

As an AI creator, I’m excited to introduce you to Nano Banana — the playful nickname for Gemini 2.5 Flash Image — Google’s newest, high-fidelity image-generation and image-editing model. In this deep-dive I’ll explain what it is, how to use it (app and API), how to prompt it effectively, give concrete examples, include ready-to-run code, and walk through seven creative, practical uses you can start applying today.
What is Gemini 2.5 Flash Image (Nano Banana)?
Gemini 2.5 Flash Image is a new image generation and image-editing model in the Gemini family. It extends the Gemini 2.5 Flash family to produce and edit images (not just text), combining Gemini’s multi-modal reasoning, world knowledge and prompt-driven controls to create or alter images from text and/or image inputs. The team and the developer docs explicitly call it “Gemini 2.5 Flash Image” and note the internal nickname nano-banana.
At announcement the published pricing for the Gemini 2.5 Flash Image tier was $30 per 1M output tokens, with an example per-image cost reported as 1290 output tokens ≈ $0.039 per image. The model is offered in preview (developer/preview IDs like gemini-2.5-flash-image-preview) and is already available through selected partners (CometAPI) and Google’s own developer platforms.
What are the standout features of Gemini 2.5 Flash Image?
Character and style consistency across edits
One of the central improvements is character consistency: the model is explicitly tuned to keep a subject (a person, pet, or product) visually coherent across multiple edits and different contexts — a long-standing weakness of earlier image models. This improves workflows that require consistent brand assets, recurring characters in storytelling, or multi-shot product photography generated automatically.
Prompt-based, localized editing
You can supply an image plus a natural-language instruction such as “remove the stain on the shirt”, “change outfit to a blue jacket”, or “blur the background and increase brightness on the subject” and the model performs targeted, local edits without needing manual masks in many cases. This makes it practical for iterative, conversational editing.
Multi-image fusion & style transfer
Gemini 2.5 Flash Image can take several images and compose them into a single scene or transfer style/texture from one image to another. That enables product mockups (place a product into a scene), furniture staging, or combined imagery for marketing and e-commerce.
Native world knowledge
Because it’s built on the Gemini family, the model leverages world knowledge — e.g., understanding props, environments, or contextually correct object relationships — which helps with realistic scene construction and semantically coherent edits (not just aesthetically plausible outputs).
Low latency and cost efficiency
Gemini’s “Flash” family targets low latency and cost-efficient usage compared to larger reasoning tiers. The developer announcement emphasizes speed and a favorable price/quality tradeoff for many real-world use cases.
Built-in provenance: SynthID watermark
All images created/edited with the model include an invisible SynthID digital watermark so the images can be later verified as AI-generated or AI-edited. This is part of Google’s product-level mitigation for misuse and provenance tracking.
1) How can I create a consistent character for a long-running comic or brand campaign?
Why this works
Nano Banana was explicitly trained to maintain the same character appearance across edits and new contexts — useful when you need the same face, outfit, or mascot to appear across episodes, thumbnails, or hero images. The developers call this “character consistency.”
How to prompt
- Start with a descriptive block that captures identity features (age range, facial characteristics, distinctive marks, outfit elements).
- Add a “consistency token” instruction like “Use the same character across all outputs — do not change identifying marks.”
- For multi-image outputs, provide one or more reference images as input to lock the likeness.
How to prompt for consistent edits
- Start by describing the core identity attributes you want preserved: age, hair color, distinguishing features (e.g., “has a small mole on left cheek”), and clothing style.
- Use a two-part prompt when editing: first describe what must remain identical, then describe the change you want. Example: “Preserve: 28-year-old East Asian woman, short black bob, small left cheek mole. Change: place her in a 1970s diner wearing a red leather jacket, smiling, warm tungsten lighting.”
- When doing multi-step edits, include a small reference token like “(KEEP_ID: A)” in the prompt and reuse it to signal the same subject across prompts.
