
Qwen2.5: Features, Deploy & Comparision

In the rapidly evolving landscape of artificial intelligence, 2025 has witnessed significant advancements in large language models (LLMs). Among the frontrunners are Alibaba’s Qwen2.5, DeepSeek’s V3 and R1 models, and OpenAI’s ChatGPT. Each of these models brings unique capabilities and innovations to the table. This article delves into the latest developments surrounding Qwen2.5, comparing its features and performance with DeepSeek and ChatGPT to determine which model currently leads the AI race.
What is Qwen2.5?
Overview
Qwen 2.5 is Alibaba Cloud’s latest dense, decoder-only large language model, available in multiple sizes ranging from 0.5B to 72B parameters. It is optimized for instruction-following, structured outputs (e.g., JSON, tables), coding, and mathematical problem-solving. With support for over 29 languages and a context length of up to 128K tokens, Qwen2.5 is designed for multilingual and domain-specific applications.
Key Features
- Multilingual Support: Supports over 29 languages, catering to a global user base.
- Extended Context Length: Handles up to 128K tokens, enabling processing of long documents and conversations.
- Specialized Variants: Includes models like Qwen2.5-Coder for programming tasks and Qwen2.5-Math for mathematical problem-solving.
- Accessibility: Available through platforms like Hugging Face, GitHub, and a newly launched web interface at chat.qwenlm.ai.
How to use Qwen 2.5 locally?
Below is a step‑by‑step guide for the 7 B Chat checkpoint; larger sizes differ only in GPU requirements.
1. Hardware prerequisites
| Model | vRAM for 8‑bit | vRAM for 4‑bit (QLoRA) | Disk size |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
A single RTX 4090 (24 GB) suffices for 7 B inference at full 16‑bit precision; two such cards or CPU off‑load plus quantization can handle 14 B.
2. Installation
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Quick inference script
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out[0], skip_special_tokens=True))
The trust_remote_code=True flag is required because Qwen ships a custom Rotary Position Embedding wrapper.
4. Fine‑tuning with LoRA
Thanks to parameter‑efficient LoRA adapters you can specialty‑train Qwen on ~50 K domain pairs (say, medical) in under four hours on a single 24 GB GPU:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
The resulting adapter file (~120 MB) can be merged back or loaded on demand.
Optional: Run Qwen 2.5 as an API
CometAPI acts as a centralized hub for APIs of several leading AI models, eliminating the need to engage with multiple API providers separately. CometAPI offers a price far lower than the official price to help you integrate Qwen API , and you will get $1 in your account after registering and logging in! Welcome to register and experience CometAPI.For developers aiming to incorporate Qwen 2.5 into applications:
Step 1: Install necessary libraries:
bash
pip install requestsStep 2: obtain API Key
- Navigate to CometAPI.
- Sign in with your CometAPI account.
- Select the Dashboard.
- Click on “Get API Key” and follow the prompts to generate your key.
Step 3: Implement API Calls
Utilize the API credentials to make requests to Qwen 2.5.Replace <YOUR_AIMLAPI_KEY> with your actual CometAPI key from your account.
For example, in Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json()["text"])This integration allows for seamless incorporation of Qwen 2.5’s capabilities into various applications, enhancing functionality and user experience.Select the “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
Please refer to Qwen 2.5 Max API for integration details.CometAPI has updated the latest QwQ-32B API.For more Model information in Comet API please see API doc.
Best practices and tips
| Scenario | Recommendation |
|---|---|
| Long document Q&A | Chunk passages into ≤16 K tokens and use retrieval‑augmented prompts instead of naïve 100 K contexts to reduce latency. |
| Structured outputs | Prefix the system message with: You are an AI that strictly outputs JSON. Qwen 2.5’s alignment training excels at constrained generation. |
| Code completion | Set temperature=0.0 and top_p=1.0 to maximize determinism, then sample multiple beams (num_return_sequences=4) for ranking. |
| Safety filtering | Use Alibaba’s open‑sourced “Qwen‑Guardrails” regex bundle or OpenAI’s text‑moderation‑004 as a first pass. |
Known limitations of Qwen 2.5
- Prompt injection susceptibility. External audits show jailbreak success rates of 18 % on Qwen 2.5‑VL—a reminder that sheer model size does not immunize against adversarial instructions.
- Non‑Latin OCR noise. When finetuned for vision‑language tasks, the model’s end‑to‑end pipeline sometimes confuses traditional vs. simplified Chinese glyphs, requiring domain‑specific correction layers.
