

In July 2025, Alibaba unveiled Qwen3-Coder, its most advanced open‑source AI model designed specifically for complex coding workflows and agentic programming tasks. This professional guide will walk you step by step through everything you need to know—from understanding its core capabilities and key innovations, to installing and using the accompanying Qwen Code CLI tool for automated, agent‑style coding. Along the way, you’ll learn best practices, troubleshooting tips, and how to optimize your prompts and resource allocation to get the most out of Qwen3‑Coder.
What is Qwen3‑Coder and why does it matter?
Alibaba’s Qwen3‑Coder is a 480 billion‑parameter Mixture‑of‑Experts (MoE) model with 35 billion active parameters, built to support large‑context coding tasks—natively handling 256 K tokens (and up to 1 M with extrapolation methods). Released on July 23, 2025, it represents a major leap in “agentic AI coding,” where the model not only generates code but can autonomously plan, debug, and iterate through complex programming challenges without manual intervention.
How does Qwen3‑Coder differ from its predecessors?
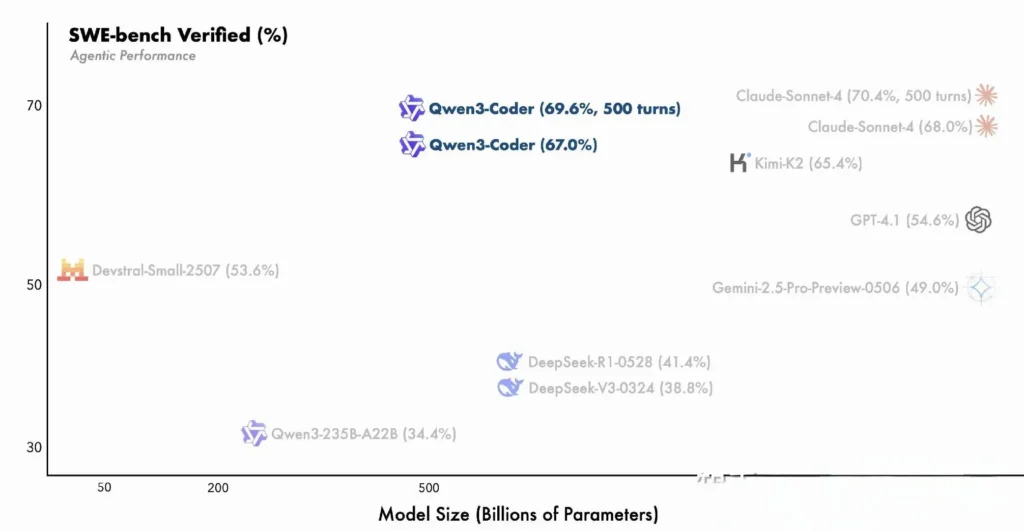
Qwen3‑Coder builds upon the Qwen3 family’s innovations—integrating both “thinking mode” for multi‑step reasoning and “non‑thinking mode” for rapid responses—into a single, unified framework that dynamically switches modes based on task complexity. Unlike Qwen2.5‑Coder, which was dense and capped at smaller contexts, Qwen3‑Coder employs sparse Mixture‑of‑Experts architecture to deliver state‑of‑the‑art performance on benchmarks such as SWE‑Bench Verified and CodeForces ELO ratings, matching or exceeding models like Anthropic’s Claude and OpenAI’s GPT‑4 in key coding metrics.
key features of Qwen3‑Coder:
- Massive Context Window: 256 K tokens natively, up to 1 M via extrapolation, enabling it to process entire codebases or long documentation in one pass.
- Agentic Capabilities: A dedicated “agent mode” that can autonomously plan, generate, test, and debug code, reducing manual engineering overhead.
- High Throughput & Efficiency: Mixture‑of‑Experts design activates only 35 billion parameters per inference, balancing performance with computational cost.
- Open‑Source & Extensible: Released under Apache 2.0, with fully documented APIs and community‑driven enhancements available on GitHub.
