MiniMax‑M1: The First Open‑Weight Hybrid‑Attention Inference Model
On June 17, Shanghai AI unicorn MiniMax officially open‑sourced MiniMax‑M1, the world’s first open‑weight large‑scale hybrid‑attention inference model. By combining a Mixture‑of‑Experts (MoE) architecture with the new Lightning Attention mechanism, MiniMax‑M1 delivers major gains in inference speed, ultra‑long context handling, and complex task performance .
Background and Evolution
Building upon the foundation of MiniMax-Text-01, which introduced lightning attention on a Mixture-of-Experts (MoE) framework to achieve 1 million-token contexts during training and up to 4 million tokens at inference, MiniMax-M1 represents the next generation of the MiniMax-01 series. The predecessor model, MiniMax-Text-01, contained 456 billion total parameters with 45.9 billion activated per token, demonstrating performance on par with top-tier LLMs while vastly extending context capabilities .
Key Features of MiniMax‑M1
- Hybrid MoE + Lightning Attention: MiniMax‑M1 fuses a sparse Mixture‑of‑Experts design—456 billion total parameters, but only 45.9 billion activated per token—with Lightning Attention, a linear‑complexity attention optimized for very long sequences.
- Ultra‑Long Context: Supports up to 1 million input tokens—about eight times the 128 K limit of DeepSeek‑R1—enabling deep comprehension of massive documents .
- Superior Efficiency: When generating 100 K tokens, MiniMax‑M1’s Lightning Attention requires only ~25–30% of the compute used by DeepSeek‑R1.
Model Variants
- MiniMax‑M1‑40K: 1 M token context, 40 K token inference budget
- MiniMax‑M1‑80K: 1 M token context, 80 K token inference budget
In TAU‑bench tool‑use scenarios, the 40K variant outperformed all open‑weight models—including Gemini 2.5 Pro—demonstrating its agent capabilities .
Training Cost & Setup
MiniMax-M1 was trained end-to-end using large-scale reinforcement learning (RL) across a diverse set of tasks—from advanced mathematical reasoning to sandbox-based software engineering environments. A novel algorithm, CISPO (Clipped Importance Sampling for Policy Optimization), further enhances training efficiency by clipping importance sampling weights instead of token-level updates. This approach, combined with the model’s lightning attention, allowed full RL training on 512 H800 GPUs to complete in just three weeks at a total rental cost of \$534,700.
Availability and Pricing
MiniMax-M1 is released under the Apache 2.0 open‑source license and is immediately accessible via:
- GitHub repository, including model weights, training scripts, and evaluation benchmarks .
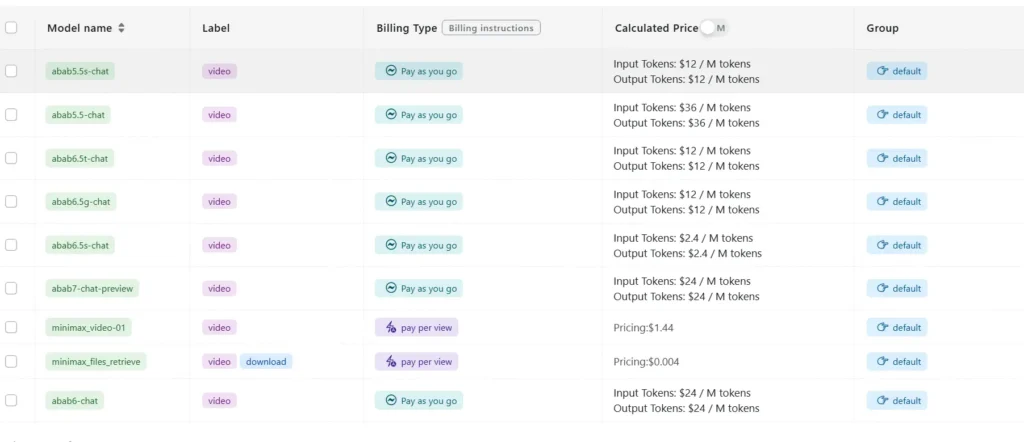
- SiliconCloud hosting, offering two variants—40 K‑token (“M1‑40K”) and 80 K‑token (“M1‑80K”)—with plans to enable the full 1 M token funnel.
