

GLM-5-Turbo 是 Zhipu AI 推出的新一代基礎大型語言模型,專門針對代理(agent)風格的工作流進行訓練與調校(該公司將目標生態系稱為 OpenClaw /「龍蝦」場景)。它提供超長上下文(最高約 200K tokens)、支援串流與結構化輸出、更低的工具呼叫錯誤率(第三方測試報告約 0.67%),以及顯著更低的每 token 價格。該模型的設計取捨是以略微降低單輪峰值吞吐量,換取在穩定性、工具可靠性、排程/持久任務處理與長鏈式執行方面的顯著提升——這對自主代理、編排系統與多工具管線尤為實用。
什麼是 GLM-5-Turbo?
GLM-5-Turbo 被 Zhipu 定位為一款為代理編排與複雜自動化工作流而生的基礎模型,而非通用聊天或多模態模型。其設計重點包括:
- 原生對代理友好的訓練(工具使用、指令遵循、定時/持久任務)
- 超大上下文視窗與輸出能力,支援長會話、記憶與思維鏈規劃
- 面向長業務流程與排程任務的穩定、高吞吐推理
與傳統為聊天或文本生成最佳化的 LLM 不同,GLM-5-Turbo 的特點是:
- 以代理為先(非以聊天為先)
- 為 OpenClaw(「龍蝦」)環境打造
- 專為多步自主工作流設計
🦞 「Lobster Agent」是什麼意思?
「龍蝦」概念指的是 OpenClaw,Zhipu 的 AI 代理生態系統,在此生態中,模型可以:
- 動態使用工具
- 執行長鏈任務
- 維持持久記憶
- 橫跨終端、應用與 API 運作
GLM-5-Turbo 深度優化於這一範式,重點解決代理中的關鍵問題,例如:
- 工具呼叫可靠性
- 任務分解
- 長期規劃
- 執行穩定性
主要特性與價值
長上下文 + 巨量輸出能力(200K / 128K)
200K token 的上下文視窗與 128K 的輸出上限,使 GLM-5-Turbo 能夠:
- 保持對先前上下文(對話、工具輸出、中間結果)的延展記憶
- 生成超長內容產物(多階段計畫、長報告、代碼庫),無需反覆拼接上下文
- 支持需要保留完整執行歷史以便準確決策的多輪代理
這是面向代理的刻意技術選擇——代理不必將任務切分為短提示,而是能在數千輪對話或步驟中維持一致狀態。
將代理原語融入訓練
GLM-5-Turbo 並非將通用模型事後改造成適合代理的模型,而是直接以代理風格目標(例如工具調用行為、指令/參數解析)進行訓練。據稱效果是:在工具呼叫時更少幻覺、更穩定的多步規劃,以及長時間運行下更佳的延遲表現——在需要可靠串接多個外部 API 或工具的自動化場景中極具價值。
吞吐與執行穩定性
與通用大型模型相比,GLM-5-Turbo 變體在長業務流程中的執行穩定性與吞吐表現更佳——其宣傳語著重於「高吞吐執行」與「同級領先的回應穩定性」。這些對企業級代理部署尤為重要,因為任何一步失敗都可能導致整個管線中斷。獨立第三方基準仍在持續出現中。