- Multi‑Language & Cross‑Domain: Trained on 7.5 trillion tokens (70% code) across dozens of programming languages, from Python and JavaScript to Go and Rust.
How can developers get started with Qwen3‑Coder?
Where can I download and install Qwen3‑Coder?
You can obtain the model weights and Docker images from:
- GitHub: https://github.com/QwenLM/Qwen3-Coder
- Hugging Face: https://huggingface.co/QwenLM/Qwen3-Coder-480B-A35B-Instruct
- ModelScope: Official Alibaba repository
Simply clone the repo and pull the prebuilt Docker container:
git clone https://github.com/QwenLM/Qwen3-Coder.git
cd Qwen3-Coder
docker pull qwenlm/qwen3-coder:latest
Loading the Model with Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Coder-480B-A35B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
This code initializes the model and tokenizer, automatically distributing layers across available GPUs .
How do I configure my environment?
- Hardware Requirements:
- NVIDIA GPUs with ≥ 48 GB VRAM (A100 80 GB recommended)
- 128–256 GB system RAM
-
Dependencies:
pip install -r requirements.txt # PyTorch, CUDA, tokenizers, etc. -
API Keys (Optional):
For cloud‑hosted inference, set yourALIYUN_ACCESS_KEYandALIYUN_SECRET_KEYas environment variables.
How do you use Qwen Code for agentic coding?
Here’s a step‑by‑step guide to getting up and running with Qwen3‑Coder via the Qwen Code CLI (invoked simply as qwen):
1. Prerequisites
- Node.js 20+ (you can install via the official installer or via the script below)
- npm, which comes bundled with Node.js
# (Linux/macOS)
curl -qL https://www.npmjs.com/install.sh | sh
2. Install the Qwen Code CLI
npm install -g @qwen-code/qwen-code
Alternatively, to install from source:
git clone https://github.com/QwenLM/qwen-code.git
cd qwen-code
npm install
npm install -g
3. Configure Your Environment
Qwen Code uses the OpenAI‑compatible API interface under the hood. Set the following environment variables:
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
OPENAI_MODEL can be set to one of:
qwen3-coder-plus(aliased to Qwen3‑Coder-480B-A35B-Instruct)- or any other Qwen3‑Coder variant you’ve deployed.
4. Basic Usage
1.Start an Interactive Coding REPL:
qwen
This drops you into an agentic coding session powered by Qwen3‑Coder.
- One‑off Prompt from Shell, To ask for a code snippet or complete a function:
qwen code complete \
--model qwen3-coder-plus \
--prompt "Write a Python function that reverses a linked list."
- File‑based Code Completion,Automatically fill in or refactor an existing file:
qwen code file-complete \
--model qwen3-coder-plus \
--file ./src/utils.js
- Chat‑style Interaction,Use Qwen in “chat” mode, ideal for multi‑turn coding dialogues:
qwen chat \
--model qwen3-coder-plus \
--system "You are a helpful coding assistant." \
--user "Generate a REST API endpoint in Express.js for user authentication."
How Do You Invoke Qwen3-Coder via CometAPI API?
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
If you are a cometAPI user, you can log in to cometapi to get the key and base url and log in to cometapi to obtain the key and base url,refer to Qwen3-Coder API.To begin, explore models’s capabilities in the Playground and consult the API guide for detailed instructions.
To call Qwen3‑Coder through CometAPI you use the same OpenAI‑compatible endpoints as for any other model—simply point your client at CometAPI’s base URL, present your CometAPI key as a Bearer token, and specify either the qwen3-coder-plus or qwen3-coder-480b-a35b-instruct model.
1. Prerequisites
- Sign up at https://cometapi.com and add/generate an API token in your dashboard.
- Note your API key (starts with
sk-…). - Familiarity with the OpenAI Chat API protocol (roles + messages).
