GLM-4.6 es el último lanzamiento mayor en la familia GLM de Z.ai (antes Zhipu AI): un modelo MoE (Mezcla de expertos) de cuarta generación, de gran tamaño, ajustado para flujos de trabajo agentivos, razonamiento de contexto largo y codificación en el mundo real. La versión enfatiza la integración práctica de agentes/herramientas, una ventana de contexto muy grande y la disponibilidad de pesos abiertos para despliegue local.
Características clave
- Contexto largo — ventana de contexto nativa de 200K tokens (ampliada desde 128K). (docs.z.ai)
- Codificación y capacidad agentiva — mejoras anunciadas en tareas de codificación del mundo real y mejor invocación de herramientas para agentes.
- Eficiencia — se informa de ~30% menos consumo de tokens frente a GLM-4.5 en las pruebas de Z.ai.
- Despliegue y cuantización — primera integración anunciada de FP8 e Int4 para chips Cambricon; compatibilidad nativa con FP8 en Moore Threads mediante vLLM.
- Tamaño del modelo y tipo de tensor — los artefactos publicados indican un modelo de ~357B parámetros (tensores BF16 / F32) en Hugging Face.
Detalles técnicos
Modalidades y formatos. GLM-4.6 es un LLM solo de texto (modalidades de entrada y salida: texto). Longitud de contexto = 200K tokens; salida máxima = 128K tokens.
Cuantización y compatibilidad con hardware. El equipo informa cuantización FP8/Int4 en chips Cambricon y ejecución FP8 nativa en GPUs Moore Threads usando vLLM para inferencia — importante para reducir el coste de inferencia y permitir despliegues on-prem y en nubes domésticas.
Herramientas e integraciones. GLM-4.6 se distribuye a través de la API de Z.ai, redes de proveedores de terceros (p. ej., CometAPI), e integrado en agentes de codificación (Claude Code, Cline, Roo Code, Kilo Code).
Detalles técnicos
Modalidades y formatos. GLM-4.6 es un LLM solo de texto (modalidades de entrada y salida: texto). Longitud de contexto = 200K tokens; salida máxima = 128K tokens.
Cuantización y compatibilidad con hardware. El equipo informa cuantización FP8/Int4 en chips Cambricon y ejecución FP8 nativa en GPUs Moore Threads usando vLLM para inferencia — importante para reducir el coste de inferencia y permitir despliegues on-prem y en nubes domésticas.
Herramientas e integraciones. GLM-4.6 se distribuye a través de la API de Z.ai, redes de proveedores de terceros (p. ej., CometAPI), e integrado en agentes de codificación (Claude Code, Cline, Roo Code, Kilo Code).
Rendimiento en benchmarks
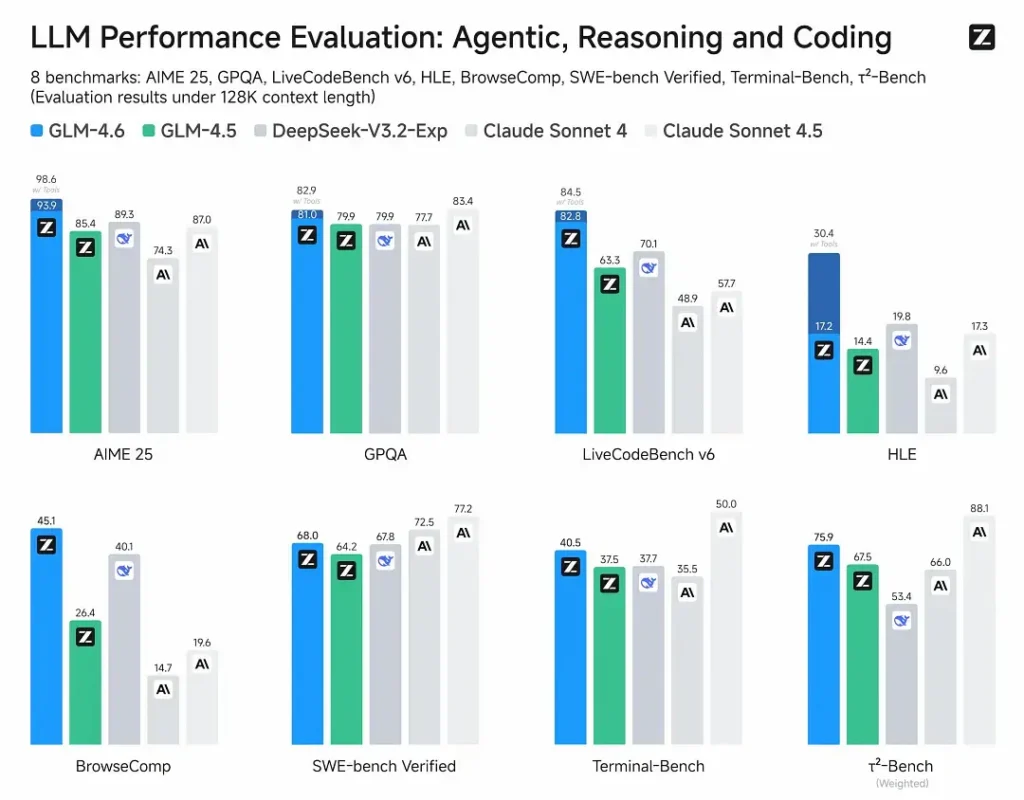
- Evaluaciones publicadas: GLM-4.6 se probó en ocho benchmarks públicos que abarcan agentes, razonamiento y codificación y muestra mejoras claras frente a GLM-4.5. En pruebas de codificación del mundo real evaluadas por humanos (CC-Bench ampliado), GLM-4.6 utiliza ~15% menos tokens frente a GLM-4.5 y registra una tasa de victoria de ~48.6% frente a Claude Sonnet 4 de Anthropic (casi paridad en muchas tablas de clasificación).
- Posicionamiento: los resultados afirman que GLM-4.6 es competitivo con modelos líderes nacionales e internacionales (los ejemplos citados incluyen DeepSeek-V3.1 y Claude Sonnet 4).
Limitaciones y riesgos
- Alucinaciones y errores: como todos los LLM actuales, GLM-4.6 puede y de hecho comete errores fácticos — la documentación de Z.ai advierte explícitamente que las salidas pueden contener errores. Los usuarios deben aplicar verificación y recuperación/RAG para contenido crítico.
- Complejidad del modelo y coste de servicio: el contexto de 200K y salidas muy grandes aumentan drásticamente las exigencias de memoria y latencia y pueden elevar los costes de inferencia; se requiere ingeniería de cuantización/inferencia para operar a escala.
- Brechas de dominio: aunque GLM-4.6 informa de un sólido rendimiento en agentes/codificación, algunos informes públicos señalan que aún queda rezagado respecto a ciertas versiones de modelos competidores en microbenchmarks específicos (p. ej., algunas métricas de codificación frente a Sonnet 4.5). Evalúe por tarea antes de sustituir modelos en producción.
- Seguridad y políticas: los pesos abiertos aumentan la accesibilidad pero también plantean cuestiones de gobernanza (las mitigaciones, barreras de seguridad y red-teaming siguen siendo responsabilidad del usuario).
Casos de uso
- Sistemas agentivos y orquestación de herramientas: trazas largas de agentes, planificación con múltiples herramientas, invocación dinámica de herramientas; el ajuste agentivo del modelo es un punto de venta clave.
- Asistentes de codificación del mundo real: generación de código multi-turno, revisión de código y asistentes interactivos de IDE (integrados en Claude Code, Cline, Roo Code—según Z.ai). Las mejoras en eficiencia de tokens lo hacen atractivo para planes de desarrolladores de uso intensivo.
- Flujos de documentos largos: resumen, síntesis multidocumento, revisiones legales/técnicas extensas gracias a la ventana de 200K.
- Creación de contenido y personajes virtuales: diálogos prolongados, mantenimiento consistente de la persona en escenarios multi-turno.
Cómo se compara GLM-4.6 con otros modelos
- GLM-4.5 → GLM-4.6: cambio de nivel en tamaño de contexto (128K → 200K) y eficiencia de tokens (~15% menos tokens en CC-Bench); mejor uso de agentes/herramientas.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai informa de casi paridad en varias tablas de clasificación y una tasa de victoria de ~48.6% en las tareas de codificación del mundo real de CC-Bench (es decir, competencia cercana, con algunos microbenchmarks donde Sonnet aún lidera). Para muchos equipos de ingeniería, GLM-4.6 se posiciona como una alternativa rentable.
- GLM-4.6 vs otros modelos de largo contexto (DeepSeek, variantes de Gemini, familia GPT-4): GLM-4.6 enfatiza el gran contexto y los flujos de codificación agentivos; las fortalezas relativas dependen de la métrica (eficiencia de tokens/integración de agentes vs precisión de la síntesis de código en bruto o canalizaciones de seguridad). La selección empírica debe estar guiada por la tarea.
Zhipu AI’s latest flagship model GLM-4.6 released: 355B total params, 32B active. Surpasses GLM-4.5 in all core capabilities.
- Codificación: se alinea con Claude Sonnet 4, el mejor en China.
- Contexto: ampliado a 200K (desde 128K).
- Razonamiento: mejorado, admite llamadas a herramientas durante la inferencia.
- Búsqueda: llamadas a herramientas mejoradas y mejor rendimiento de agentes.
- Redacción: se alinea mejor con las preferencias humanas en estilo, legibilidad y juego de roles.
- Multilingüe: traducción entre idiomas mejorada.