GLM-5-Turbo 的基準數據
說明:Zhipu 已發布內部評估,學術/第三方針對 GLM-5 的基準也已存在。GLM-5-Turbo 為新發佈;社群的獨立基準跑分尚需時間。以下列出相對可佐證的已發布數據與背景。
GLM-5(參考)——代表性已公布指標
Zhipu 的 GLM-5(Turbo 的旗艦前身)在多項工程/工作流任務中表現突出,例如:
- SWE-bench Verified: 77.8(GLM-5 文檔中報告為開源模型領先分數)
- Terminal Bench 2.0: 56.2(報告為該分佈上的開源模型頂尖表現)
這些數字確立了 GLM-5 在軟體工程與執行任務中的高水準基線;GLM-5-Turbo 的定位是以略減對原始規模/參數的強調,換取更好的代理可靠性與吞吐。內部比較顯示,GLM-5-Turbo 的工具呼叫錯誤率約 0.67%,顯著低於對照組 GLM-5 供應商在 約 2.33% 至 6.41% 區間的結果。
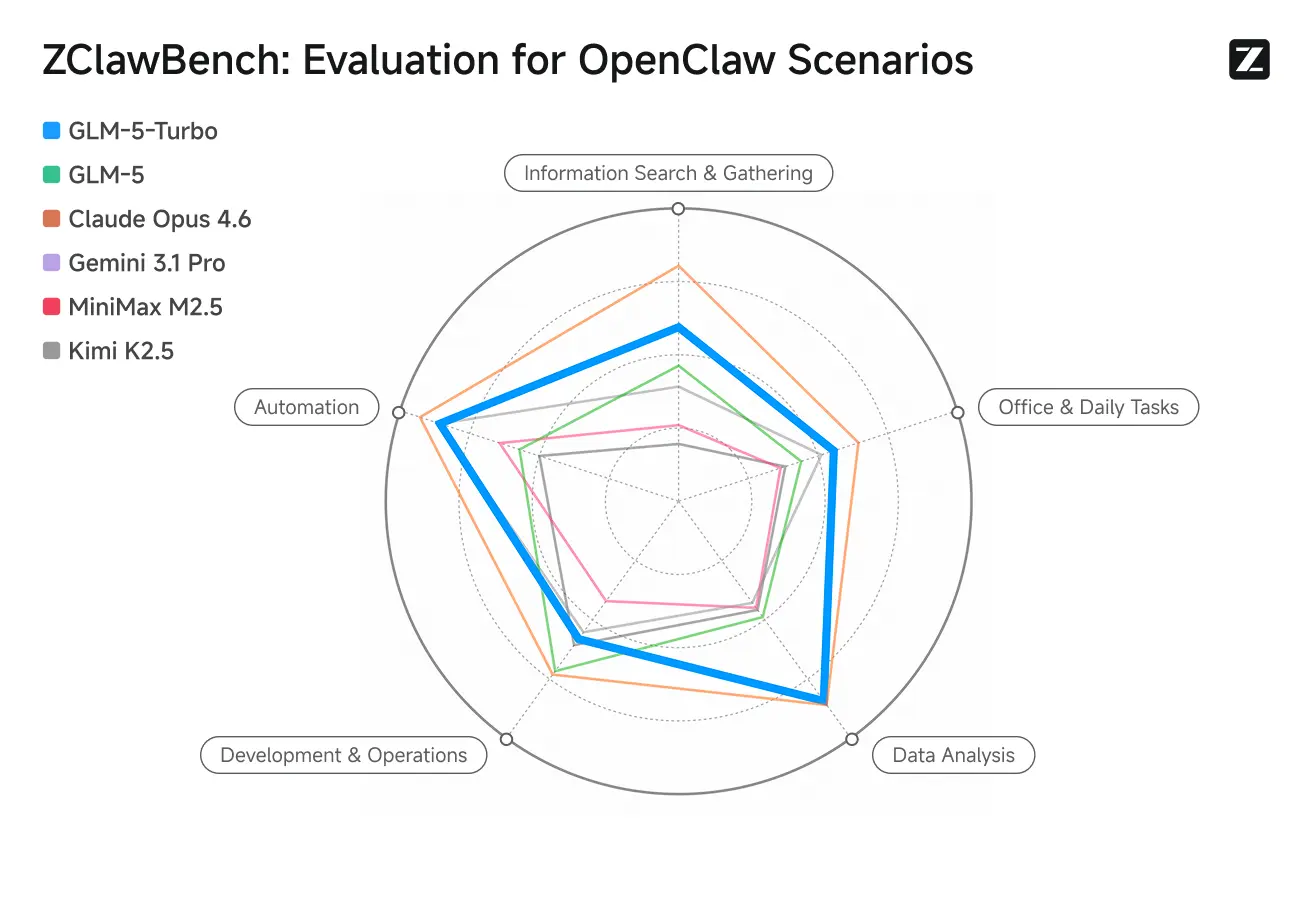
ZClawBench:OpenClaw 代理場景的基準測試
Zhipu 亦發布了用於評估智能代理的 ZClawBench 基準。在涵蓋程式開發、數據分析、內容創作等多領域的盲測中,新模型代號 Pony-Alpha-2 獲得了 90% 受試者的青睞。
價格與供應(誰提供、多少費用)
Zhipu 在 GLM-5-Turbo 發佈時對 API 定價實施了約 20% 上調,同時推出「Lobster Package」訂閱方案,以平滑代理部署中的 token 價格。
已報導的訂閱層級(示例方案)
兩個示例性的 Lobster 套餐(價格為換算後的近似值):
- 入門 Lobster 計劃: 約 39 CNY / 月(約 US$5.66),含 35,000,000 tokens
- 中階 Lobster 計劃: 約 99 CNY / 月(約 US$14.36),含 100,000,000 tokens
按上述公佈的訂閱費用與 token 上限換算,每 100 萬 tokens 的成本約為:
- 入門計劃:約 US$0.162 / 100 萬 tokens
- 中階計劃:約 US$0.144 / 100 萬 tokens
以上每 100 萬的數字為基於已公佈之訂閱費用與 token 額度的簡單換算,旨在說明高吞吐代理工作負載的經濟性(基於媒體所報導之匯率與數量計算)。
API 價格
代表性市場平台(CometAPI)的標價:每 100 萬輸入 tokens US$0.96、每 100 萬輸出 tokens US$3.20(機型為 GLM-5-Turbo)。