2. Base URL & Authentication
Base URL:
arduinohttps://api.cometapi.com/v1
Endpoint:
bashPOST https://api.cometapi.com/v1/chat/completions
3. cURL / REST Example
curl https://api.cometapi.com/v1/chat/completions \
-H "Authorization: Bearer sk-xxxxxxxxxxxx" \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-coder-plus",
"messages": [
{ "role": "system", "content": "You are a helpful coder." },
{ "role": "user", "content": "Generate a SQL query to find duplicate emails." }
],
"temperature": 0.7,
"max_tokens": 512
}'
- Response: JSON with
choices.message.contentcontaining the generated code.
How do you leverage the agentic capabilities of Qwen3-Coder?
Qwen3-Coder’s agentic features enable dynamic tool invocation and autonomous multi‑step workflows, allowing the model to call external functions or APIs during code generation.
Tool invocation and custom tools
Define custom tools—such as linters, test runners, or formatters—in your codebase and expose them to the model via function schemas. For example:
tools = [
{"name":"run_tests","description":"Execute the test suite and return results","parameters":{}},
{"name":"format_code","description":"Apply black formatter to the code","parameters":{}}
]
response = client.chat.completions.create(
messages=,
functions=tools,
function_call="auto"
)
Qwen3-Coder can then autonomously generate, format, and validate code in one session, reducing manual integration overhead ().
Using Qwen Code CLI
The qwen-code command‑line tool offers an interactive REPL for agentic coding:
qwen-code --model qwen3-coder-480b-a35b-instruct
> generate: "Create a REST API in Node.js with JWT authentication."
> tool: install_package(express)
> tool: create_file(app.js)
> tool: run_tests
This CLI orchestrates complex workflows with transparent logs, making it ideal for exploratory prototyping or integrating into CI/CD pipelines.
Is Qwen3-Coder Suitable for Large Codebases?
Thanks to its extended context window, Qwen3-Coder can ingest entire repositories—up to hundreds of thousands of lines of code—before generating patches or refactorings. This capability enables global refactors, cross‑module analytics, and architectural suggestions that smaller‑context models simply cannot match.
What Are Best Practices for Maximizing Qwen3-Coder’s Utility?
Adopting Qwen3-Coder effectively requires thoughtful configuration and integration into your CI/CD pipeline.
How Should You Tune Sampling and Beam Settings?
- Temperature: 0.6–0.8 for balanced creativity; lower (0.2–0.4) for deterministic refactoring tasks.
- Top‑p: 0.7–0.9 to focus on the most probable continuations while allowing occasional novel suggestions.
- Top‑k: 20–50 for standard use; reduce to 5–10 when seeking highly focused outputs.
- Repetition Penalty: 1.05–1.1 to discourage the model from repeating boilerplate patterns.
Experimenting with these parameters in line with your project’s tolerance for variation can yield significant productivity gains .
What are the best practices for using Qwen3-Coder effectively?
Prompt Engineering for Code Quality
- Be Specific: Specify language, style guidelines, and desired complexity in your prompt.
- Iterative Refinement: Use the model’s agentic capabilities to iteratively debug and optimize generated code.
- Temperature Tuning: Lower the generation temperature (e.g.,
temperature=0.2) for more deterministic outputs in production contexts.
Managing Resource Utilization
- Model Variants: Start with smaller Qwen3-Coder variants for prototyping, then scale up as needed.
- Dynamic Quantization: Experiment with FP8 and GGUF quantized checkpoints to reduce GPU memory footprint without a significant performance drop .
- Asynchronous Generation: Offload long-running code generations to background workers to maintain responsiveness.
Adhering to these guidelines ensures you maximize the ROI of integrating Qwen3-Coder into your software development lifecycle.
By following the guidance above—understanding its architecture, installing and configuring both the model and Qwen Code CLI, and leveraging best practices—you’ll be well‑equipped to harness Qwen3‑Coder’s full potential for anything from simple code snippets to fully autonomous programming agents.