

GLM-5-Turbo là một LLM nền tảng mới từ Zhipu AI, được huấn luyện và tinh chỉnh đặc biệt cho các quy trình kiểu tác tử (công ty gọi hệ sinh thái mục tiêu là OpenClaw / các kịch bản “lobster”). Mô hình cung cấp ngữ cảnh rất dài (lên đến ~200K token), streaming và đầu ra có cấu trúc, tỷ lệ lỗi gọi công cụ thấp hơn (báo cáo ~0,67% trong các thử nghiệm của bên thứ ba), và giá theo token thấp hơn đáng kể. Mô hình hướng tới việc đánh đổi một phần nhỏ thông lượng tối đa cho một lượt để có được độ ổn định tốt hơn nhiều, độ tin cậy của công cụ, khả năng xử lý tác vụ theo lịch/duy trì và thực thi chuỗi dài—hữu ích cho tác tử tự động, hệ thống điều phối và pipeline đa công cụ.
GLM-5-Turbo là gì?
GLM-5-Turbo được Zhipu giới thiệu như một mô hình nền tảng được xây dựng chuyên cho điều phối tác tử và các quy trình tự động phức tạp thay vì một mô hình chat hay đa phương thức chung. Các lựa chọn thiết kế nhấn mạnh:
- Huấn luyện gốc thân thiện với tác tử (sử dụng công cụ, tuân thủ lệnh, tác vụ theo thời gian/duy trì).
- Cửa sổ ngữ cảnh rất lớn và khả năng xuất đầu ra để hỗ trợ phiên dài, bộ nhớ và lập kế hoạch chuỗi suy nghĩ.
- Suy luận ổn định, thông lượng cao cho các luồng nghiệp vụ dài và tác vụ theo lịch.
Không giống các LLM truyền thống tối ưu cho chat hoặc sinh văn bản, GLM-5-Turbo là:
- Ưu tiên tác tử (không phải ưu tiên chat)
- Xây dựng cho môi trường OpenClaw (“lobster”)
- Thiết kế cho quy trình tự động nhiều bước
🦞 “Lobster Agent” nghĩa là gì?
Khái niệm “lobster” đề cập tới OpenClaw, hệ sinh thái tác tử AI của Zhipu, nơi các mô hình:
- Sử dụng công cụ một cách linh hoạt
- Thực thi các chuỗi tác vụ dài
- Duy trì bộ nhớ bền bỉ
- Hoạt động xuyên suốt terminal, ứng dụng và API
GLM-5-Turbo được tối ưu sâu cho mô hình này, giải quyết các vấn đề cốt lõi của tác tử như:
- Độ tin cậy khi gọi công cụ
- Phân rã tác vụ
- Lập kế hoạch tầm xa
- Ổn định khi thực thi
Tính năng chính và lý do quan trọng
Ngữ cảnh dài + dung lượng đầu ra lớn (200K / 128K)
Cửa sổ ngữ cảnh 200K token và khả năng xuất 128K token cho phép GLM-5-Turbo:
- Duy trì bộ nhớ mở rộng của ngữ cảnh trước đó (hội thoại, đầu ra công cụ, kết quả trung gian).
- Tạo ra các hiện vật rất dài (kế hoạch nhiều giai đoạn, báo cáo dài, codebase) mà không cần ghép ngữ cảnh nhiều lần.
- Lưu trữ các tác tử đa lượt phải giữ toàn bộ lịch sử thực thi để ra quyết định chính xác.
Đây là lựa chọn kỹ thuật có chủ đích cho tác tử—thay vì chia nhiệm vụ thành các prompt ngắn, tác tử có thể duy trì trạng thái mạch lạc qua hàng nghìn lượt hội thoại hoặc bước.
