
How Does Qwen3 Work?

Qwen3 represents a significant leap forward in open-source large language models (LLMs), blending sophisticated reasoning capabilities with high efficiency and broad accessibility. Developed by Alibaba’s research and cloud computing teams, Qwen3 is positioned to rival leading proprietary systems such as OpenAI’s GPT-4x and Google’s PaLM, while remaining fully open under the Apache 2.0 license. This article explores in depth how Qwen3 was conceived, its underlying mechanisms, the training regimen that forged its capabilities, and the avenues through which developers worldwide can harness its power.
What is Qwen3 and why does it matter?
Large language models have transformed natural language understanding and generation, powering everything from conversational agents to code assistants. Qwen3 is the latest in Alibaba’s Qwen family, following Qwen2.5 and its variants, and embodies several flagship innovations:
- Hybrid reasoning: Seamlessly integrates “thinking” and “non-thinking” modes into a single architecture, allowing dynamic allocation of computational resources based on task complexity .
- Mixture-of-Experts (MoE) options: Offers models that activate only a subset of specialized expert modules per query, boosting efficiency without sacrificing performance.
- Scale diversity: Ranges from lightweight 0.6 billion-parameter dense models to massive 235 billion-parameter sparse MoE variants, catering to diverse deployment scenarios .
- Extended context windows: Most larger variants support up to 128K token contexts, facilitating long-form documents, codebases, and multimodal conversations .
- Multilingual breadth: Trained on 36 trillion tokens spanning 119 languages and dialects, empowering truly global applications .
These characteristics position Qwen3 not only as a top performer on benchmarks in code generation, mathematical reasoning, and agent tasks but also as a flexible, cost-effective solution for real-world deployments.
What Architecture Does Qwen3 Employ?
Unified reasoning framework
Traditional LLM ecosystems often segregate chat-optimized models (e.g., GPT-4o) and specialized reasoning models (e.g., QwQ-32B). Qwen3 collapses this division by embedding both rapid context-driven “non-thinking” inference and deep, multi-step “thinking” processes within the same model. A mode token or API flag triggers either lightweight attention layers for simple tasks or deeper, iterative reasoning pipelines for complex queries.
Mixture-of-Experts (MoE) variants
Some Qwen3 models adopt an MoE structure, wherein the network comprises hundreds of expert submodules, but only a small, task-relevant subset is activated at runtime. This yields significant compute savings—only the most pertinent experts process each token—while maintaining state-of-the-art accuracy on reasoning benchmarks .
Dense and Mixture-of-Experts Models
To balance efficiency and capacity, the Qwen3 family comprises six dense models (0.6B, 1.7B, 4B, 8B, 14B, and 32B parameters) alongside two MoE variants (30B with 3B active parameters, and 235B with 22B active parameters). Dense models offer streamlined inference for resource-constrained environments, while MoE architectures leverage sparse activation to maintain high capacity without linear increases in computational cost.
Mixture-of-Experts (MoE) architectures alleviate the memory and compute burdens of large dense models by activating only a fraction of the network’s parameters per token. Qwen3 offers two sparse variants:
- 30B-parameter MoE (3B activated parameters per token)
- 235B-parameter MoE (22B activated parameters per token)
These sparse families match or exceed the performance of comparable dense counterparts on benchmarks while reducing inference costs—particularly critical for real-time applications and large-scale deployments. Alibaba’s internal tests show MoE variants achieving up to 60× faster reasoning times on specialized hardware like Cerebras’ wafer-scale engines .
Thinking Mode and Non-Thinking Mode
A hallmark innovation in Qwen3 is its dual-mode design: thinking mode for intricate, multi-step reasoning tasks, and non-thinking mode for rapid, context-driven responses. Rather than maintaining separate specialized models, Qwen3 integrates both capabilities under a unified architecture. This is enabled by a dynamic thinking budget mechanism, which allocates computational resources adaptively during inference, letting the model flexibly trade off latency and reasoning depth based on input complexity.
How Does Qwen3 Work?
Dynamic Mode Switching
Upon receiving a prompt, Qwen3 evaluates the required reasoning complexity against predefined thresholds. Simple queries trigger non-thinking mode, yielding responses in milliseconds, whereas complex multi-hop tasks—such as mathematical proofs or strategic planning—activate thinking mode, allocating additional transformer layers and attention heads as needed. Developers can also customize mode-switch triggers via chat templates or API parameters, tailoring the user experience to specific applications.
- Non-thinking mode: Allocates minimal layers/expert calls, optimizing for latency and throughput.
- Thinking mode: Dynamically extends the computation graph, enabling multi-hop reasoning and chaining sub-questions internally.
- Adaptive switching: The model can autonomously shift between modes mid-inference if the query’s complexity warrants additional reasoning steps.
Inference Efficiency and Latency
In collaboration with hardware partners like Cerebras Systems, Qwen3-32B achieves real-time reasoning performance. Benchmarks on the Cerebras Inference Platform demonstrate sub-1.2-second response times for complex reasoning tasks, up to 60× faster than comparable models such as DeepSeek R1 and OpenAI o3-mini. This low-latency performance unlocks production-grade agents and copilots in interactive settings, from customer support chatbots to real-time decision support systems.
Deployment and Accessibility
Open-Source Release and Integration
On April 28, 2025, Alibaba officially released Qwen3 under the Apache 2.0 license, enabling unrestricted access to weights, code, and documentation on GitHub and Hugging Face. In the weeks following launch, the Qwen3 family became deployable on key LLM platforms such as Ollama, LM Studio, SGLang, and vLLM, streamlining local inference for developers and enterprises worldwide.
