

Bắt đầu với Gemini 2.5 Flash-Lite thông qua CometAPI là một cơ hội thú vị để khai thác một trong những mô hình AI tạo ra có độ trễ thấp, hiệu quả về chi phí nhất hiện nay. Hướng dẫn này kết hợp các thông báo mới nhất từ Google DeepMind, thông số kỹ thuật chi tiết từ tài liệu Vertex AI và các bước tích hợp thực tế bằng CometAPI để giúp bạn bắt đầu và chạy nhanh chóng và hiệu quả.
Gemini 2.5 Flash-Lite là gì và tại sao bạn nên cân nhắc sử dụng nó?
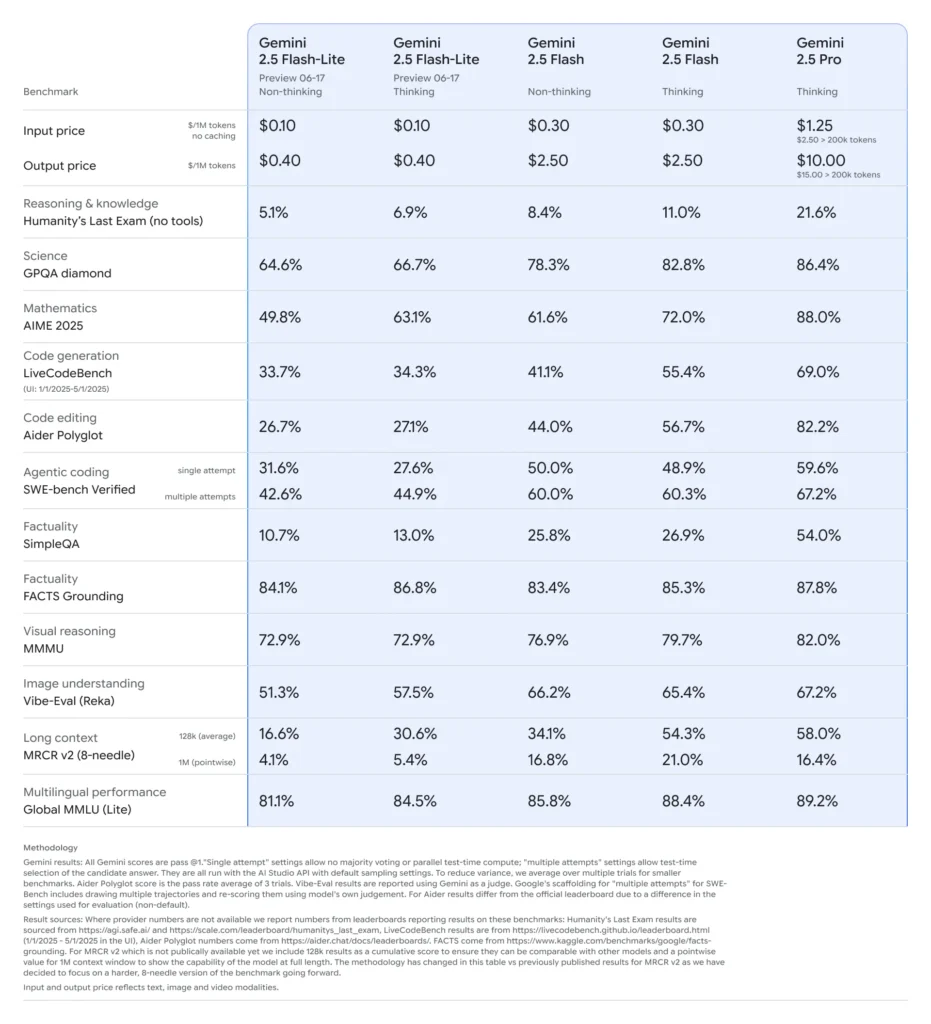
Tổng quan về gia đình Gemini 2.5
Vào giữa tháng 2025 năm 2.5, Google DeepMind chính thức phát hành dòng Gemini 2.5, bao gồm các phiên bản GA ổn định của Gemini 2.5 Pro và Gemini 2.5 Flash, cùng với bản xem trước của một mô hình hoàn toàn mới, nhẹ: Gemini 2.5 Flash-Lite. Được thiết kế để cân bằng tốc độ, chi phí và hiệu suất, dòng XNUMX đại diện cho nỗ lực của Google nhằm đáp ứng nhiều trường hợp sử dụng khác nhau—từ khối lượng công việc nghiên cứu nặng đến các triển khai quy mô lớn, nhạy cảm với chi phí.
