
How to Get Started with Gemini 2.5 Flash-Lite via CometAPI

Starting with Gemini 2.5 Flash-Lite via CometAPI is an exciting opportunity to harness one of the most cost-efficient, low-latency generative AI models available today. This guide combines the latest announcements from Google DeepMind, detailed specifications from the Vertex AI documentation, and practical integration steps using CometAPI to help you get up and running quickly and effectively.
What is Gemini 2.5 Flash-Lite and why should you consider it?
Overview of the Gemini 2.5 family
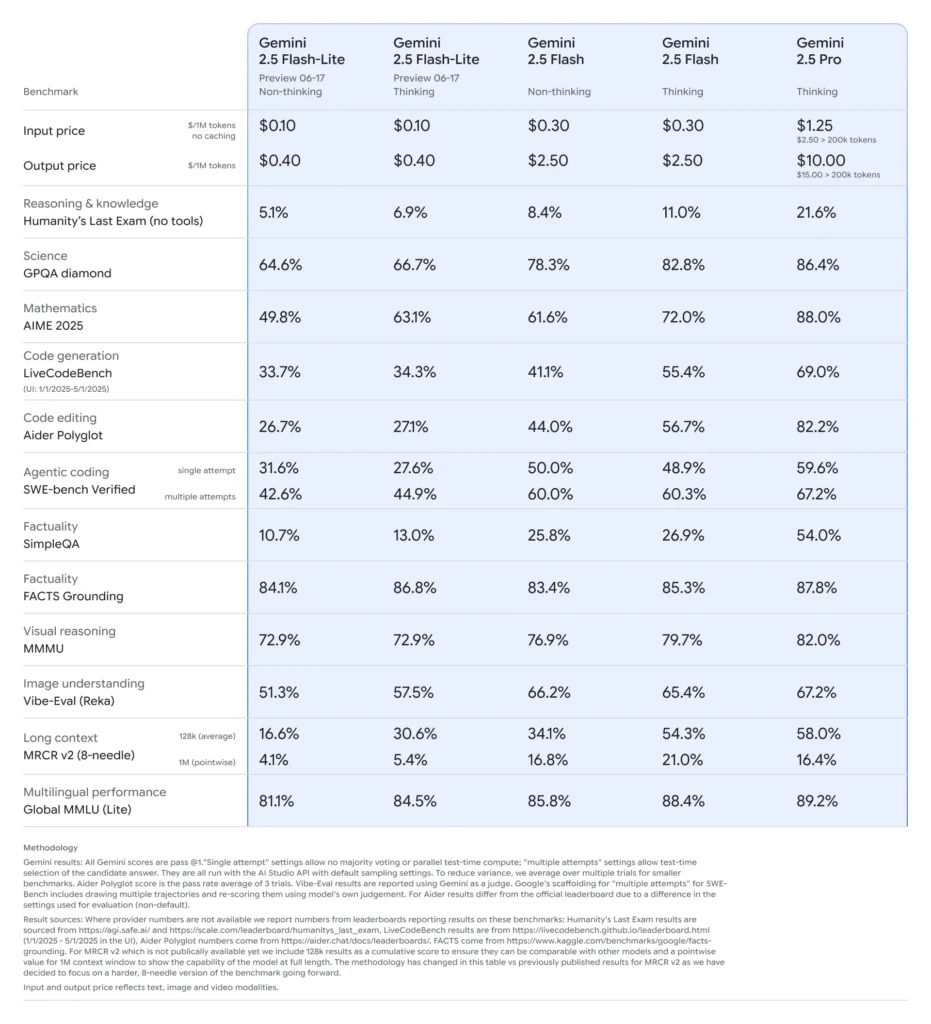
In mid-June 2025, Google DeepMind officially released the Gemini 2.5 series, including stable GA versions of Gemini 2.5 Pro and Gemini 2.5 Flash, alongside the preview of an all-new, lightweight model: Gemini 2.5 Flash-Lite. Designed to balance speed, cost, and performance, the 2.5 series represents Google’s push to cater to a broad spectrum of use cases—from heavy-duty research workloads to large-scale, cost-sensitive deployments .
Key characteristics of Flash-Lite
Flash-Lite distinguishes itself by offering multi-modal capabilities (text, images, audio, video) at extremely low latency, with a context window supporting up to one million tokens and tool integrations including Google Search, code execution, and function calling . Critically, Flash-Lite introduces “thought budget” control, allowing developers to trade off depth of reasoning against response time and cost by adjusting an internal token budget parameter .
Positioning in the model lineup
When compared to its siblings, Flash-Lite sits at the Pareto frontier of cost-efficiency: priced at approximately $0.10 per million input tokens and $0.40 per million output tokens during preview, it undercuts both Flash (at $0.30/$2.50) and Pro (at $1.25/$10) while retaining most of their multi-modal prowess and function-calling support. This makes Flash-Lite ideal for high-volume, low-complexity tasks such as summarization, classification, and lightweight conversational agents.
Why should developers consider Gemini 2.5 Flash-Lite?
Performance benchmarks and real-world tests
In head-to-head comparisons, Flash-Lite demonstrated:
- 2× faster throughput than Gemini 2.5 Flash on classification tasks.
- 3× cost savings for summarization pipelines at enterprise scale.
- Competitive accuracy on logic, math, and code benchmarks, matching or exceeding earlier Flash-Lite previews.
Ideal use cases
- High-volume chatbots: Deliver consistent, low-latency conversational experiences across millions of users.
- Automated content generation: Scale document summarization, translation, and micro-copy creation.
- Search‐and‐recommendation pipelines: Leverage rapid inference for real-time personalization.