Các nguyên thủy tác tử được nhúng vào quá trình huấn luyện
Thay vì “độ” một mô hình mục đích chung cho nhiệm vụ tác tử, GLM-5-Turbo được huấn luyện với các mục tiêu kiểu tác tử (ví dụ: hành vi gọi công cụ, phân tích lệnh/đối số). Tác dụng được khẳng định là ít ảo giác hơn khi gọi công cụ, kế hoạch nhiều bước ổn định hơn, và cải thiện độ trễ trong các lần chạy dài—tất cả đều có giá trị khi tự động hóa phải chuỗi nhiều API hoặc công cụ bên ngoài một cách tin cậy.
Thông lượng và ổn định thực thi
Biến thể GLM-5-Turbo cải thiện ổn định thực thi và thông lượng cho các luồng nghiệp vụ dài so với các mô hình tổng quát—ngôn ngữ tiếp thị nhấn mạnh “thực thi thông lượng cao” và “độ ổn định phản hồi hàng đầu” trong số các mô hình tương tự. Đây là những yếu tố có ý nghĩa cho triển khai tác tử doanh nghiệp, nơi một bước thất bại có thể làm hỏng cả pipeline. Các điểm chuẩn độc lập từ bên thứ ba vẫn đang tiếp tục xuất hiện.
Dữ liệu điểm chuẩn của GLM-5-Turbo
Lưu ý: Zhipu đã công bố các đánh giá nội bộ, và có các điểm chuẩn bên thứ ba/học thuật cho GLM-5. GLM-5-Turbo mới phát hành; các lần chạy điểm chuẩn độc lập từ cộng đồng sẽ cần thời gian để xuất hiện. Dưới đây là các con số công bố được xem là đáng tin cậy nhất và ngữ cảnh.
GLM-5 (tham chiếu) — số liệu công bố tiêu biểu
GLM-5 (đàn anh của Turbo) của Zhipu báo cáo dẫn đầu ở nhiều tác vụ kỹ thuật/khoa học quy trình—ví dụ:
- SWE-bench Verified: 77.8 (được ghi trong tài liệu GLM-5 là điểm dẫn đầu trong số các mô hình mở).
