What is MiniMax-M1? All You Need to Know
On June 17, 2025, Shanghai-based AI leader MiniMax (also known as Xiyu Technology) officially released MiniMax-M1 (hereafter “M1”)—the world’s first open-weight, large-scale, hybrid-attention reasoning model. Combining a Mixture-of-Experts (MoE) architecture with an innovative Lightning Attention mechanism, M1 achieves industry-leading performance in productivity-oriented tasks, rivaling top closed-source systems while maintaining unparalleled cost-effectiveness. In this in-depth article, we explore what M1 is, how it works, its defining features, and practical guidance on accessing and using the model.
What is MiniMax-M1?
MiniMax-M1 represents the culmination of MiniMaxAI’s research into scalable, efficient attention mechanisms. Building on the MiniMax-Text-01 foundation, the M1 iteration integrates lightning attention with a MoE framework to achieve unprecedented efficiency during both training and inference. This combination enables the model to maintain high performance even when processing extremely long sequences — a key requirement for tasks involving extensive codebases, legal documents, or scientific literature .
Core architecture and parameterization
At its core, MiniMax-M1 leverages a hybrid MoE system that dynamically routes tokens through a subset of expert sub-networks. While the model comprises 456 billion parameters in total, only 45.9 billion are activated for each token, optimizing resource usage. This design draws inspiration from earlier MoE implementations but refines the routing logic to minimize communication overhead between GPUs during distributed inference .
Lightning attention and long-context support
A defining feature of MiniMax-M1 is its lightning attention mechanism, which drastically reduces the computational burden of self-attention for long sequences. By approximating attention matrices through a combination of local and global kernels, the model cuts FLOPs by up to 75% compared to traditional transformers when processing 100K token sequences . This efficiency not only accelerates inference but also opens the door to handling context windows of up to one million tokens without prohibitive hardware requirements.
How does MiniMax-M1 achieve compute efficiency?
MiniMax-M1’s efficiency gains stem from two primary innovations: its hybrid Mixture-of-Experts architecture and the novel CISPO reinforcement learning algorithm used during training. Together, these elements reduce both training time and inference cost, enabling rapid experimentation and deployment.
Hybrid Mixture-of-Experts routing
The MoE component employs 32 expert sub-networks, each specializing in different aspects of reasoning or domain-specific tasks. During inference, a learned gating mechanism dynamically selects the most relevant experts for each token, activating only those sub-networks needed to process the input. This selective activation slashes redundant computations and reduces memory bandwidth demands, granting MiniMax-M1 a substantial edge in cost efficiency over monolithic transformer models .
CISPO: A novel reinforcement learning algorithm
To further bolster training efficiency, MiniMaxAI developed CISPO (Clipped Importance Sampling with Partial Overrides), an RL algorithm that replaces token-level weight updates with importance-sampling-based clipping. CISPO mitigates weight explosion issues common in large-scale RL setups, accelerates convergence, and ensures stable policy improvement across diverse benchmarks. As a result, MiniMax-M1’s full RL training on 512 H800 GPUs completes in just three weeks, costing approximately $534,700 — a fraction of the cost reported for comparable GPT-4 training runs.