Đặc điểm chính của Flash-Lite
Flash-Lite tạo nên sự khác biệt bằng cách cung cấp các khả năng đa phương thức (văn bản, hình ảnh, âm thanh, video) với độ trễ cực thấp, với cửa sổ ngữ cảnh hỗ trợ tới một triệu mã thông báo và tích hợp công cụ bao gồm Google Search, thực thi mã và gọi hàm. Quan trọng là Flash-Lite giới thiệu khả năng kiểm soát “ngân sách suy nghĩ”, cho phép các nhà phát triển cân bằng giữa chiều sâu lý luận với thời gian phản hồi và chi phí bằng cách điều chỉnh tham số ngân sách mã thông báo nội bộ.
Vị trí trong đội hình mẫu
Khi so sánh với các phiên bản cùng loại, Flash-Lite nằm ở ranh giới Pareto về hiệu quả chi phí: có giá khoảng 0.10 đô la cho một triệu mã thông báo đầu vào và 0.40 đô la cho một triệu mã thông báo đầu ra trong quá trình xem trước, nó làm giảm giá trị của cả Flash (ở mức 0.30 đô la/2.50 đô la) và Pro (ở mức 1.25 đô la/10 đô la) trong khi vẫn giữ lại hầu hết khả năng đa phương thức và hỗ trợ gọi hàm của chúng. Điều này làm cho Flash-Lite trở nên lý tưởng cho các tác vụ khối lượng lớn, độ phức tạp thấp như tóm tắt, phân loại và các tác nhân đàm thoại nhẹ.
Tại sao các nhà phát triển nên cân nhắc Gemini 2.5 Flash-Lite?
Tiêu chuẩn hiệu suất và thử nghiệm thực tế
Trong các so sánh trực tiếp, Flash-Lite đã chứng minh:
- Tốc độ truyền tải nhanh hơn 2 lần hơn Gemini 2.5 Flash trong các nhiệm vụ phân loại.
- Tiết kiệm chi phí gấp 3 lần để tóm tắt các quy trình ở quy mô doanh nghiệp.
- Độ chính xác cạnh tranh về logic, toán học và chuẩn mực mã, ngang bằng hoặc vượt trội hơn các bản xem trước Flash-Lite trước đó.
Các trường hợp sử dụng lý tưởng
- Chatbot khối lượng lớn: Mang lại trải nghiệm đàm thoại nhất quán, độ trễ thấp cho hàng triệu người dùng.
- Tạo nội dung tự động: Tóm tắt tài liệu, biên dịch và tạo bản sao nhỏ.
- Đường ống tìm kiếm và đề xuất: Tận dụng khả năng suy luận nhanh để cá nhân hóa theo thời gian thực.
- Xử lý dữ liệu hàng loạt: Chú thích các tập dữ liệu lớn với chi phí tính toán tối thiểu.
Làm thế nào để có được và quản lý quyền truy cập API cho Gemini 2.5 Flash-Lite thông qua CometAPI?
Tại sao nên sử dụng CometAPI làm cổng kết nối của bạn?
CometAPI tổng hợp hơn 500 mô hình AI—bao gồm cả loạt Gemini của Google—dưới một điểm cuối REST thống nhất, đơn giản hóa việc xác thực, giới hạn tỷ lệ và thanh toán giữa các nhà cung cấp. Thay vì phải xử lý nhiều URL cơ sở và khóa API, bạn chỉ định tất cả các yêu cầu đến https://api.cometapi.com/v1, chỉ định mô hình mục tiêu trong tải trọng và quản lý việc sử dụng thông qua một bảng điều khiển duy nhất.
Điều kiện tiên quyết và đăng ký
- Đăng nhập vào " cometapi.com. Nếu bạn chưa phải là người dùng của chúng tôi, vui lòng đăng ký trước
- Nhận khóa API thông tin xác thực truy cập của giao diện. Nhấp vào “Thêm mã thông báo” tại mã thông báo API trong trung tâm cá nhân, nhận khóa mã thông báo: sk-xxxxx và gửi.
- Lấy url của trang web này: https://api.cometapi.com/
Quản lý mã thông báo và hạn ngạch của bạn
Bảng điều khiển của CometAPI cung cấp hạn ngạch mã thông báo thống nhất có thể được chia sẻ trên Google, OpenAI, Anthropic và các mô hình khác. Sử dụng các công cụ giám sát tích hợp để đặt cảnh báo sử dụng và giới hạn tỷ lệ để bạn không bao giờ vượt quá phân bổ theo ngân sách hoặc phải chịu các khoản phí bất ngờ.