Flexible Formats and Quantization Support
To accommodate diverse deployment scenarios—ranging from high-throughput datacenter inference to low-power edge devices—Qwen3 supports multiple weight formats, including GPT-generated unified format, activation-aware quantization, and general post-training quantization. Early studies reveal that 4- to 8-bit post-training quantization maintains competitive performance, although ultra-low (1–2 bit) precision introduces notable accuracy degradation, highlighting areas for future research in efficient LLM compression.
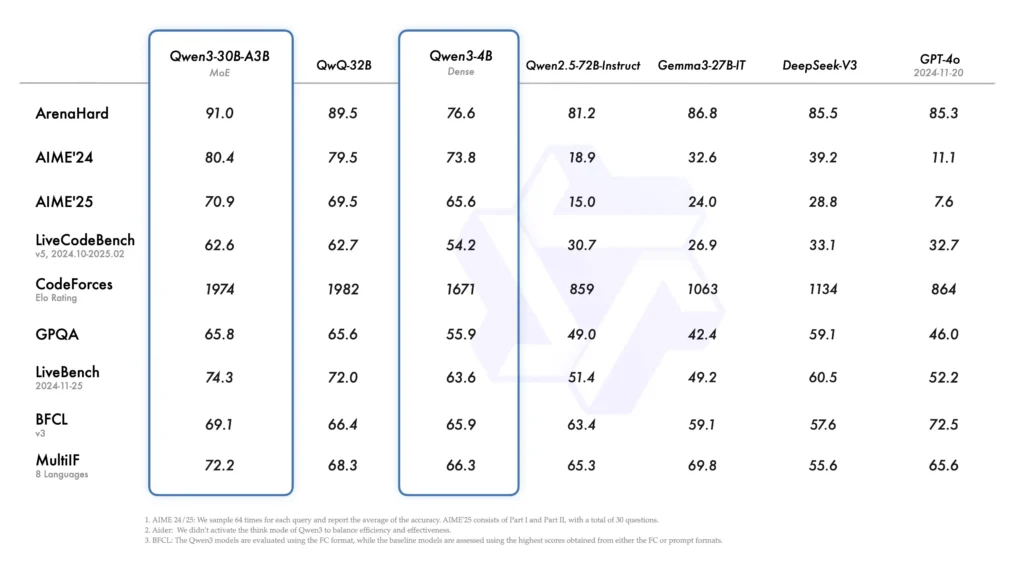
Performance and Benchmarking
Leaderboard Rankings
According to the LiveBench leaderboard as of May 6, 2025, the flagship Qwen3-235B-A22B model ranks as the top open-source LLM, securing 7th place overall among both open and closed models, and achieving the highest score in instruction-following tasks. This milestone underscores Qwen3’s competitive parity with proprietary counterparts like GPT-4 and DeepSeek R1.
Comparative Evaluations
Independent evaluations by TechCrunch and VentureBeat highlight Qwen3’s superior performance in coding and mathematical benchmarks. When compared to leading solutions such as DeepSeek R1, OpenAI’s o1, and Google’s Gemini 2.5-Pro, Qwen3-235B-A22B demonstrates comparable or improved results across a spectrum of tasks, from algorithm synthesis to formal proof generation.
Specialized Variants: Qwen3-Math and QwenLong-L1
Qwen3-Math
Qwen3-Math is a specialized variant designed for mathematical reasoning tasks. It extends support to both Chain-of-Thought (CoT) and Tool-Integrated Reasoning (TIR) for solving math problems in both Chinese and English. TIR enhances the model’s ability to perform precise computations, symbolic manipulation, and algorithmic processes, addressing challenges in tasks that require high computational precision .
QwenLong-L1
QwenLong-L1 is a framework that adapts short-context large reasoning models to long-context scenarios via progressive context scaling. It utilizes a warm-up supervised fine-tuning stage to establish a robust initial policy, followed by a curriculum-guided phased reinforcement learning technique to stabilize policy evolution. This approach enables robust reasoning across information-intensive environments .
Challenges and Future Directions
Hallucinations and Robustness
Despite strong quantitative metrics, Qwen3 exhibits occasional “hallucinations” in factual or contextually ambiguous scenarios. Ongoing research focuses on refining retrieval-augmented generation and grounding mechanisms to enhance factual accuracy, as preliminary analyses indicate a 15–20% reduction in hallucination rates when integrating external knowledge bases.
Quantization and Edge Deployment
While moderate quantization preserves Qwen3’s core capabilities, extreme compression remains a challenge. Further advances in mixed-precision training, hardware-aware quantization algorithms, and efficient transformer architectures are essential to democratize sophisticated AI on constrained devices such as smartphones, IoT sensors, and embedded systems.
Conclusion
Qwen3’s development reflects a paradigm shift toward unified, dynamically adaptable LLM architectures that bridge conversational fluency with deep reasoning. By open-sourcing its weights and offering versatile deployment options—from cloud inference to on-device acceleration—Alibaba’s Qwen team has propelled global collaboration and innovation in AI. As the research community tackles remaining challenges in model robustness, quantization, and multimodal integration, Qwen3 stands poised as a foundational platform for next-generation intelligent systems across industries.
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—including ChatGPT family—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
Developers can access Qwen 3 API through CometAPI.To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key.