Zhipu 自家(Z.ai)開發者定價頁面列出的 GLM-5-Turbo 直連價格略高:每 100 萬輸入 tokens US$1.20、每 100 萬輸出 tokens US$4.00(緩存輸入費率更低)。
GLM-5-Turbo 與 GLM-5 —— 並排比較
概覽層面:
- GLM-5 = 旗艦通用型基礎模型(強推理、程式能力、基準表現)
- GLM-5-Turbo = 面向代理最佳化的 GLM-5 變體(聚焦長工作流、工具使用、穩定性)
GLM-5-Turbo 並非全新架構,而是面向代理系統(如 OpenClaw)的專門化、產品級最佳化版本。
核心定位
| Model | Positioning |
|---|---|
| GLM-5 | General-purpose flagship LLM (reasoning, coding, benchmarks) |
| GLM-5-Turbo | Agent-first model (automation, orchestration, tool usage) |
👉 簡而言之:
- 使用 GLM-5 → 當你需要最大化智能
- 使用 GLM-5-Turbo → 當你需要穩定的自動化/代理
代理能力對比(最重要)
GLM-5(代理能力)已支援:
- 工具使用
- 多步推理
- 程式代理
但局限在於:
- 在長鏈中可能丟失上下文
- 工具呼叫表現會隨時間衰減
- 需要更多編排邏輯
GLM-5-Turbo 則是明確為代理最佳化:
關鍵改進:
- 工具呼叫可靠性 ↑
- 任務分解(規劃)↑
- 長鏈一致性 ↑
- 持續執行支援 ↑
示例改進:
- 在 10+ 步的流程中仍能穩定執行且不丟失上下文
👉 這對以下場景至關重要:
- 類 AutoGPT 系統
- 多代理工作流
- SaaS 自動化
速度與效率
| Aspect | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Inference speed | Moderate | Faster |
| Throughput | Standard | Higher |
| Long-task latency | Can degrade | Optimized |
GLM-5-Turbo 致力於解決真實產業痛點:
大模型在長工作流中會變慢或中斷
定價比較
| Model | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| GLM-5 | ~$1.00 | ~$3.20 |
| GLM-5-Turbo | ~$1.20 | ~$4.00 |
👉 GLM-5-Turbo 更昂貴(約高 20%)
為何更昂貴?
