดูเพิ่มเติม API เจมินี่ 2.5 โปร
สรุป
Gemini 2.5 Flash ถือเป็นเครื่องพิสูจน์ถึงความมุ่งมั่นของ Google ในการพัฒนาเทคโนโลยี AI ด้วยประสิทธิภาพที่แข็งแกร่ง ความสามารถแบบหลายโหมด และการจัดการทรัพยากรที่มีประสิทธิภาพ จึงทำให้ Gemini XNUMX Flash กลายเป็นโซลูชันที่ครอบคลุมสำหรับนักพัฒนาและองค์กรที่ต้องการใช้ประโยชน์จากพลังของปัญญาประดิษฐ์ในการทำงาน
วิธีการโทร Gemini 2.5 Flash API จาก CometAPI
Gemini 2.5 Flash ราคา API ใน CometAPI ลด 20% จากราคาอย่างเป็นทางการ:
- อินพุตโทเค็น: $0.24 / M โทเค็น
- โทเค็นเอาต์พุต: $0.96/ M โทเค็น
ขั้นตอนที่ต้องดำเนินการ
- เข้าสู่ระบบเพื่อ โคเมตาปิดอทคอม. หากคุณยังไม่ได้เป็นผู้ใช้ของเรา กรุณาลงทะเบียนก่อน
- รับรหัส API ของข้อมูลรับรองการเข้าถึงของอินเทอร์เฟซ คลิก "เพิ่มโทเค็น" ที่โทเค็น API ในศูนย์ส่วนบุคคล รับรหัสโทเค็น: sk-xxxxx และส่ง
- รับ url ของเว็บไซต์นี้: https://api.cometapi.com/
วิธีการใช้งาน
- เลือก“
gemini-2.5-flash” จุดสิ้นสุดในการส่งคำขอ API และกำหนดเนื้อหาคำขอ วิธีการคำขอและเนื้อหาคำขอได้รับจากเอกสาร API ของเว็บไซต์ของเรา เว็บไซต์ของเรายังมีการทดสอบ Apifox เพื่อความสะดวกของคุณอีกด้วย - แทนที่ ด้วยคีย์ CometAPI จริงจากบัญชีของคุณ
- แทรกคำถามหรือคำขอของคุณลงในช่องเนื้อหา—นี่คือสิ่งที่โมเดลจะตอบสนอง
- ประมวลผลการตอบสนองของ API เพื่อรับคำตอบที่สร้างขึ้น
สำหรับข้อมูลการเปิดตัวโมเดลใน Comet API โปรดดู https://api.cometapi.com/new-model.
สำหรับข้อมูลราคาโมเดลใน Comet API โปรดดู https://api.cometapi.com/pricing.
ตัวอย่างการใช้งาน API
นักพัฒนาสามารถโต้ตอบกับ เจมินี่-2.5-แฟลช ผ่านทาง API ของ CometAPI ซึ่งช่วยให้สามารถบูรณาการเข้ากับแอปพลิเคชันต่างๆ ได้ ด้านล่างนี้คือตัวอย่าง Python:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
สคริปต์นี้จะส่งคำเตือนไปที่ Gemini 2.5 Flash สร้างแบบจำลองและพิมพ์คำตอบที่สร้างขึ้น พร้อมสาธิตวิธีใช้ Gemini 2.5 Flash สำหรับคำอธิบายที่ซับซ้อน