- Terminal Bench 2.0: 56.2 (được báo cáo là hiệu năng đầu bảng trong các mô hình mở trên phân phối này).
Những con số đó thiết lập GLM-5 là một chuẩn cao trong các tác vụ kỹ thuật phần mềm và thực thi; GLM-5-Turbo được định vị là đánh đổi một phần nhấn mạnh kích thước/tham số thuần để lấy độ tin cậy tác tử và thông lượng tốt hơn. GLM-5-Turbo cho thấy ~0,67% lỗi gọi công cụ trong các lần so sánh của họ, thấp đáng kể so với các lần chạy GLM-5 đối sánh dao động ~2,33% đến 6,41%.
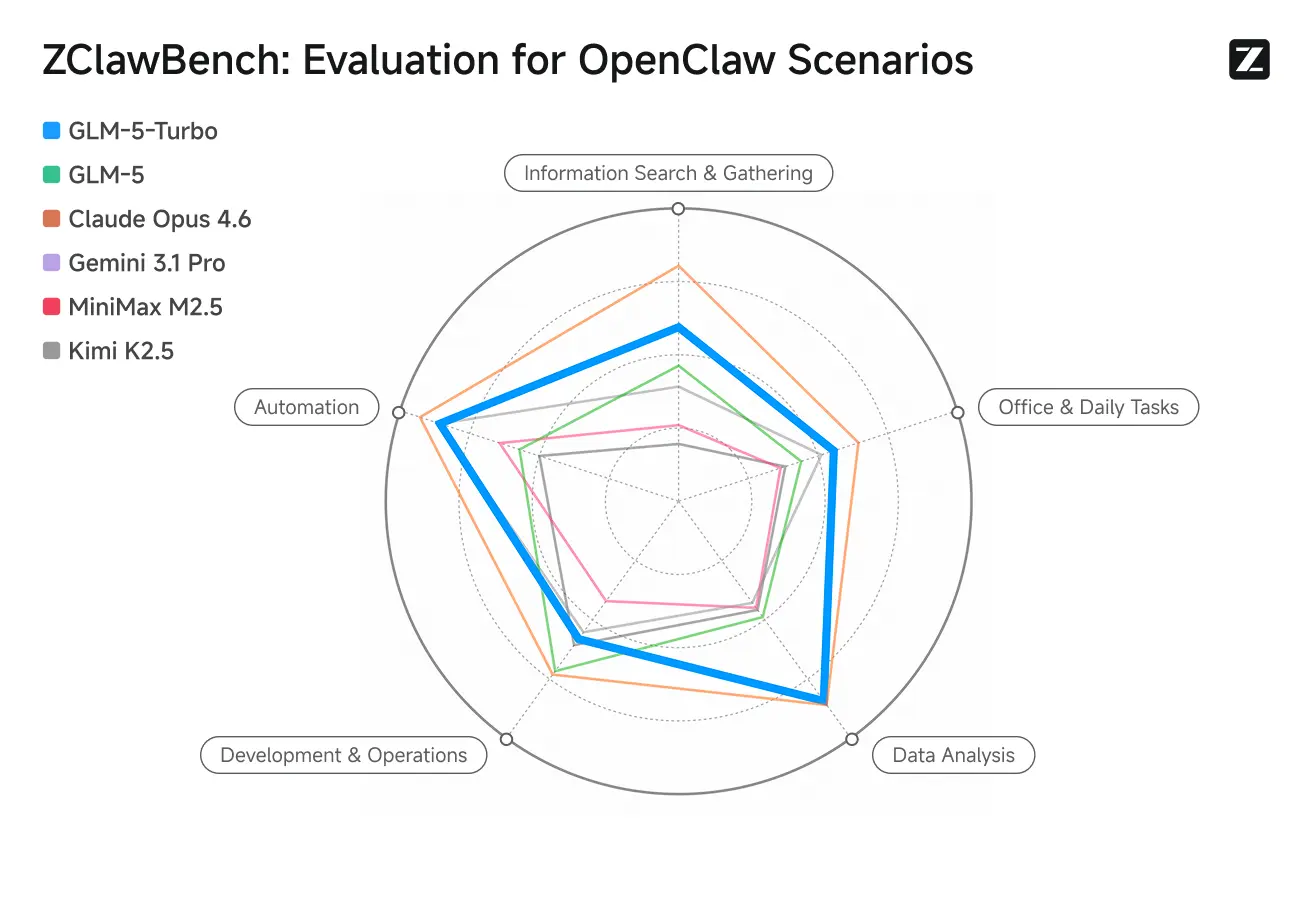
ZClawBench: Bài kiểm thử điểm chuẩn cho các kịch bản Proxy OpenClaw
Zhipu cũng phát hành điểm chuẩn ZClawBench để đánh giá tác tử thông minh. Trong các thử nghiệm mù bao phủ các lĩnh vực đa dạng như phát triển mã, phân tích dữ liệu và tạo nội dung, mô hình mới có mã danh Pony-Alpha-2 đã giành được thiện cảm của 90% người tham gia.
Giá & khả dụng (ai bán và giá bao nhiêu)
Zhipu đã áp dụng ~20% tăng giá API cho GLM-5-Turbo khi ra mắt và đồng thời giới thiệu các gói thuê bao “Lobster Package” nhằm làm phẳng giá token cho triển khai tác tử.
Các gói thuê bao đã công bố (ví dụ)
Hai gói Lobster minh họa (giá là quy đổi và xấp xỉ):
- Gói Lobster cơ bản:
39 CNY / tháng (US$5.66) cho 35,000,000 token. - Gói Lobster trung cấp:
99 CNY / tháng (US$14.36) cho 100,000,000 token.
Dựa trên các con số công bố, chi phí cho 1 triệu token xấp xỉ:
- Gói cơ bản: ~US$0.162 cho mỗi 1M token.
- Gói trung cấp: ~US$0.144 cho mỗi 1M token.