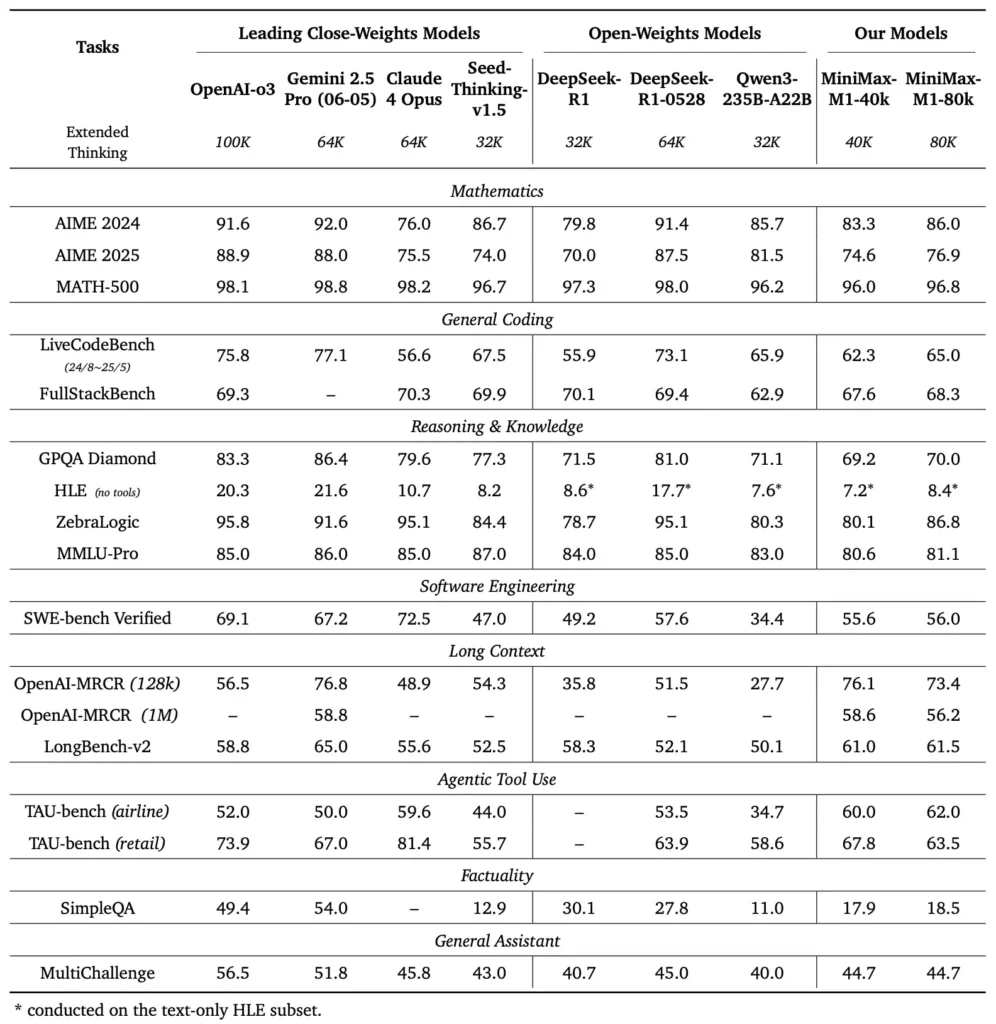
What are the performance benchmarks of MiniMax-M1?
MiniMax-M1 excels across a variety of standard and domain-specific benchmarks, demonstrating its prowess in handling long-context reasoning, mathematical problem solving, and code generation.
Long-context reasoning tasks
In extensive document understanding tests, MiniMax-M1 processes context windows up to 1,000,000 tokens, outperforming DeepSeek-R1 by a factor of eight in maximum context length and halving compute requirements for sequences of 100K tokens . On benchmarks like the NarrativeQA extended context evaluation, the model achieves state-of-the-art comprehension scores, attributing to its lightning attention’s ability to capture both local and global dependencies efficiently.
Software engineering and tool utilization
MiniMax-M1 was specifically trained on sandboxed software engineering environments using large-scale RL, enabling it to generate and debug code with remarkable accuracy. In coding benchmarks such as HumanEval and MBPP, the model attains pass rates comparable to or exceeding those of Qwen3-235B and DeepSeek-R1, particularly in multi-file codebases and tasks requiring cross-referencing long code segments . Furthermore, MiniMaxAI’s early demonstrations showcase the model’s ability to integrate with developer tools, from generating CI/CD pipelines to auto-documentation workflows.
How can developers access MiniMax-M1?
To foster widespread adoption, MiniMaxAI has made MiniMax-M1 freely available as an open-weight model. Developers can access pre-trained checkpoints, model weights, and inference code via the official GitHub repository.