Example prompt
“Create a photorealistic portrait of Amina, a 28-year-old graphic novelist with a short asymmetrical haircut, a crescent mole on her left cheek, warm brown eyes, and a green leather jacket. Maintain Amina’s identifying features across the following 6 scene prompts: ‘Amina at a morning coffee shop’, ‘Amina sketching in the park’, … . Use the same character likeness for every scene.”
Code snippet (Python, generate multiple images)
This example uses the Gemini API client shown in Google’s docs — pass your descriptive prompt and loop scene variants.
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
base_description = (
"Photorealistic portrait of Amina: 28yo graphic novelist, short asymmetrical haircut, "
"crescent mole on left cheek, warm brown eyes, green leather jacket. Keep likeness identical across scenes."
)
scenes = [
"Amina at a morning coffee shop, reading a sketchbook, warm golden hour light.",
"Amina sketching in the park, windy afternoon, soft bokeh background.",
# add more scenes...
]
for i, scene in enumerate(scenes, start=1):
prompt = f"{base_description} Scene: {scene}"
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=,
)
parts = response.candidates.content.parts
for part in parts:
if part.inline_data:
img = Image.open(BytesIO(part.inline_data.data))
img.save(f"amina_scene_{i}.png")
2)How can Nano Banana accelerate e-commerce product photography and A/B imagery?
Why this is creative and useful
Product teams spend huge resources on multiple shots, lighting setups, and variations (colors, backgrounds). Nano Banana’s multi-image fusion and precise prompt editing let you generate consistent product variants and lifestyle composites fast — for catalog shots, lifestyle scenes, and social assets — cutting iteration time and production costs.
How to prompt for product variants
- Provide a short product spec (dimensions, materials, color palette) and the photographic style (e.g., “studio white background, 45° angle, soft shadow”).
- For variants: ““Make 4 variations of this Bluetooth headset: black, pink, gray with orange ear caps, and gray with blue glint – all with the same lighting, same camera angle, and in a white room.”.”
- Use multi-image fusion to drop the product into different scenes: “Place this backpack on a picnic blanket at golden hour with shallow depth of field.”
Example prompt (product)
“Image A (product reference): premium leather backpack. Create three catalog variants with white background — forest green, tan, charcoal — shot at a 45° angle, natural soft shadow, ISO feel of 100.”
Code snippet: quick Python generate (catalog variant)
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client(api_key="YOUR_API_KEY")
product_image = open("backpack_ref.png","rb").read()
prompt = ("Make 4 variations of this Bluetooth headset: black, pink, gray with orange ear caps, and gray with blue glint – all with the same lighting, same camera angle, and in a white room.")
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=,
)
# Save images from response parts (example)
for i, part in enumerate(response.candidates.content.parts):
if part.inline_data:
img = Image.open(BytesIO(part.inline_data.data))
img.save(f"backpack_variant_{i}.png")
This snippet reflects Google’s documented usage pattern and is a good starting point for automating product variant creation.
Output image:

3) How can I create educational illustrations that combine photos and diagrams?
Why this works
Nano Banana integrates world knowledge (Gemini’s multimodal reasoning) so it can interpret hand-drawn diagrams, annotate images, or create explanation visuals from a mix of photos and textual instructions — handy for e-learning, technical docs, and interactive tutors.
How to prompt
- Provide images (e.g., a photo of a physical experiment) and a prompt like “Annotate this image with labels and arrows that explain the key components, and create a second image that shows the system in cross-section.”
Example prompt
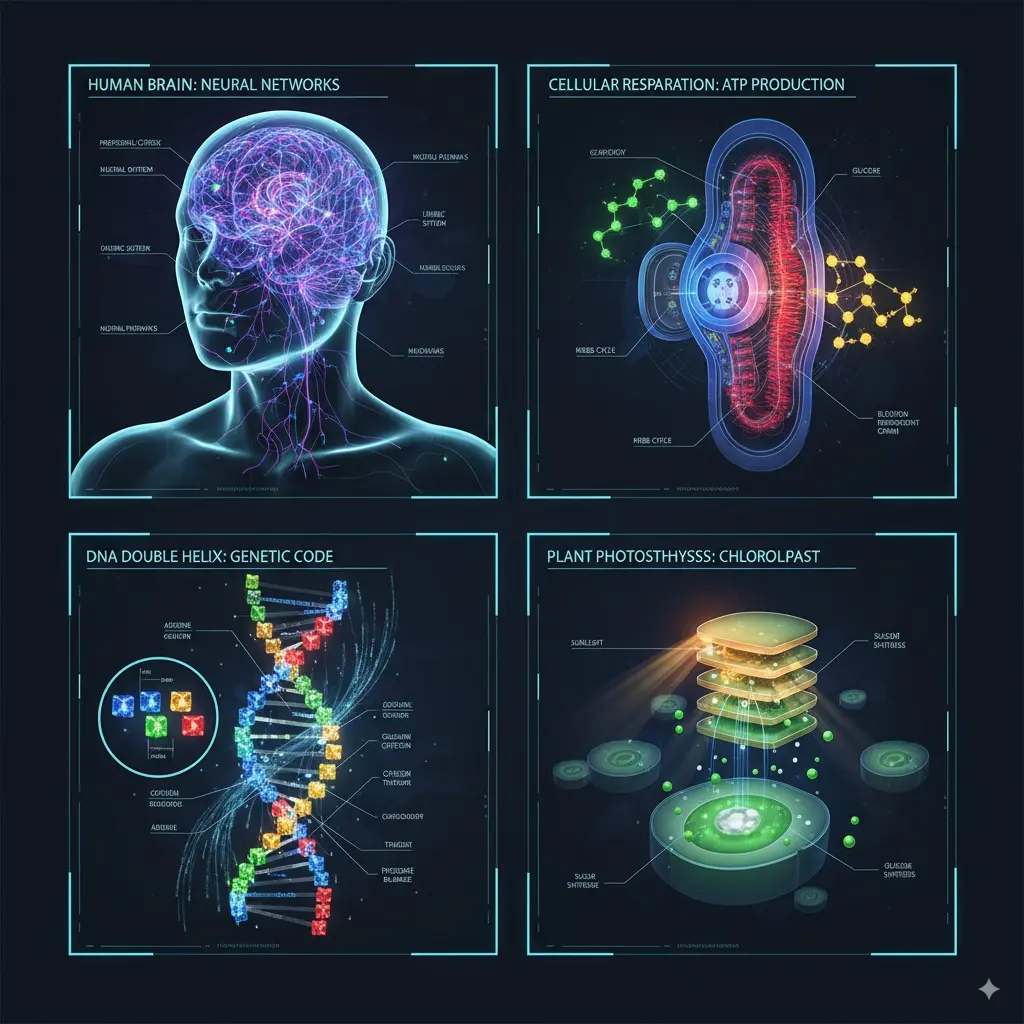
Generate four pieces of knowledge picture explanation: HUMAN BRAIN‘s NEURAL NETWORKS,CELLULAR RESPARATION ‘sATP PRODUCTION,DNA DOUBLE HELIX’s GENETIC CODE,CHLOROLPAST’s PLANT PHOTOSTHHYSSS
Output image:
4) How can I turn real photos into on-brand marketing variations (outfit, lighting, background)?
Why this works
The model supports targeted transformation and local edits expressed via natural language: change an outfit, adjust lighting, replace the background, or remove objects — and it tries to preserve subject identity and overall realism. This enables fast marketing variants (seasonal outfits, localized scenes).
How to prompt
- Provide the original photo as an input.
- Ask for targeted edits with explicit instructions, e.g., “Replace jacket with red wool peacoat, change background to city street at dusk, add warm rim light.”
Example prompt
“Starting from the uploaded photo, replace the blue denim jacket with a tailored red wool peacoat, set background to an early evening city street with light bokeh, and add gentle rim lighting to separate the subject from the background.”
Hints
- If you need iterative control, do multi-turn edits: ask for a first edit, then refine (“remove hat”, “now warm the color temperature”).
5) How can Animation creator and previsualization teams prototype scenes and storyboards?