Bạn cấu hình môi trường phát triển của mình như thế nào để tích hợp CometAPI?
Cài đặt các phụ thuộc cần thiết
Để tích hợp Python, hãy cài đặt các gói sau:
pip install openai requests pillow
- openai: SDK tương thích để giao tiếp với CometAPI.
- yêu cầu: Dành cho các hoạt động HTTP như tải xuống hình ảnh.
- cái gối: Để xử lý hình ảnh khi gửi dữ liệu đầu vào đa phương thức.
Khởi tạo máy khách CometAPI
Sử dụng biến môi trường để giữ khóa API của bạn ngoài mã nguồn:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Phiên bản máy khách này hiện có thể nhắm mục tiêu vào bất kỳ mô hình được hỗ trợ nào bằng cách chỉ định ID của nó (ví dụ: gemini-2.5-flash-lite-preview-06-17) trong yêu cầu của bạn.
Cấu hình ngân sách suy nghĩ và các thông số khác
Khi bạn gửi yêu cầu, bạn có thể bao gồm các tham số tùy chọn:
- nhiệt độ/top_p: Kiểm soát tính ngẫu nhiên trong quá trình tạo.
- ứng cử viênSố lượng: Số lượng đầu ra thay thế.
- max_tokens: Giới hạn mã thông báo đầu ra.
- ngân sách_suy nghĩ: Tham số tùy chỉnh cho Flash-Lite để đánh đổi độ sâu lấy tốc độ và chi phí.
Yêu cầu cơ bản tới Gemini 2.5 Flash-Lite thông qua CometAPI trông như thế nào?
Ví dụ chỉ có văn bản
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Cuộc gọi này trả về bản tóm tắt ngắn gọn trong vòng dưới 200 ms, lý tưởng cho các chatbot hoặc quy trình phân tích thời gian thực.
Ví dụ đầu vào đa phương thức
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite xử lý hình ảnh có dung lượng lên tới 7 MB và trả về mô tả theo ngữ cảnh, phù hợp để hiểu tài liệu, phân tích UI và báo cáo tự động.
Làm thế nào bạn có thể tận dụng các tính năng nâng cao như phát trực tuyến và gọi hàm?
Phản hồi trực tuyến cho các ứng dụng thời gian thực
Đối với giao diện chatbot hoặc phụ đề trực tiếp, hãy sử dụng API phát trực tuyến:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Điều này cung cấp các đầu ra một phần khi chúng có sẵn, giúp giảm độ trễ nhận biết trong giao diện người dùng tương tác.
Gọi hàm để xuất dữ liệu có cấu trúc
Xác định lược đồ JSON để thực thi phản hồi có cấu trúc:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Cách tiếp cận này đảm bảo đầu ra tuân thủ JSON, đơn giản hóa các đường truyền dữ liệu và tích hợp hạ nguồn.
Làm thế nào để tối ưu hóa hiệu suất, chi phí và độ tin cậy khi sử dụng Gemini 2.5 Flash-Lite?
Suy nghĩ điều chỉnh ngân sách
Tham số ngân sách suy nghĩ của Flash-Lite cho phép bạn quay số lượng "nỗ lực nhận thức" mà mô hình chi tiêu. Ngân sách thấp (ví dụ: 0) ưu tiên tốc độ và chi phí, trong khi các giá trị cao hơn mang lại lý luận sâu sắc hơn với cái giá phải trả là độ trễ và mã thông báo.
Quản lý giới hạn mã thông báo và thông lượng
- Mã thông báo đầu vào: Tối đa 1,048,576 mã thông báo cho mỗi yêu cầu.
- Mã thông báo đầu ra: Giới hạn mặc định là 65,536 mã thông báo.
- Đầu vào đa phương thức: Tối đa 500 MB cho các nội dung hình ảnh, âm thanh và video.
Triển khai xử lý theo lô phía máy khách cho khối lượng công việc lớn và tận dụng khả năng tự động mở rộng của CometAPI để xử lý lưu lượng truy cập lớn mà không cần can thiệp thủ công.
Chiến lược tiết kiệm chi phí
- Gộp các tác vụ ít phức tạp vào Flash-Lite trong khi giữ lại Flash Pro hoặc Flash tiêu chuẩn cho các tác vụ nặng.