Open-weight release on GitHub
MiniMaxAI published MiniMax-M1’s model files and accompanying scripts under an permissive open-source license on GitHub. Interested users can clone the repository at https://github.com/MiniMax-AI/MiniMax-M1, which hosts checkpoints for both the 40K and 80K token budget variants, as well as integration examples for common ML frameworks such as PyTorch and TensorFlow .
API endpoints and cloud integration
Beyond local deployment, MiniMaxAI has partnered with major cloud providers to offer managed API services. Through these partnerships, developers can call MiniMax-M1 via RESTful endpoints, with SDKs available for Python, JavaScript, and Java. The APIs include configurable parameters for context length, expert routing thresholds, and token budgets, allowing users to tailor performance to their use cases while monitoring compute consumption in real time .
How to integrate and use MiniMax-M1 in real applications?
Leveraging MiniMax-M1’s capabilities requires understanding its API patterns, best practices for long-context prompts, and strategies for tool orchestration.
Basic API usage example
A typical API call involves sending a JSON payload containing the input text and optional configuration overrides. For instance:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
The response returns a structured JSON with generated text, token usage statistics, and routing logs, enabling fine-grained monitoring of expert activations .
Tool use and MiniMax Agent
Alongside the core model, MiniMaxAI has introduced MiniMax Agent, a beta agent framework that can call external tools—ranging from code execution environments to web scrapers—under the hood. Developers can instantiate an agent session that chains model reasoning with tool invocation, for example, to retrieve real-time data, perform computations, or update databases. This agent paradigm simplifies end-to-end application development, allowing MiniMax-M1 to function as the orchestrator in complex workflows .
Best practices and pitfalls
- Prompt engineering for long contexts: Break inputs into coherent segments, embed summaries at logical intervals, and utilize “summarize then reason” strategies to maintain model focus.
- Compute vs. performance trade-offs: Experiment with lower expert thresholds or reduced thinking budgets (e.g., the 40K variant) for latency-sensitive applications.
- Monitoring and governance: Use routing logs and token statistics to audit expert utilization and ensure compliance with cost budgets, especially in production environments.
By following these guidelines, developers can harness MiniMax-M1’s strengths—vast context handling and efficient reasoning—while mitigating risks associated with large-scale model deployments.
How do you use MiniMax-M1?
Once installed, M1 can be invoked via simple Python scripts or interactive notebooks.
What Does a Basic Inference Script Look Like?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))This sample invokes the 40 k-budget variant; swapping to "MiniMax-AI/MiniMax-M1-80k" unlocks the full 80 k reasoning budget ([github.com][6]).
How Do You Handle Ultra-Long Contexts?
For inputs exceeding typical buffer sizes, M1 supports streaming tokenization. Use the stream=True flag in the tokenizer to feed tokens in chunks, and leverage checkpoint-restart inference to maintain performance over million-token sequences.
How Can You Fine-Tune or Adapt M1?
While the base checkpoints are sufficient for most tasks, researchers can apply RL fine-tuning using the CISPO code included in the repository. By supplying custom reward functions—ranging from code correctness to semantic fidelity—practitioners can adapt M1 to domain-specific workflows.
Conclusion
MiniMax-M1 stands out as a groundbreaking AI model, pushing the boundaries of long-context language understanding and reasoning. With its hybrid MoE architecture, lightning attention mechanism, and CISPO-backed training regimen, the model delivers high performance on tasks ranging from legal analysis to software engineering, all while dramatically reducing computational expense. Thanks to its open-weight release and cloud API offerings, MiniMax-M1 is accessible to a broad spectrum of developers and organizations eager to build next-generation AI-powered applications. As the AI community continues to explore the potential of large-context models, MiniMax-M1’s innovations are poised to influence future research and product development across the industry.
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—including ChatGPT family—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
To begin, explore models’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key.
The latest integration MiniMax‑M1 API will soon appear on CometAPI, so stay tuned!While we finalize MiniMax‑M1 Model upload, explore our other models on the Models page or try them in the AI Playground. MiniMax’s latest Model in CometAPI are Minimax ABAB7-Preview API and MiniMax Video-01 API ,refer to: