Specyfikacja techniczna GPT-5.4 Mini
| Pozycja | GPT-5.4 Mini (szacunki na podstawie oficjalnych informacji + walidacji krzyżowej) |
|---|---|
| Rodzina modeli | Seria GPT-5.4 (ekonomiczny wariant „mini”) |
| Dostawca | OpenAI |
| Typy wejścia | Tekst, obraz |
| Typy wyjścia | Tekst |
| Okno kontekstowe | 400 000 tokenów |
| Maks. liczba tokenów wyjściowych | 128 000 tokenów |
| Granica wiedzy | ~31 maja 2024 r. (dziedziczy linię mini) |
| Obsługa rozumowania | Tak (lekka wersja względem pełnego GPT-5.4) |
| Obsługa narzędzi | Wywoływanie funkcji, wyszukiwanie w sieci, wyszukiwanie plików, agenci (wnioskowane na podstawie rodziny GPT-5) |
| Pozycjonowanie | Szybki, ekonomiczny model bliski poziomowi frontier |
Czym jest GPT-5.4 Mini?
GPT-5.4 Mini to ekonomiczny, szybki wariant GPT-5.4, zaprojektowany z myślą o obciążeniach wrażliwych na opóźnienia i dużym wolumenie zapytań. Oferuje znaczną część możliwości GPT-5.4 w zakresie rozumowania, programowania i multimodalności w mniejszym, szybszym modelu zoptymalizowanym pod kątem systemów działających na skalę produkcyjną.
W porównaniu z wcześniejszymi modelami „mini”, GPT-5.4 Mini jest pozycjonowany jako mały model bliski poziomowi frontier, co oznacza, że zbliża się do wydajności modeli flagowych, jednocześnie znacząco obniżając koszt i czas odpowiedzi.
Kluczowe cechy GPT-5.4 Mini
- Szybkie wnioskowanie: zoptymalizowany pod kątem aplikacji o niskich opóźnieniach, takich jak chatboty, copiloci i systemy czasu rzeczywistego
- Duże okno kontekstowe (400K): obsługuje długie dokumenty, wieloetapowe przepływy pracy i pamięć agentów
- Silne wsparcie dla kodowania i agentów: zaprojektowany do użycia narzędzi, wieloetapowego rozumowania i delegowanych zadań podagentów
- Wejście multimodalne: akceptuje zarówno dane tekstowe, jak i obrazy, co umożliwia bogatsze przepływy pracy
- Ekonomiczne skalowanie: znacznie tańszy niż GPT-5.4 przy zachowaniu silnych zdolności rozumowania
- Optymalizacja potoków agentowych: idealny do architektur wielomodelowych, w których duże modele planują, a modele mini wykonują zadania
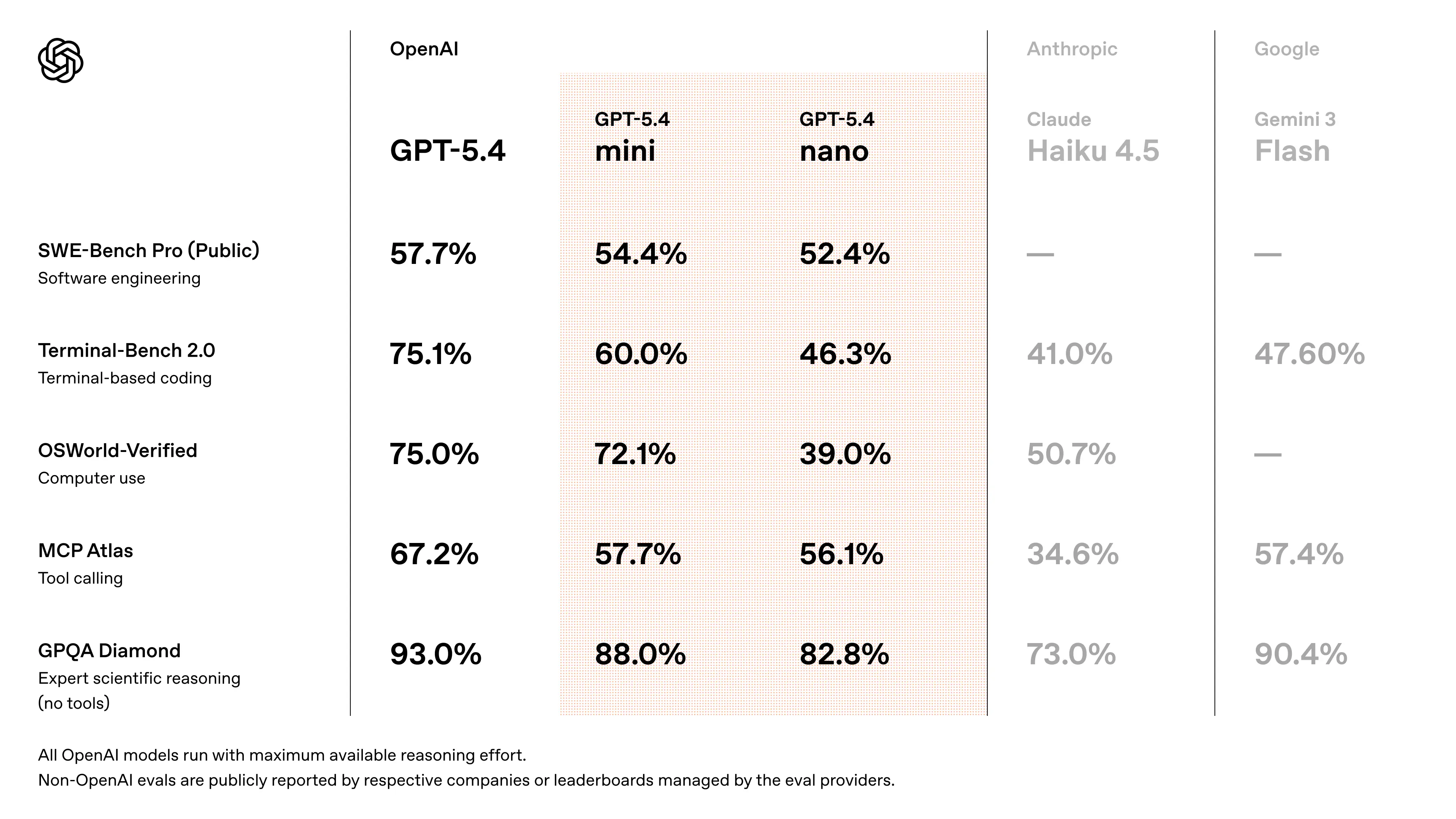
Wydajność benchmarkowa GPT-5.4 Mini
- Zbliża się do wydajności GPT-5.4 w zadaniach programistycznych w stylu SWE-Bench (~94–95% wydajności modelu flagowego) (szacunek zweryfikowany krzyżowo na podstawie dyskusji po premierze)
- Istotne ulepszenia względem GPT-5 Mini w zakresie:
- dokładności rozumowania
- niezawodności użycia narzędzi
- rozumienia multimodalnego
- Zaprojektowany tak, aby przewyższać wcześniejsze generacje „mini” w przepływach agentowych i benchmarkach kodowania