- Pricing currently set at ¥4 per million tokens for input and ¥16 per million tokens for output, with volume discounts available for enterprise customers .
Developers and organizations can integrate MiniMax-M1 via standard APIs, fine‑tune on domain‑specific data, or deploy on-premises for sensitive workloads.
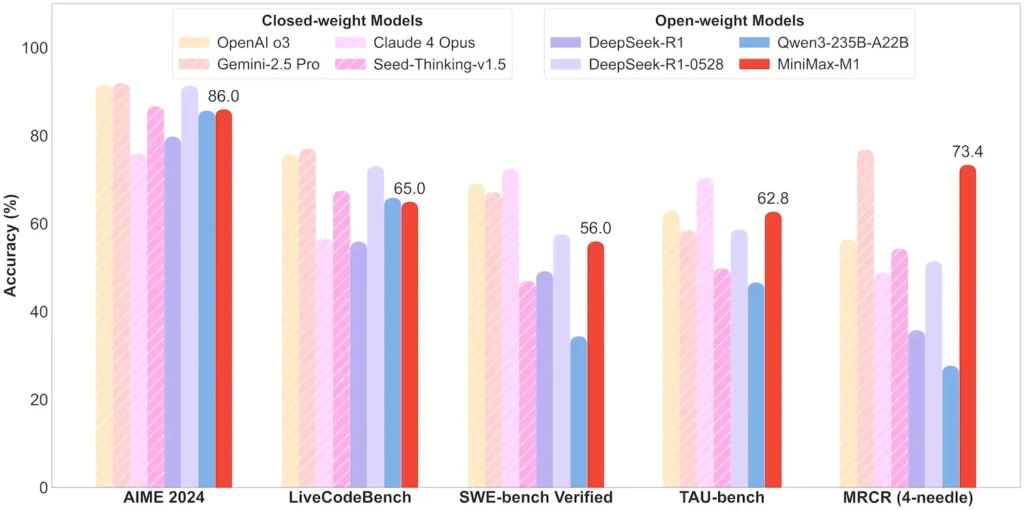
Task‑Level Performance
| Task Category | Highlight | Relative Performance |
|---|---|---|
| Mathematics & Logic | AIME 2024: 86.0% | > Qwen 3, DeepSeek‑R1; near closed‑source |
| Long‑Context Comprehension | Ruler (4 K–1 M tokens): Stable top‑tier | Outperforms GPT‑4 beyond 128 K token length |
| Software Engineering | SWE‑bench (real GitHub bugs): 56% | Best among open models; 2nd to leading closed |
| Agent & Tool Use | TAU‑bench (API simulation) | 62–63.5% vs. Gemini 2.5, Claude 4 |
| Dialogue & Assistant | MultiChallenge: 44.7% | Matches Claude 4, DeepSeek‑R1 |
| Fact QA | SimpleQA: 18.5% | Area for future improvement |
Note: percentages and benchmarks from official MiniMax disclosure and independent news reports
Technical Innovations
- Hybrid Attention Stack: Lightning Attention layers (linear cost) interleaved with periodic Softmax Attention (quadratic but more expressive) to balance efficiency and modeling power.
- Sparse MoE Routing: 32 expert modules; each token only activates ~10% of the total parameters, reducing inference cost while preserving capacity.
- CISPO Reinforcement Learning: A novel “Clipped IS‑weight Policy Optimization” algorithm that retains rare but crucial tokens in the learning signal, accelerating RL stability and speed.
MiniMax‑M1’s open‑weight release unlocks ultra‑long‑context, high‑efficiency inference for everyone—bridging the gap between research and deployable large‑scale AI.
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—including ChatGPT family—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
To begin, explore models’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key.
The latest integration MiniMax‑M1 API will soon appear on CometAPI, so stay tuned!While we finalize MiniMax‑M1 Model upload, explore our other models on the Models page or try them in the AI Playground. MiniMax’s latest Model in CometAPI are Minimax ABAB7-Preview API and MiniMax Video-01 API ,refer to: