
Gemini 2.5 Flash API là mô hình AI đa phương thức mới nhất của Google, được thiết kế cho các tác vụ tốc độ cao, tiết kiệm chi phí với khả năng suy luận có thể kiểm soát, cho phép các nhà phát triển bật hoặc tắt các tính năng "suy nghĩ" nâng cao thông qua Gemini API. Các mô hình mới nhất là gemini-2.5-flash.
Tổng quan về Gemini 2.5 Flash
Gemini 2.5 Flash được thiết kế để cung cấp phản hồi nhanh mà không ảnh hưởng đến chất lượng đầu ra. Nó hỗ trợ đầu vào đa phương thức, bao gồm văn bản, hình ảnh, âm thanh và video, làm cho nó phù hợp với nhiều ứng dụng khác nhau. Mô hình có thể truy cập thông qua các nền tảng như Google AI Studio và Vertex AI, cung cấp cho các nhà phát triển các công cụ cần thiết để tích hợp liền mạch vào nhiều hệ thống khác nhau.
Thông tin cơ bản (Tính năng)
Gemini 2.5 Flash giới thiệu một số tính năng nổi bật Tính năng, đặc điểm để phân biệt nó trong nhóm Gemini 2.5:
- Lý luận lai ghép: Các nhà phát triển có thể thiết lập một suy nghĩ_ngân_sách tham số để kiểm soát chính xác số lượng mã thông báo mà mô hình dành cho suy luận nội bộ trước khi đưa ra kết quả.
- Đường biên Pareto: Tọa lạc tại điểm hiệu suất chi phí tối ưuFlash cung cấp tỷ lệ giá cả/trí thông minh tốt nhất trong số 2.5 mẫu.
- Hỗ trợ đa phương thức: Các quy trình văn bản, hình ảnh, videovà âm thanh bản địa, cho phép khả năng đàm thoại và phân tích phong phú hơn.
- Bối cảnh 1 triệu mã thông báo: Độ dài ngữ cảnh không khớp cho phép phân tích sâu và hiểu tài liệu dài trong một yêu cầu duy nhất.
Phiên bản mô hình
Gemini 2.5 Flash đã chuyển đổi qua khóa sau phiên bản:
- gemini-2.5-flash-lite-preview-09-2025: Khả năng sử dụng công cụ được cải thiện: Hiệu suất được cải thiện trên các tác vụ phức tạp, nhiều bước, với điểm số SWE-Bench Verified tăng 5% (từ 48.9% lên 54%). Hiệu quả được cải thiện: Khi kích hoạt suy luận, đầu ra chất lượng cao hơn có thể đạt được với ít mã thông báo hơn, giúp giảm độ trễ và chi phí.
- Xem trước 04-17: Bản phát hành truy cập sớm với khả năng “suy nghĩ”, có sẵn thông qua song tử-2.5-flash-xem-trước-04-17.
- Khả năng sử dụng chung ổn định (GA): Tính đến ngày 17 tháng 2025 năm XNUMX, điểm cuối ổn định song tử-2.5-flash thay thế bản xem trước, đảm bảo độ tin cậy ở cấp độ sản xuất mà không có thay đổi API nào so với bản xem trước ngày 20 tháng XNUMX.
- Việc ngừng sử dụng Preview: Các điểm cuối xem trước đã được lên lịch ngừng hoạt động vào ngày 15 tháng 2025 năm XNUMX; người dùng phải di chuyển đến điểm cuối GA trước ngày này.
Tính đến tháng 2025 năm 2.5, Gemini XNUMX Flash hiện đã có sẵn cho công chúng và ổn định (không có thay đổi nào so với song tử-2.5-flash-xem-trước-05-20 ).Nếu bạn đang sử dụng gemini-2.5-flash-preview-04-17, mức giá xem trước hiện tại sẽ tiếp tục cho đến khi điểm cuối của mô hình dự kiến ngừng hoạt động vào ngày 15 tháng 2025 năm XNUMX, khi đó mô hình sẽ bị đóng cửa. Bạn có thể chuyển sang mô hình có sẵn rộng rãi “gemini-2.5-flash".
Nhanh hơn, rẻ hơn, thông minh hơn:
- Mục tiêu thiết kế: độ trễ thấp + thông lượng cao + chi phí thấp;
- Tăng tốc tổng thể trong suy luận, xử lý đa phương thức và các tác vụ văn bản dài;
- Việc sử dụng mã thông báo được giảm 20–30%, giúp giảm đáng kể chi phí suy luận.
Thông sô ky thuật
Cửa sổ ngữ cảnh đầu vào: Lên đến 1 triệu mã thông báo, cho phép lưu giữ ngữ cảnh rộng rãi.
Mã thông báo đầu ra: Có khả năng tạo ra tối đa 8,192 mã thông báo cho mỗi phản hồi.
Các phương thức được hỗ trợ: Văn bản, hình ảnh, âm thanh và video.
Nền tảng tích hợp: Có sẵn thông qua Google AI Studio và Vertex AI.
Giá cả: Mô hình định giá cạnh tranh dựa trên mã thông báo, giúp triển khai tiết kiệm chi phí.
Chi tiết kỹ thuật
Dưới mui xe, Gemini 2.5 Flash là một dựa trên máy biến áp mô hình ngôn ngữ lớn được đào tạo trên hỗn hợp dữ liệu web, mã, hình ảnh và video. Chìa khóa kỹ thuật thông số kỹ thuật bao gồm:
Đào tạo đa phương thức: Được đào tạo để căn chỉnh nhiều phương thức, Flash có thể kết hợp văn bản một cách liền mạch với hình ảnh, video, hoặc là âm thanh, hữu ích cho các tác vụ như tóm tắt video hoặc chú thích âm thanh.
Quá trình tư duy năng động: Triển khai một vòng lặp lý luận nội bộ trong đó mô hình kế hoạch và phá vỡ các lời nhắc phức tạp trước khi xuất ra kết quả cuối cùng.
Ngân sách tư duy có thể cấu hình: Các suy nghĩ_ngân_sách có thể được thiết lập từ 0 (không có lý luận) lên đến 24,576 mã thông báo, cho phép cân bằng giữa độ trễ và chất lượng câu trả lời.
Tích hợp công cụ: Hỗ trợ Tiếp đất với Google Tìm kiếm, Thực thi mã, Bối cảnh URLvà Gọi hàm, cho phép thực hiện các hành động thực tế trực tiếp từ lời nhắc bằng ngôn ngữ tự nhiên.
Hiệu suất chuẩn
Trong các đánh giá nghiêm ngặt, Gemini 2.5 Flash chứng minh đầu ngành hiệu suất:
- LMArena Lời nhắc khó: Ghi bàn chỉ đứng sau 2.5 Pro trên chuẩn mực Hard Prompts đầy thử thách, thể hiện khả năng lập luận nhiều bước mạnh mẽ.
- Điểm MMLU là 0.809: Vượt quá hiệu suất mô hình trung bình với 0.809 Độ chính xác của MMLU, phản ánh kiến thức rộng về lĩnh vực và khả năng lập luận của nó.
- Độ trễ và thông lượng: Đạt được 271.4 token/giây tốc độ giải mã với một 0.29 giây Thời gian đến mã thông báo đầu tiên, khiến nó trở nên lý tưởng cho khối lượng công việc nhạy cảm với độ trễ.
- Nhà lãnh đạo về giá cả trên hiệu suất: Tại $0.26/1 triệu tokenFlash đánh bại nhiều đối thủ cạnh tranh trong khi vẫn ngang bằng hoặc vượt trội hơn họ ở các tiêu chuẩn quan trọng.
