
Qwen3: What it is & How to Use

In April 2025, Alibaba Cloud launched Qwen3, the latest version in the Qwen series of large language models (LLMs). As a significant advancement in the field of artificial intelligence, Qwen3 demonstrates outstanding capabilities in language understanding, reasoning, multimodal processing, and computational efficiency. The model supports 119 languages, is trained on a dataset of 36 trillion tokens, and offers various model sizes ranging from 0.6 billion to 235 billion parameters. This article provides an in-depth exploration of Qwen3’s definition, features, usage methods, access approaches, comparisons with other models, and its potential impact on the AI domain, aiming to serve as a comprehensive reference for developers, researchers, and enterprises.
What is Qwen3?
Qwen3 is a series of large language models designed to understand and generate human-like text, suitable for a range of scenarios from everyday conversation to complex reasoning tasks. It is the third generation in the Qwen series developed by Alibaba Cloud, following the release of Qwen in 2023 and Qwen2 in 2024, which introduced improvements in performance and functionality.
A Brief History of the Qwen Series
The Qwen series began in April 2023 with the release of the Qwen model, initially named “Tongyi Qianwen,” based on Meta AI’s Llama architecture. After receiving approval from the Chinese government in September 2023, Qwen was officially released to the public. In December 2023, the Qwen 72B and 1.8B models were made open-source, followed by the launch of Qwen2 in June 2024, which adopted a Mixture of Experts (MoE) architecture. Qwen3, introduced in April 2025, incorporates hybrid reasoning capabilities and multimodal functionalities, making it the most advanced version in the series.
Features of Qwen3
Qwen3 offers a range of innovative features that distinguish it in the global AI model landscape:
Multilingual Support
Qwen3 supports 119 languages, covering major global language systems. This makes it an ideal choice for cross-cultural and multilingual applications, such as international customer support and multilingual content generation.
Large-Scale Training Data
The Qwen3 training dataset consists of nearly 36 trillion tokens, equating to approximately 270 billion words. It includes a wide range of content, such as textbooks, question-and-answer pairs, code snippets, and AI-generated content, primarily in Chinese and English. This scale ensures its excellent performance in language understanding and generation.
Diverse Model Sizes
Qwen3 offers a variety of model sizes ranging from 0.6 billion to 235 billion parameters:
- Small Models (0.6B, 1.7B): Suitable for lightweight applications, capable of running on devices like smartphones.
- Medium Models (4B, 8B, 14B, 32B): Balance performance with resource needs, applicable to most development scenarios.
- Large Models (235B): Provide top-tier performance for enterprise-level tasks.
| Model Name | Parameter Size | Context Window (tokens) | Applicable Scenarios |
|---|---|---|---|
| Qwen3-0.6B | 0.6 billion | 32,768 | Mobile devices, lightweight applications |
| Qwen3-1.7B | 1.7 billion | 32,768 | Embedded systems, rapid reasoning |
| Qwen3-4B | 4 billion | 131,072 | Small to medium-sized projects, research |
| Qwen3-8B | 8 billion | 131,072 | General applications, development |
| Qwen3-32B | 32 billion | 131,072 | High-performance tasks, enterprise applications |
| Qwen3-235B-A22B | 235 billion | 131,072 | Top-tier performance, complex reasoning (not publicly available) |
Hybrid Reasoning Capabilities
Qwen3 introduces a “hybrid reasoning” feature that allows the model to reason step-by-step before providing answers to complex questions. This capability is particularly prominent in logical reasoning, mathematical problems, and programming tasks. Users can enable or disable this mode through settings (e.g., enable_thinking=True).
Mixture of Experts (MoE) Models
Qwen3 includes Mixture of Experts models, such as Qwen3-30B-A3B (30 billion parameters, 3 billion active) and Qwen3-235B-A22B (235 billion parameters, 22 billion active). These models accelerate inference by activating only a subset of parameters while maintaining high performance, making them well-suited for large-scale deployment.
Expanded Token Limits
Some Qwen3 models support context windows of up to 131,072 tokens (models 4B and above), a significant increase from Qwen2’s 32,768 tokens. This enhancement allows the model to handle longer dialogues and more complex text generation tasks.