因為它提供:
- 更佳的編排可靠性
- 更高的生產穩定性
- 面向代理的專屬最佳化
👉 對企業而言:
- 你為每個 token 支付更多
- 但可降低失敗成本與重試開銷
| Attribute | GLM-5 | GLM-5-Turbo |
|---|---|---|
| Primary goal | General flagship foundation model (broad capabilities, strong coding/benchmarks) | Agent/“OpenClaw” / lobster-optimized foundation model |
| Context window | (reported high; GLM-5 focuses ~200K (GLM-5 also supports long context) | 200,000 tokens (explicitly documented). |
| Maximum output tokens | (large, model dependent) | 128,000 tokens (documented). |
| Notable benchmark scores | SWE-bench: 77.8; Terminal Bench 2.0: 56.2 (GLM-5 reported numbers). | Internal evaluations claim improved long-chain stability and throughput for agent workflows; independent public benchmarks pending. |
| Modalities | Text (primary), GLM family has vision variants in sibling models | Text only (per docs) — optimized for tool-based agents. |
| Recommended use cases | Broad: chat, code, reasoning, content | Agent orchestration, tool invocation, long-horizon automation |
| Pricing | Existing GLM-5 pricing (varied by plan) | New launch — reported ~20% API price increase; new Lobster subscription tiers introduced |
如何使用 GLM-5-Turbo
CometAPI——單一 API 接入多家模型(與 OpenAI 相容)
CometAPI 已上架 GLM-5-Turbo,並提供與 OpenAI 相容的基礎 URL 與 SDK。請使用其發布的模型字串(其網站列示 GLM-5-Turbo,定價相近)。以下為依 CometAPI 文檔改寫的示例:
curl(CometAPI):
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer YOUR_COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "z-glm-5-turbo", // or use the exact model slug shown in CometAPI UI "messages": [{"role":"user","content":"Create a 5-step checklist for onboarding a new hire."}], "max_tokens": 800 }'
CometAPI 的價值在於聚合便利性(一次整合,多模型可用)。在調用前請於 CometAPI 控制台確認實際模型代號。
使用 GLM-5-Turbo 構建 Lobster / OpenClaw 代理的最佳實踐
- 優先設計可靠性,而非極致首 token 延遲: Turbo 的優勢在於長鏈中更低的工具呼叫失敗率。將代理運行結構化為偏好可靠完成(重試、具冪等性的工具呼叫),而非追求極小的首 token 時間。
- 使用串流與漸進式工具呼叫: 採用串流/分塊輸出以減少返工,並在合適時機提前觸發工具調用。GLM-5-Turbo 支援串流。
- 為解析器輸出結構化結果: 優先輸出 JSON 或良好格式,以便下游工具確定性解析。Turbo 支援結構化輸出。
- 規劃排程/持久化: 若代理需定期檢查或執行背景任務,利用 Turbo 更好的時間語義與緩存能力,避免每輪重新規劃。
- 監控工具調用與設計降級路徑: 記錄工具呼叫並設計優雅的回退機制(如調整 temperature 後重試,或調用備用工具),因為代理式工作流對單一外部 API 的失敗較脆弱。Turbo 降低錯誤率,但無法消除外部故障。
開發者可立即透過 CometAPI 使用 GLM-5 與 GLM-5 turbo API。開始之前,請參考API 指南以獲取詳細說明。使用前請先登入 CometAPI 並取得 API Key。CometAPI 提供遠低於官方的價格,助你快速整合。
Ready to Go?→ 立即註冊 GLM-5 和 GLM-5 turbo!