
Grok 4 Fast API launch: 98% cheaper to run, built for high-throughput search

xAI announced Grok 4 Fast, a cost-optimized variant of its Grok family that the company says delivers near-flagship benchmark performance while slashing the price to achieve that performance by 98% compared with Grok 4. The new model is designed for high-throughput search and agentic tool use, and includes a 2-million-token context window and separate “reasoning” and “non-reasoning” variants to let developers tune compute to their needs.
Core features and benefits
Cost-effective inference model: Grok 4 Fast is built from the Grok 4 family with a focus on token efficiency and real-time tool use. xAI reports that the model requires roughly 40% fewer “thinking” tokens on average. Artificial Analysis — which tracks latency, output speed and price/performance across many public models — places Grok 4 Fast highly on its intelligence vs. cost frontiers and confirms the model’s rapid output speeds and favorable cost ratio in early tests.
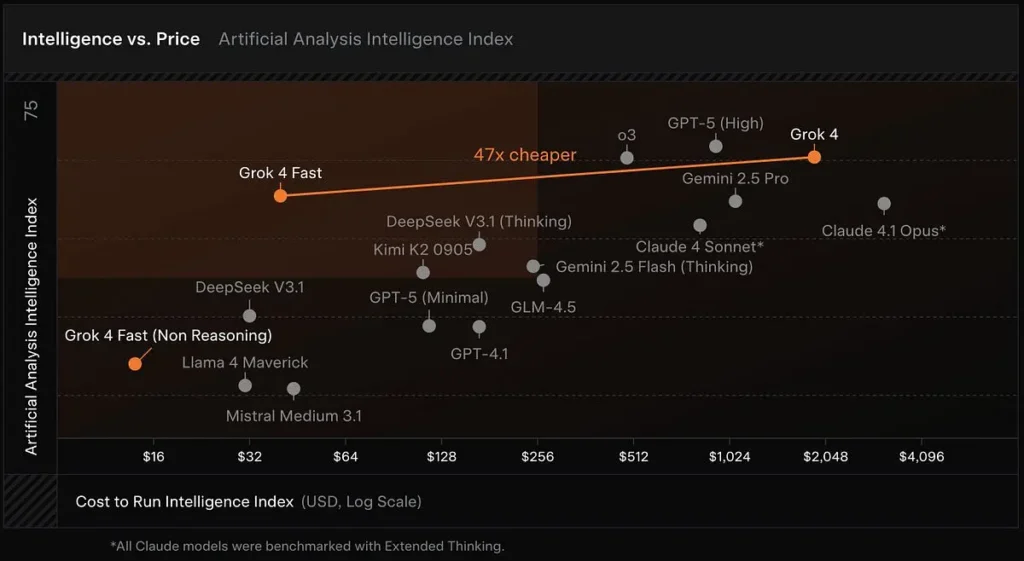
Large context windows: Grok 4 Fast is designed for high-throughput search and agentic tool use, and includes a 2-million-token context window and separate “reasoning” and “non-reasoning” variants to let developers tune compute to their needs.
Native tool-use capabilities: Grok 4 Fast provides “cutting-edge web and X search capabilities” that improve retrieval, navigation and synthesis of web content during agentic workflows — positioning Grok 4 Fast as a practical search tool for applications that require real-time information gathering and reasoning across long documents, Leading performance on multiple search benchmarks, including:
- BrowseComp (zh): 51.2% (vs. Grok 4’s 45.0%)
- X Bench Deepsearch (zh): 74.0% (vs. Grok 4’s 66.0%)
Unified Architecture: The same model supports both inference and non-inference modes, eliminating the need for separate model switching. Reduced latency and cost make it suitable for real-time applications (such as search, question answering, and research assistance).
Performance comparison (main benchmarks)
In private LMArena testing that xAI shared, the grok-4-fast-search (codename menlo) variant tops the Search Arena with an Elo rating of 1,163, while the text variant (tahoe) sits in the top ten of the Text Arena — results xAI uses to support its claims around search performance.