- GPU memory cliff at 128 K. FlashAttention‑2 offsets RAM, but a 72 B dense forward pass across 128 K tokens still demands >120 GB vRAM; practitioners should window‑attend or KV‑cache.
Roadmap & community ecosystem
The Qwen team has hinted at Qwen 3.0, targeting a hybrid routing backbone (Dense + MoE) and unified speech‑vision‑text pretraining. Meanwhile, the ecosystem already hosts:
- Q‑Agent – a ReAct‑style chain‑of‑thought agent using Qwen 2.5‑14B as policy.
- Chinese Financial Alpaca – a LoRA on Qwen2.5‑7B trained with 1 M regulatory filings.
- Open Interpreter plug‑in – swaps GPT‑4 for a local Qwen checkpoint in VS Code.
Check the Hugging Face “Qwen2.5 collection” page for a continuously updated list of checkpoints, adapters and evaluation harnesses.
Comparative Analysis: Qwen2.5 vs. DeepSeek and ChatGPT
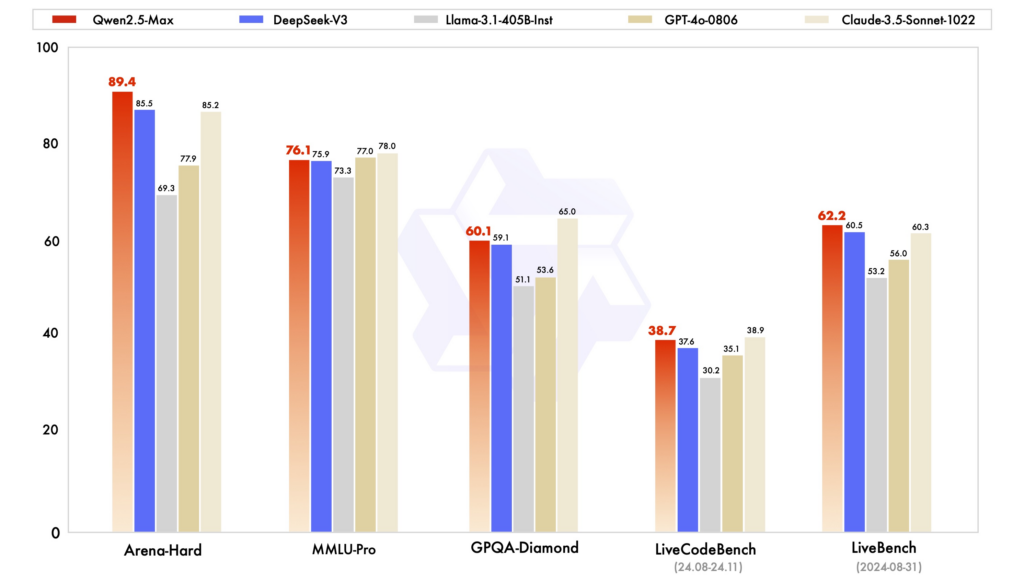
Performance Benchmarks: In various evaluations, Qwen2.5 has demonstrated strong performance in tasks requiring reasoning, coding, and multilingual understanding. DeepSeek-V3, with its MoE architecture, excels in efficiency and scalability, delivering high performance with reduced computational resources. ChatGPT remains a robust model, particularly in general-purpose language tasks.
Efficiency and Cost: DeepSeek’s models are notable for their cost-effective training and inference, leveraging MoE architectures to activate only necessary parameters per token. Qwen2.5, while dense, offers specialized variants to optimize performance for specific tasks. ChatGPT’s training involved substantial computational resources, reflecting in its operational costs.
Accessibility and Open-Source Availability: Qwen2.5 and DeepSeek have embraced open-source principles to varying degrees, with models available on platforms like GitHub and Hugging Face. Qwen2.5’s recent launch of a web interface enhances its accessibility. ChatGPT, while not open-source, is widely accessible through OpenAI’s platform and integrations.
Conclusion
Qwen 2.5 sits at a sweet spot between closed‑weight premium services and fully open hobbyist models. Its blend of permissive licensing, multilingual strength, long‑context competence and a broad range of parameter scales makes it a compelling foundation for both research and production.
As the open‑source LLM landscape races ahead, the Qwen project demonstrates that transparency and performance can coexist. For developers, data scientists and policy makers alike, mastering Qwen 2.5 today is an investment in a more pluralistic, innovation‑friendly AI future.