Các con số “trên mỗi 1M” này là phép quy đổi trực tiếp từ chi phí thuê bao và hạn mức token đã công bố, nhằm minh họa kinh tế học cho khối lượng tác tử lớn. (Tính toán dựa trên tiền tệ và số lượng token được báo chí đưa tin.)
Giá API
Niêm yết trên marketplace đại diện (CometAPI): $0.96 cho mỗi 1M token đầu vào và $3.20 cho mỗi 1M token đầu ra cho GLM-5-Turbo.
Trang giá dành cho nhà phát triển của Zhipu (Z.ai) liệt kê mức trực tiếp cao hơn đôi chút cho GLM-5-Turbo: $1.20 cho mỗi 1M token đầu vào và $4.00 cho mỗi 1M token đầu ra (giá cho input có cache thấp hơn).
GLM-5-Turbo vs GLM-5 — đối chiếu song song
Ở mức cao:
- GLM-5 = mô hình nền tảng chủ lực mục đích chung (lập luận, lập trình, điểm chuẩn mạnh)
- GLM-5-Turbo = biến thể tối ưu cho tác tử của GLM-5 (tập trung vào quy trình dài, công cụ, ổn định)
GLM-5-Turbo không phải một kiến trúc hoàn toàn mới, mà là phiên bản chuyên biệt, tối ưu sản xuất của GLM-5 dành cho hệ tác tử như OpenClaw.
Định vị cốt lõi
| Model | Positioning |
|---|---|
| GLM-5 | LLM chủ lực mục đích chung (lập luận, lập trình, điểm chuẩn) |
| GLM-5-Turbo | Mô hình ưu tiên tác tử (tự động hóa, điều phối, sử dụng công cụ) |
👉 Nói đơn giản:
- Dùng GLM-5 → khi bạn muốn trí tuệ tối đa
- Dùng GLM-5-Turbo → khi bạn muốn tự động hóa/tác tử ổn định
So sánh năng lực tác tử (QUAN TRỌNG NHẤT)
GLM-5 (năng lực tác tử), vốn đã hỗ trợ:
- Sử dụng công cụ
- Lập luận nhiều bước
- Tác tử lập trình
Nhưng có hạn chế:
- Có thể mất ngữ cảnh trong chuỗi dài
- Gọi công cụ có thể suy giảm theo thời gian
- Cần nhiều logic điều phối hơn
GLM-5-Turbo được tối ưu rõ ràng cho tác tử:
Cải tiến chính:
- Độ tin cậy gọi công cụ ↑
- Phân rã tác vụ (lập kế hoạch) ↑
- Tính nhất quán chuỗi dài ↑
- Hỗ trợ thực thi liên tục ↑
Ví dụ cải thiện:
- Thực thi ổn định qua 10+ bước mà không mất ngữ cảnh
👉 Điều này là then chốt cho:
- Hệ thống kiểu AutoGPT
- Quy trình đa tác tử
- Tự động hóa SaaS
Tốc độ & hiệu quả
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inference speed | Vừa | Nhanh hơn |
| Throughput | Tiêu chuẩn | Cao hơn |
| Long-task latency | Có thể tăng | Được tối ưu |
GLM-5-Turbo được thiết kế để khắc phục một vấn đề thực tế của ngành:
Các mô hình lớn chậm lại hoặc hỏng trong những quy trình dài
So sánh giá
| Model | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo đắt hơn (~20% cao hơn)
Vì sao đắt hơn?