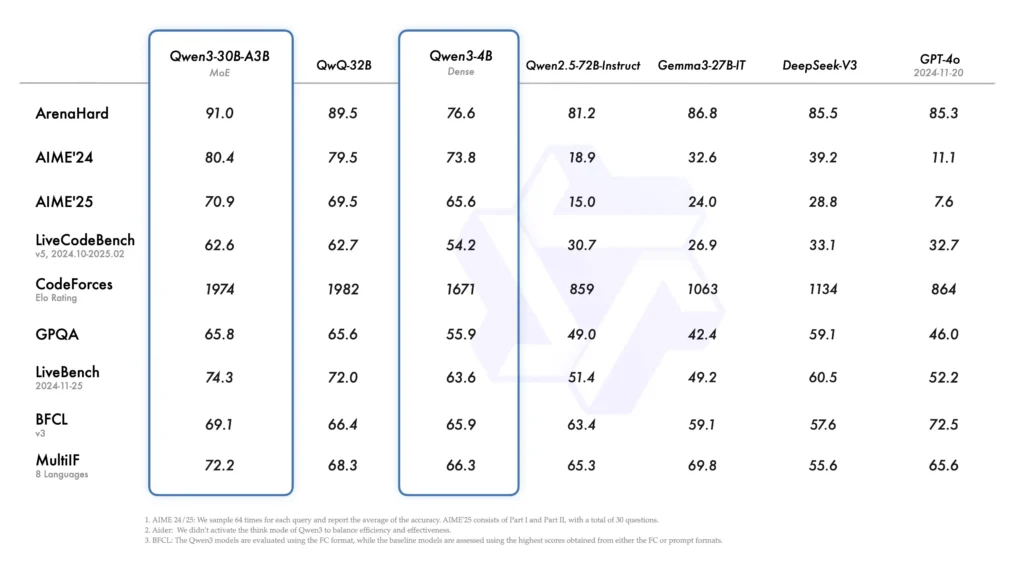
Qwen 3 Benchmarks
The model demonstrates proficiency in code generation, debugging, and mathematical problem-solving, making it a valuable tool for software development and data analysis.
How to Use Qwen3
Applications
The versatility of Qwen3 makes it suitable for various scenarios:
- Chatbots and Virtual Assistants: Provide natural, context-aware responses for customer support and personal assistant applications.
- Content Generation: Generate articles, stories, code, and other creative or technical content.
- Data Analysis: Assist in interpreting and summarizing large datasets for research and business intelligence.
- Educational Tools: Help students with homework, explanations, and personalized learning experiences.
- Scientific Research: Support literature review, hypothesis generation, and scientific problem-solving.
Project Integration
Developers can integrate Qwen3 into their projects using the following frameworks and tools:
- Transformers: Requires
transformers>=4.51.0. Example code snippet:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
inputs = tokenizer("Hello, how can I assist you?", return_tensors="pt")
outputs = model.generate(**inputs, enable_thinking=True)
print(tokenizer.decode(outputs[0]))Users can enable the reasoning mode with enable_thinking=True or control it using /think and /nothink.
- llama.cpp: Requires
llama.cpp>=b5092. Command line example:
./llama-cli -hf Qwen/Qwen3-8B-GGUF:Q8_0 --jinja --color -ngl 99 -fa -sm row --temp 0.6 --top-k 20 --top-p 0.95 --min-p 0 -c 40960 -n 32768 --no-context-shift- Ollama: Requires
Ollama v0.6.6or higher. Run command:
ollama run qwen3:8bSupports parameters like num_ctx 40960 and num_predict 32768.
- Deployment Options:
- SGLang: Requires
sglang>=0.4.6.post1. Launch command:python -m sglang.launch_server --model-path Qwen/Qwen3-8B --port 30000 --reasoning-parser qwen3 - vLLM: Requires
vllm>=0.8.5. Serve command:vllm serve Qwen/Qwen3-8B --port 8000 --enable-reasoning --reasoning-parser deepseek_r1 - MindIE: Supports Ascend NPU; visit Modelers for details.
Tool Usage
Qwen-Agent supports Qwen3’s interaction with external tools and APIs, suitable for tasks requiring dynamic data access. This feature is also supported by SGLang, vLLM, Transformers, llama.cpp, and Ollama.
Finetuning
Qwen3 can be fine-tuned using frameworks such as Axolotl, UnSloth, Swift, and Llama-Factory, supporting techniques like Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Robust Preference Optimization (GRPO).
Conclusion
Qwen3 represents a breakthrough in the field of large language models, offering enhanced functionality, versatility, and accessibility. With its multilingual support, hybrid reasoning, and specialized versions for vision, math, and audio tasks, Qwen3 positions itself as a key player in the AI field. Its competitive performance in benchmarks such as Codeforces, AIME, and BFCL, along with its open-source availability, makes it an ideal choice for developers, researchers, and enterprises. As AI technology advances, Qwen3 signifies an important step towards creating intelligent systems capable of understanding, reasoning, and interacting with the world in increasingly sophisticated ways.
Getting Started
Developers can access Qwen 3 API through CometAPI. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Note that some developers may need to verify their organization before using the model.