Grok 4 Fast matching or closely trailing Grok 4 on multiple frontier benchmarks (for example: GPQA Diamond, AIME 2025 and HMMT 2025), while outperforming previous smaller models on reasoning tasks — evidence xAI uses to justify the “comparable performance” claim.
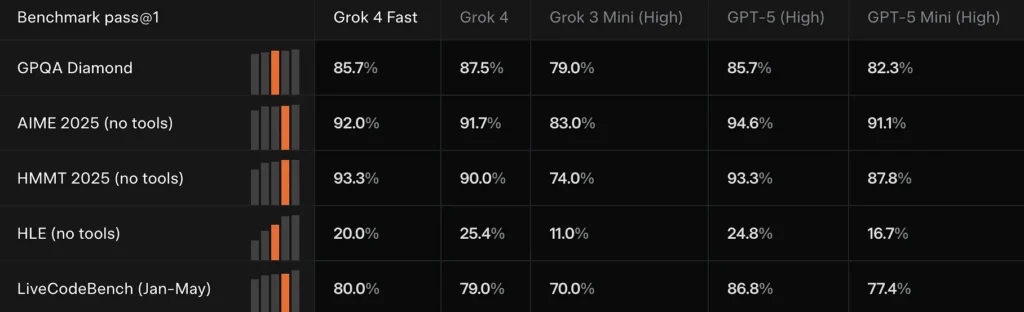
Compare results
Compared to Grok 4: Cheaper and less computationally intensive, but with similar performance.
Compared to Grok 3 Mini: More powerful, capable of complex reasoning and real-time search.
Compared to GPT-5/Gemini/Claude: Thanks to its extremely high token efficiency and tooling capabilities, it leads in cost-effectiveness and some search tasks.
Pricing & availability
Context & tokens: Two model flavors: grok-4-fast-reasoning and grok-4-fast-non-reasoning, each with 2M context.
Published (list) pricing in launch post (example tiers):
- Input tokens: $0.20 / 1M (<128k) — $0.40 / 1M (≥128k)
- Output tokens: $0.50 / 1M (<128k) — $1.00 / 1M (≥128k)
- Cached input tokens: $0.05 / 1M.
(See xAI announcement for exact billing rules and any time-limited promotions.)
Provider availability: xAI lists short-term free availability via OpenRouter and Vercel AI Gateway and general availability via xAI’s API.
What that means for users & teams
- Big cost savings for production use — the combination of lower per-token pricing and fewer “thinking” tokens means teams can run more queries or larger-context workflows at a small fraction of the cost of Grok 4, which materially lowers barriers for experimentation and scaled deployments. (Claim supported by xAI cost/performance disclosures and third-party cost analyses.)
- Works with very long documents and multi-step reasoning — 2M tokens make it practical to ingest entire books, large codebases, or long legal/technical dossiers in a single session, improving accuracy and coherence for tasks that require long-range context (document search, summarization, long-form code generation, research assistants).
- Faster, lower-latency outputs for interactive applications — being a “Fast” variant, it’s engineered for quicker token throughput and lower latency, which benefits chat UIs, coding assistants, and real-time agent loops where responsiveness matters. (Artificial Analysis and provider benchmarks emphasize output speed as a differentiator.)
- Good price/performance for benchmarked reasoning tasks — for teams that judge models by frontier academic benchmarks, Grok 4 Fast offers a strong compromise: near-frontier accuracy at dramatically lower cost, making it attractive for research labs and companies that run expensive benchmark suites frequently.
Conclusion:
Grok 4 Fast positions xAI to compete on price-to-performance and for search-centric agent applications. If the company’s efficiency and verification claims hold up in independent, domain-specific tests, Grok 4 Fast could reshape cost expectations for high-capability, tool-enabled LLM deployments — particularly for applications that rely on live web retrieval and multi-step tool use.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access Grok-4-fast ( model: grok-4-fast-reasoning” / “grok-4-fast-reasoning
Ready to Go?→ Sign up for CometAPI today !