Vì mô hình cung cấp:
- Độ tin cậy điều phối tốt hơn
- Ổn định sản xuất cao hơn
- Tối ưu hóa riêng cho tác tử
👉 Trong doanh nghiệp:
- Bạn trả nhiều hơn mỗi token
- Nhưng giảm chi phí lỗi + số lần thử lại
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primary goal | Mô hình nền tảng chủ lực mục đích chung (năng lực rộng, lập trình/điểm chuẩn mạnh) | Mô hình nền tảng tối ưu cho tác tử/“OpenClaw”/lobster |
| Context window | (được báo cáo là lớn; GLM-5 tập trung ~200K (GLM-5 cũng hỗ trợ ngữ cảnh dài)) | 200,000 token (được tài liệu hóa). |
| Maximum output tokens | (lớn, phụ thuộc vào mô hình) | 128,000 token (được tài liệu hóa). |
| Notable benchmark scores | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (số liệu GLM-5 công bố). | Đánh giá nội bộ khẳng định cải thiện ổn định chuỗi dài và thông lượng cho quy trình tác tử; điểm chuẩn công khai độc lập đang chờ. |
| Modalities | Văn bản (chính), họ GLM có biến thể thị giác ở các mô hình “anh em” | Chỉ văn bản (theo tài liệu) — tối ưu cho tác tử dựa trên công cụ. |
| Recommended use cases | Rộng: chat, lập trình, lập luận, nội dung | Điều phối tác tử, gọi công cụ, tự động hóa tầm xa |
| Pricing | Giá GLM-5 hiện có (tùy gói) | Ra mắt mới — báo cáo tăng ~20% giá API; giới thiệu các gói thuê bao Lobster |
Cách sử dụng GLM-5-Turbo
CometAPI — truy cập nhiều mô hình qua một API (tương thích OpenAI)
CometAPI liệt kê GLM-5-Turbo là khả dụng và cung cấp base URL cùng SDK tương thích OpenAI. Sử dụng chuỗi model mà họ công bố (trang của họ liệt kê GLM-5-Turbo với mức giá tương tự). Ví dụ dựa trên tài liệu CometAPI:
curl (CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
Giá trị của CometAPI nằm ở sự tiện lợi của bộ tổng hợp (một lần tích hợp cho nhiều mô hình). Xác nhận chính xác “model slug” trong bảng điều khiển CometAPI trước khi gọi.
Thực tiễn tốt nhất khi xây dựng tác tử Lobster / OpenClaw với GLM-5-Turbo
- Thiết kế cho độ tin cậy, không phải độ trễ thô: Lợi thế của Turbo là tỷ lệ lỗi gọi công cụ thấp trong chuỗi dài. Cấu trúc chạy tác tử để ưu tiên hoàn tất vững chắc (thử lại, gọi công cụ có tính idempotent) hơn là vài mili-giây token đầu.
- Dùng streaming & gọi công cụ theo từng phần: Tận dụng streaming/đầu ra theo khối để giảm làm lại và cho phép gọi công cụ sớm khi phù hợp. GLM-5-Turbo hỗ trợ streaming.
- Đầu ra có cấu trúc cho bộ phân tích: Ưu tiên JSON hoặc định dạng chặt chẽ để công cụ hạ nguồn phân tích quyết định hơn. Turbo hỗ trợ đầu ra có cấu trúc.
- Lập kế hoạch cho việc lên lịch/duy trì: Nếu tác tử của bạn cần kiểm tra định kỳ hoặc chạy nền, dùng ngữ nghĩa thời gian và tính năng bộ nhớ đệm của Turbo để tránh phải lập kế hoạch lại mỗi chu kỳ.
- Gắn đo đạc gọi công cụ & phương án dự phòng: Ghi nhật ký các lần gọi công cụ và thiết kế dự phòng linh hoạt (ví dụ: thử lại với nhiệt độ hơi khác hoặc gọi một công cụ dự phòng) vì quy trình tác tử rất mong manh nếu một API bên ngoài hỏng. Turbo giảm tỷ lệ lỗi nhưng không loại bỏ lỗi từ bên ngoài
Các nhà phát triển có thể truy cập API GLM-5 và GLM-5 turbo qua CometAPI ngay bây giờ. Để bắt đầu, hãy xem API guide để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập CometAPI và lấy API key. CometAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.
Sẵn sàng bắt đầu?→ Đăng ký GLM-5 và GLM-5 turbo ngay hôm nay !