- Sử dụng giới hạn tỷ lệ và cảnh báo ngân sách trong bảng điều khiển CometAPI để ngăn chặn chi tiêu vượt mức.
- Theo dõi mức sử dụng theo ID mô hình để so sánh chi phí cho mỗi yêu cầu và điều chỉnh logic định tuyến của bạn cho phù hợp.
Những biện pháp thực hành tốt nhất và các bước tiếp theo sau khi tích hợp ban đầu là gì?
Giám sát, ghi nhật ký và bảo mật
- Logging: Ghi lại siêu dữ liệu yêu cầu/phản hồi (dấu thời gian, độ trễ, cách sử dụng mã thông báo) để kiểm tra hiệu suất.
- Cảnh báo: Thiết lập ngưỡng thông báo cho tỷ lệ lỗi hoặc chi phí vượt mức trong CometAPI.
- Bảo mật : Xoay vòng khóa API thường xuyên và lưu trữ chúng trong kho lưu trữ an toàn hoặc biến môi trường.
Mẫu sử dụng phổ biến
- Chatbots: Sử dụng Flash-Lite để người dùng truy vấn nhanh và chuyển sang Pro để theo dõi phức tạp.
- Xử lý tài liệu: Phân tích hàng loạt PDF hoặc hình ảnh qua đêm với mức ngân sách thấp hơn.
- Phân tích theo thời gian thực: Truyền dữ liệu tài chính hoặc hoạt động để có thông tin chi tiết tức thời thông qua API truyền phát.
Khám phá thêm
- Thử nghiệm với lời nhắc kết hợp: kết hợp đầu vào văn bản và hình ảnh để có bối cảnh phong phú hơn.
- Nguyên mẫu RAG (Thế hệ tăng cường truy xuất) bằng cách tích hợp các công cụ tìm kiếm vectơ với Gemini 2.5 Flash-Lite.
- So sánh với các sản phẩm của đối thủ cạnh tranh (ví dụ: GPT-4.1, Claude Sonnet 4) để xác thực sự đánh đổi về chi phí và hiệu suất.
Mở rộng quy mô sản xuất
- Tận dụng gói doanh nghiệp của CometAPI để có nhóm hạn ngạch chuyên dụng và đảm bảo SLA.
- Triển khai các chiến lược triển khai xanh để thử nghiệm lời nhắc hoặc ngân sách mới mà không làm gián đoạn người dùng trực tiếp.
- Thường xuyên xem xét số liệu sử dụng mô hình để xác định cơ hội tiết kiệm chi phí hoặc cải thiện chất lượng hơn nữa.
Bắt đầu
CometAPI cung cấp giao diện REST thống nhất tổng hợp hàng trăm mô hình AI—dưới một điểm cuối nhất quán, với quản lý khóa API tích hợp, hạn ngạch sử dụng và bảng điều khiển thanh toán. Thay vì phải xử lý nhiều URL và thông tin xác thực của nhà cung cấp.
Các nhà phát triển có thể truy cập Gemini 2.5 Flash-Lite (xem trước) API(Người mẫu: gemini-2.5-flash-lite-preview-06-17) xuyên qua Sao chổiAPI, các mô hình mới nhất được liệt kê là tính đến ngày xuất bản bài viết. Để bắt đầu, hãy khám phá khả năng của mô hình trong Sân chơi và tham khảo ý kiến Hướng dẫn API để biết hướng dẫn chi tiết. Trước khi truy cập, vui lòng đảm bảo bạn đã đăng nhập vào CometAPI và lấy được khóa API. Sao chổiAPI cung cấp mức giá thấp hơn nhiều so với giá chính thức để giúp bạn tích hợp.
Chỉ trong vài bước, bạn có thể tích hợp Gemini 2.5 Flash-Lite thông qua CometAPI vào các ứng dụng của mình, mở khóa sự kết hợp mạnh mẽ giữa tốc độ, khả năng chi trả và trí thông minh đa phương thức. Bằng cách tuân theo các hướng dẫn ở trên—bao gồm thiết lập, yêu cầu cơ bản, tính năng nâng cao và tối ưu hóa—bạn sẽ có vị thế tốt để cung cấp trải nghiệm AI thế hệ tiếp theo cho người dùng của mình. Tương lai của AI hiệu quả về chi phí, thông lượng cao đã ở đây: hãy bắt đầu với Gemini 2.5 Flash-Lite ngay hôm nay.