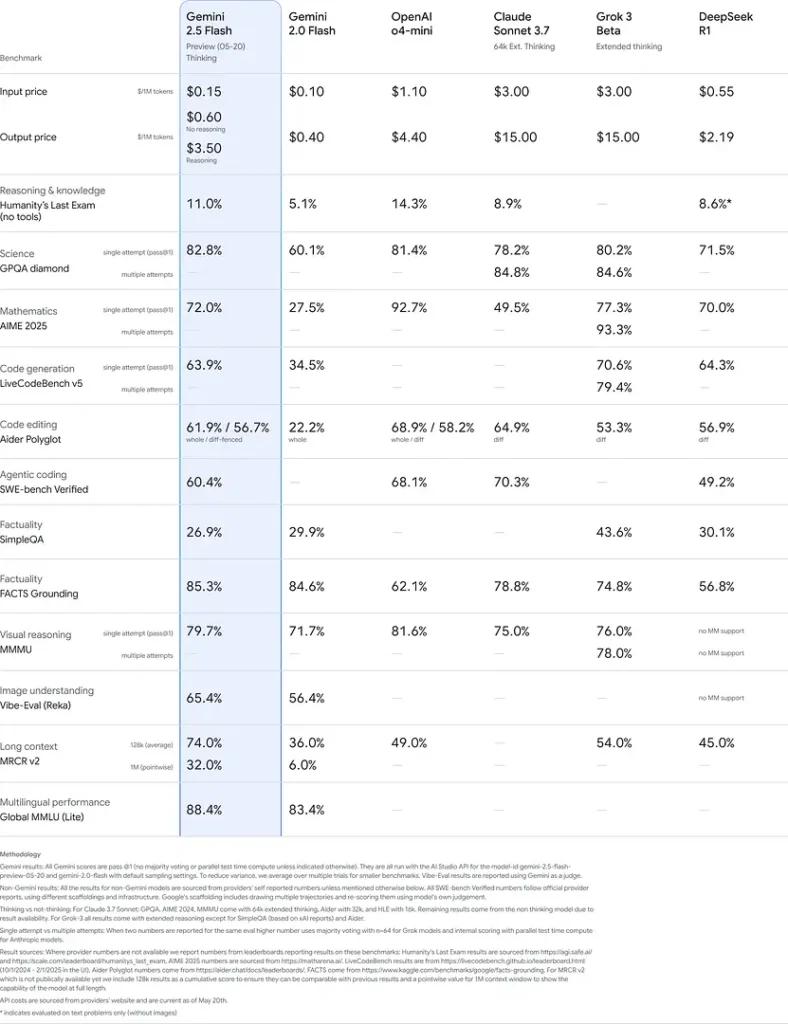
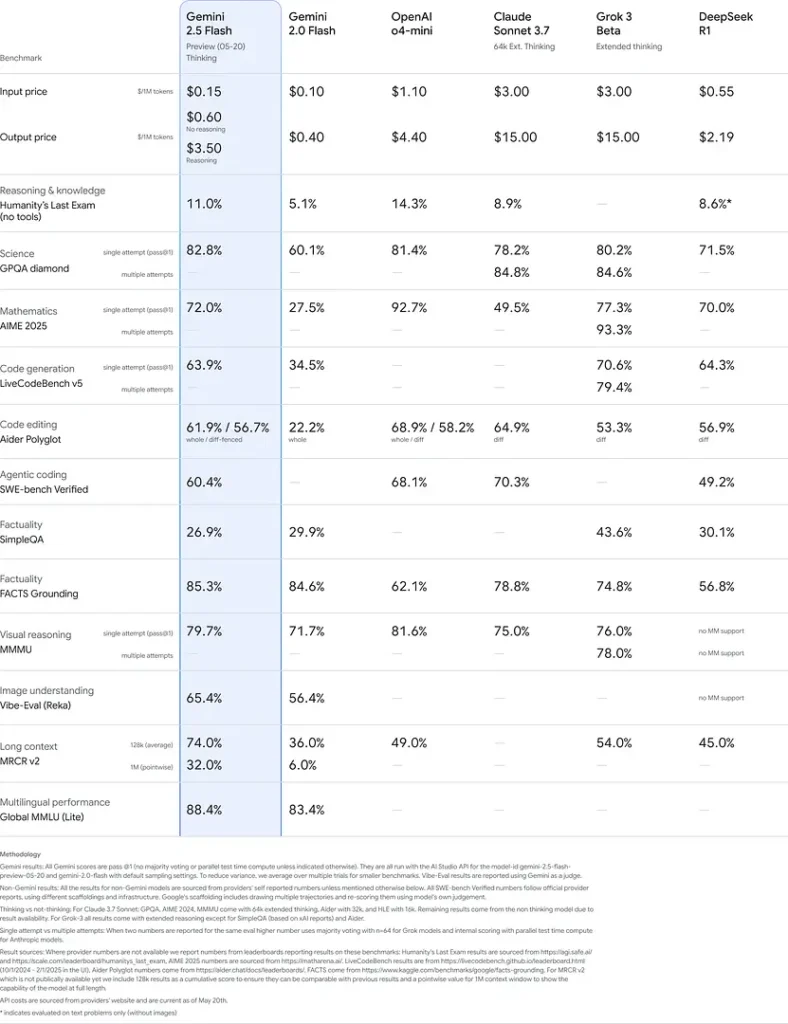
Những kết quả này cho thấy lợi thế cạnh tranh của Gemini 2.5 Flash về khả năng lập luận, hiểu biết khoa học, giải quyết vấn đề toán học, lập trình, diễn giải trực quan và khả năng đa ngôn ngữ:
Hạn chế
Mặc dù mạnh mẽ, Gemini 2.5 Flash mang một số hạn chế:
- Rủi ro an toàn: Mô hình có thể thể hiện một giọng điệu "giảng đạo" và có thể tạo ra những kết quả nghe có vẻ hợp lý nhưng không chính xác hoặc thiên vị (ảo giác), đặc biệt là đối với các truy vấn ngoại lệ. Sự giám sát chặt chẽ của con người vẫn là điều cần thiết.
- Giới hạn tỷ lệ: Việc sử dụng API bị hạn chế bởi giới hạn tốc độ (10 RPM, 250,000 TPM, 250 RPD ở các tầng mặc định), điều này có thể ảnh hưởng đến quá trình xử lý hàng loạt hoặc các ứng dụng khối lượng lớn.
- Tầng tình báo: Mặc dù có khả năng đặc biệt cho một đèn flash mô hình, nó vẫn kém chính xác hơn 2.5 Pro đối với các nhiệm vụ tác nhân đòi hỏi khắt khe nhất như mã hóa nâng cao hoặc phối hợp nhiều tác nhân.
- Sự đánh đổi về chi phí: Mặc dù cung cấp những gì tốt nhất giá-hiệu suất, sử dụng rộng rãi Suy nghĩ chế độ này làm tăng tổng lượng tiêu thụ mã thông báo, làm tăng chi phí cho các lời nhắc lý luận sâu sắc.
Xem thêm API Gemini 2.5 Pro
Kết luận
Gemini 2.5 Flash là minh chứng cho cam kết của Google trong việc thúc đẩy công nghệ AI. Với hiệu suất mạnh mẽ, khả năng đa phương thức và quản lý tài nguyên hiệu quả, nó cung cấp giải pháp toàn diện cho các nhà phát triển và tổ chức muốn khai thác sức mạnh của trí tuệ nhân tạo trong hoạt động của họ.
Cách gọi Gemini 2.5 Flash API từ CometAPI
Gemini 2.5 Flash Giá API trong CometAPI,giảm giá 20% so với giá chính thức:
- Mã thông báo đầu vào: 0.24 đô la/M mã thông báo
- Mã thông báo đầu ra: 0.96 đô la/M mã thông báo
Các bước cần thiết
- Đăng nhập vào " cometapi.com. Nếu bạn chưa phải là người dùng của chúng tôi, vui lòng đăng ký trước
- Nhận khóa API thông tin xác thực truy cập của giao diện. Nhấp vào “Thêm mã thông báo” tại mã thông báo API trong trung tâm cá nhân, nhận khóa mã thông báo: sk-xxxxx và gửi.
- Lấy url của trang web này: https://api.cometapi.com/
Phương pháp sử dụng
- Chọn hàng**
gemini-2.5-flash**” điểm cuối để gửi yêu cầu API và thiết lập nội dung yêu cầu. Phương thức yêu cầu và nội dung yêu cầu được lấy từ tài liệu API của trang web của chúng tôi. Trang web của chúng tôi cũng cung cấp thử nghiệm Apifox để thuận tiện cho bạn. - Thay thế bằng khóa CometAPI thực tế từ tài khoản của bạn.
- Chèn câu hỏi hoặc yêu cầu của bạn vào trường nội dung—đây là nội dung mà mô hình sẽ phản hồi.
- . Xử lý phản hồi API để nhận được câu trả lời đã tạo.
Để biết thông tin về Model được lưu trong Comet API, vui lòng xem https://api.cometapi.com/new-model.
Để biết thông tin về Giá mẫu trong Comet API, vui lòng xem https://api.cometapi.com/pricing.
Ví dụ sử dụng API
Các nhà phát triển có thể tương tác với song tử-2.5-flash thông qua API của CometAPI, cho phép tích hợp vào nhiều ứng dụng khác nhau. Dưới đây là một ví dụ về Python:
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response)
Tập lệnh này gửi một lời nhắc đến Gemini 2.5 Flash mô hình và in phản hồi được tạo ra, chứng minh cách sử dụng Gemini 2.5 Flash để có những lời giải thích phức tạp.