- Batch data processing: Annotate large datasets with minimal compute costs.
How do you obtain and manage API access for Gemini 2.5 Flash-Lite via CometAPI?
Why use CometAPI as your gateway?
CometAPI aggregates over 500 AI models—including Google’s Gemini series—under a unified REST endpoint, simplifying authentication, rate limiting, and billing across providers . Rather than juggling multiple base URLs and API keys, you point all requests to https://api.cometapi.com/v1, specify the target model in the payload, and manage usage through a single dashboard.
Prerequisites and signup
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Managing your tokens and quotas
CometAPI’s dashboard provides unified token quotas that can be shared across Google, OpenAI, Anthropic, and other models. Use the built-in monitoring tools to set usage alerts and rate limits so you never exceed budgeted allocations or incur unexpected charges.
How do you configure your development environment for CometAPI integration?
Installing required dependencies
For Python integration, install the following packages:
pip install openai requests pillow
- openai: Compatible SDK for communicating with CometAPI.
- requests: For HTTP operations such as downloading images.
- pillow: For image handling when sending multi-modal inputs.
Initializing the CometAPI client
Use environment variables to keep your API key out of source code:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
This client instance can now target any supported model by specifying its ID (e.g., gemini-2.5-flash-lite-preview-06-17) in your requests .
Configuring thought budget and other parameters
When you send a request, you can include optional parameters:
- temperature/top_p: Control randomness in generation.
- candidateCount: Number of alternative outputs.
- max_tokens: Output token cap.
- thought_budget: Custom parameter for Flash-Lite to trade off depth for speed and cost.
What does a basic request to Gemini 2.5 Flash-Lite via CometAPI look like?
Text-only example
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices[0].message.content)
This call returns a succinct summary in under 200 ms, ideal for chatbots or real-time analytics pipelines .
Multi-modal input example
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[img, "Describe the process illustrated in this diagram."],
max_tokens=200,
)
print(response.choices[0].message.content)
Flash-Lite processes up to 7 MB images and returns contextual descriptions, making it suitable for document understanding, UI analysis, and automated reporting .
How can you leverage advanced features such as streaming and function calling?
Streaming responses for real-time applications
For chatbot interfaces or live captioning, use the streaming API:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[{"role": "user", "content": "Translate this text into Japanese."}],
):
print(chunk.choices[0].delta.content, end="")
This delivers partial outputs as they become available, reducing perceived latency in interactive UIs .
Function calling for structured data output
Define JSON schemas to enforce structured responses:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required": ["entities"]
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=["List the key technologies mentioned in this paragraph."],
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices[0].message.function_call.arguments)
This approach guarantees JSON-compliant outputs, simplifying downstream data pipelines and integrations .
How do you optimize performance, cost, and reliability when using Gemini 2.5 Flash-Lite?
Thought budget tuning
Flash-Lite’s thought budget parameter lets you dial in the amount of “cognitive effort” the model expends. A low budget (e.g., 0) prioritizes speed and cost, while higher values yield deeper reasoning at the expense of latency and tokens .
Managing token limits and troughput
- Input tokens: Up to 1,048,576 tokens per request.
- Output tokens: Default limit of 65,536 tokens.
- Multimodal inputs: Up to 500 MB across image, audio, and video assets .
Implement client-side batching for high-volume workloads and leverage CometAPI’s auto-scaling to handle burst traffic without manual intervention .
Cost-efficiency strategies
- Pool low-complexity tasks on Flash-Lite while reserving Pro or standard Flash for heavy-duty jobs.
- Use rate limits and budget alerts in the CometAPI dashboard to prevent runaway spending.
- Monitor usage by model ID to compare cost per request and adjust your routing logic accordingly .
What are best practices and next steps after initial integration?
Monitoring, logging, and security
- Logging: Capture request/response metadata (timestamps, latencies, token usage) for performance audits.
- Alerts: Set up threshold notifications for error rates or cost overruns in CometAPI.
- Security: Rotate API keys regularly and store them in secure vaults or environment variables .
Common usage patterns
- Chatbots: Use Flash-Lite for rapid user queries and fall back to Pro for complex follow-ups.
- Document processing: Batch PDF or image analyses overnight at a lower budget setting.
- Real-time analytics: Stream financial or operational data for instant insights via the streaming API .
Exploring further
- Experiment with hybrid prompting: combine text and image inputs for richer context.
- Prototype RAG (Retrieval-Augmented Generation) by integrating vector search tools with Gemini 2.5 Flash-Lite.
- Benchmark against competitor offerings (e.g., GPT-4.1, Claude Sonnet 4) to validate cost and performance trade-offs .
Scaling in production
- Leverage CometAPI’s enterprise tier for dedicated quota pools and SLA guarantees.
- Implement blue-green deployment strategies to test new prompts or budgets without disrupting live users.
- Regularly review model usage metrics to identify opportunities for further cost savings or quality improvements .
Getting Started
CometAPI provides a unified REST interface that aggregates hundreds of AI models—under a consistent endpoint, with built-in API-key management, usage quotas, and billing dashboards. Instead of juggling multiple vendor URLs and credentials.
Developers can access Gemini 2.5 Flash-Lite (preview) API(Model: gemini-2.5-flash-lite-preview-06-17
In just a few steps, you can integrate Gemini 2.5 Flash-Lite via CometAPI into your applications, unlocking a powerful combination of speed, affordability, and multi-modal intelligence. By following the guidelines above—covering setup, basic requests, advanced features, and optimization—you’ll be well-positioned to deliver next-generation AI experiences to your users. The future of cost-efficient, high-throughput AI is here: get started with Gemini 2.5 Flash-Lite today.