- pomiary szybkości: pierwsi testerzy API zgłaszają ~180–190 tokenów/s dla GPT-5.4 Mini (w porównaniu z ~55–120 t/s dla starszych wariantów GPT-5 mini, zależnie od trybów priorytetu).
👉 Kluczowy wniosek: GPT-5.4 Mini zapewnia wydajność bliską poziomowi frontier przy ułamku kosztu i opóźnienia, co czyni go idealnym rozwiązaniem dla skalowalnych systemów.
Reprezentatywne przypadki użycia
- Asystenci programowania i edytory (wtyczki IDE, Copilot): szybkie analizowanie kontekstu, eksploracja kodu i szybkie uzupełnienia sprawiają, że GPT-5.4 Mini idealnie nadaje się do sugestii bezpośrednio w edytorze, gdzie liczy się czas do pierwszego tokena. GitHub Copilot jest jedną z wczesnych integracji.
- Podagenci / delegowani pracownicy: w scenariuszach, w których agent nadrzędny deleguje krótkie, szybkie zadania (formatowanie, małe kroki rozumowania, wyszukiwania w stylu grep) do taniego i szybkiego wykonawcy. OpenAI pozycjonuje modele mini/nano do takich ról.
- Automatyzacja API o dużym wolumenie: masowe generowanie kodu, automatyczna klasyfikacja zgłoszeń, podsumowywanie logów na dużą skalę, gdzie koszt pojedynczego wywołania i opóźnienie są głównymi ograniczeniami. Dane społeczności dotyczące przepustowości wskazują na istotne korzyści operacyjne dla modeli mini.
- Opakowywanie narzędzi i łańcuchy narzędziowe: szybkie wywołania narzędzi, w których model orkiestruje wywołania zewnętrznych narzędzi (search, grep, uruchamianie testów) i zwraca zwięzłe, praktyczne wyniki. Rodzina GPT-5.4 obejmuje ulepszone możliwości „computer use”.
Jak uzyskać dostęp do API GPT-5.4 Mini
Krok 1: Zarejestruj się, aby uzyskać klucz API
Zaloguj się do cometapi.com. Jeśli nie jesteś jeszcze naszym użytkownikiem, najpierw się zarejestruj. Zaloguj się do swojej konsoli CometAPI. Uzyskaj poświadczenie dostępu w postaci klucza API interfejsu. Kliknij „Add Token” w sekcji tokenów API w centrum osobistym, uzyskaj klucz tokenu: sk-xxxxx i zatwierdź.

Krok 2: Wysyłaj żądania do API GPT-5.4 Mini
Wybierz endpoint „gpt-5.4-mini”, aby wysłać żądanie API, i ustaw treść żądania. Metoda żądania i treść żądania są dostępne w dokumentacji API na naszej stronie internetowej. Na naszej stronie dostępny jest również test Apifox dla Twojej wygody. Zastąp <YOUR_API_KEY> swoim rzeczywistym kluczem CometAPI z konta. Podstawowy adres URL to Chat Completions oraz Responses.
Wstaw swoje pytanie lub żądanie do pola content — to na nie model odpowie. Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź.
Krok 3: Pobierz i zweryfikuj wyniki
Przetwórz odpowiedź API, aby uzyskać wygenerowaną odpowiedź. Po przetworzeniu API zwraca status zadania oraz dane wyjściowe.