Why it’s useful
Directors and DPs can prototype lighting setups, wardrobe, and camera framing quickly. Nano Banana can output storyboards with consistent characters, which helps planning and pre-vis. ()
H3: Example prompt
There is a tree house in the forest at night with colorful lights hanging on the trees
Output image:

6)How can Nano Banana be used for concept art, game assets, and consistent in-game characters?
Why game studios and indie devs should care
Creating art assets and iterating on character looks usually requires artists to rework characters repeatedly. Nano Banana’s character consistency makes it practical to generate numerous poses, outfits, and lighting setups that stay faithful to a single character identity — a massive time saver in pre-production and rapid prototyping.
How to prompt for game assets
- Define the “canonical” character sheet in text: height, body type, key features, wardrobe staples.
- Request multiple outputs: “Generate three battle armor variants with the same facial features, each shown in front, profile, and ¾ poses.”
- For environment art, use multi-image fusion: give one image of the character and one of the environment and prompt to fuse them.
Example prompt (game assets)
“Create three armored variants for ‘Kael, the wind ranger’: keep facial features (narrow jaw, scar above right eyebrow). Armor A: leather + teal cloth; Armor B: scale + brass; Armor C: stealth matte black. Output full body front, profile, ¾.”

Armor C: Stealth Matte Black

Armor B: Scale + Brass

Armor A: Leather + Teal Cloth
7) How can I automate photo retouch workflows with conversational multi-turn editing?
Why this works
Nano Banana supports conversational multi-turn image editing: you can ask for an edit, inspect the result, and follow up with more instructions in natural language. That’s perfect for building a human-in-the-loop retouch pipeline where an editor nudges the model across multiple passes.
How to implement the workflow
- Upload an initial photo and request a baseline retouch (lighting, blemish removal).
- In each turn, send the newly edited image back to the model with the next instruction (“reduce highlights, bring up shadows, crop to 4:5”).
- Log each step so you can revert or apply the same pass to a batch.
Mini workflow snippet (Python)
# 1) Initial retouch
prompt1 = "Remove small blemishes, even skin tone, slightly warm color grade"
response1 = client.models.generate_content(model="gemini-2.5-flash-image-preview", contents=)
# save response1 -> edited_v1.png
# 2) Follow-up tweak
prompt2 = "Crop to 4:5, increase local contrast on eyes, desaturate background slightly"
response2 = client.models.generate_content(model="gemini-2.5-flash-image-preview", contents=)
# save response2 -> edited_v2.png
How do I prompt Nano Banana to get the best results?
What prompting principles should I follow?
Nano Banana responds best to descriptive, narrative-style prompts that explain the scene, perspective, lighting, and mood — not just a list of keywords. The official guidance recommends supplying camera, lens, lighting, and stylistic cues for photorealism, or style and palette cues for illustrations. Also supply constraints (aspect ratio, background, text requirements) explicitly.
How do I structure a strong prompt?
Here are short, reusable templates:
- Photorealistic template:
A photorealistic of , , in , illuminated by , captured with , emphasizing . Aspect ratio: . - Style-transfer / composition template:
Combine Image A (style) with Image B (subject). Transfer the color palette of A, keep subject proportions of B. Final style:.
Prompt engineering tips (quick list)
- Use one clear narrative sentence rather than many disjointed tags.
- Add camera details for photorealism (e.g., “85mm, shallow depth of field”).
- For consistent characters across edits, reference the prior image and the attribute you wish to preserve (e.g., “keep subject’s freckles and blue scarf, change hairstyle to…”).
- When editing, upload the source image and describe exactly which regions or elements to change.
- Use iterative, multi-turn edits to refine tiny visual details (Nano Banana supports conversational refinement).
Final note
Nano Banana (Gemini 2.5 Flash Image) is a creative leap: it lets creators keep character and product continuity while enabling bold new edits, fusion of multiple images, and fast iteration. Use it to accelerate storytelling, reduce production friction, and prototype visuals at speed — but pair those gains with rigorous review and ethical guardrails.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Gemini 2.5 Flash Image(Nano Banana CometAPI list gemini-2.5-flash-image-preview/gemini-2.5-flash-image style entries in their catalog.) through CometAPI, the latest models version listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.