
Accessing GPT-5 via CometAPI: a practical up-to-step guide for developers

OpenAI’s GPT-5 launched in early August 2025 and quickly became available through multiple delivery channels. One of the fastest ways for teams to experiment with GPT-5 without switching vendor SDKs is CometAPI — a multi-model gateway that exposes GPT-5 alongside hundreds of other models. This article s hands-on documentation to explain what CometAPI offers, how to call GPT-5 through it, the trade-offs you should evaluate, and practical governance and cost controls to put in place before you move critical workflows onto GPT-5.
What is GPT-5 and what makes it different from earlier models?
GPT-5 is OpenAI’s next flagship large language model family released in early August 2025. It’s presented as a unified, multimodal reasoning system that combines fast non-reasoning components, a deeper “reasoning” variant (often referenced as “GPT-5 thinking”), and a router that decides which submodel to use based on complexity and tools required. The net effect claimed by OpenAI: better reasoning, larger context windows, and improved support for coding and agentic tasks.
Architecture and key capabilities
- Multi-component system: GPT-5 is described as a system that routes requests to different internal submodels (fast vs. deep reasoning) depending on need; developers can request the reasoning model via the API for maximum performance.
- Large context: The model family supports extremely large contexts (hundreds of thousands of tokens), enabling single-pass handling of long documents, codebases, or multi-file conversations.
- Multi-size family: OpenAI released GPT-5 in multiple sizes (regular
gpt-5,gpt-5-mini,gpt-5-nano) so teams can trade off latency, cost, and reasoning power.
What is CometAPI and does it actually offer GPT-5?
A quick definition
CometAPI is an API-aggregation platform that advertises unified access to hundreds of AI models (OpenAI’s GPT families, Anthropic Claude, xAI Grok, image models, and more) through a single, OpenAI-compatible REST interface. That means developers can switch model providers by changing a model name string rather than rewriting networking code. On its product pages, CometAPI explicitly lists GPT-5 and related variants (e.g., gpt-5, gpt-5-chat-latest, gpt-5-mini) as available endpoints.
Why teams use gateways like CometAPI
Gateway services like CometAPI are attractive because they let you:
- Swap models quickly without changing large amounts of integration code.
- Compare prices and route certain requests to cheaper or faster model variants.
- Aggregate billing and logging across multiple models and vendors.
CometAPI’s docs provide a simple migration path and an OpenAI-style client (so your existing OpenAI or “openai-compatible” code often needs only minor changes).
How does CometAPI expose GPT-5 programmatically?
CometAPI presents an OpenAI-compatible REST API surface: a base URL, Authorization: Bearer <YOUR_KEY>, and request bodies similar to OpenAI’s chat/completions endpoints. For GPT-5 the platform documents model names such as gpt-5, gpt-5-mini, and gpt-5-nano and Endpoints mentioned include POST https://api.cometapi.com/v1/chat/completions for chat-style calls and /v1/responses for some non-chat variants. Example configuration details (base URL, header format, and model parameter) are published in CometAPI docs and quick-start guides.
Typical endpoint and authentication pattern
- Base URL:
https://api.cometapi.com/v1(or the documented/v1/chat/completionsfor chat and/v1/responsesfor some non-chat variants.). - Auth header:
Authorization: Bearer sk-xxxxxxxxxxxx(CometAPI issuessk-style tokens in the dashboard ). - Content type:
application/json. - Model parameter: set
modeltogpt-5, gpt-5-2025-08-07,gpt-5-chat-latest,gpt-5-minior others,refer to model page.
How do I get started with CometAPI and request GPT-5? (step-by-step)
Below is a concise, reliable onboarding flow you can follow today.
Step 1: Sign up and obtain a CometAPI key
- Go to cometapi.com and create an account.
- From your dashboard go to API Tokens or Personal Center → Add Token. CometAPI issues a token in
sk-...format. Store this securely (do not embed keys in public repos).
Step 2: Choose the model string
- Select the model name that matches your needs (e.g.,
gpt-5,gpt-5-nano-2025-08-07). CometAPI often publishes multiple aliases for each model so you can choose accuracy vs cost tradeoffs.
Step 3: Make your first request (curl)
A minimal curl example that follows the OpenAI-compatible pattern:
curl -X POST "https://api.cometapi.com/v1/chat/completions" \
-H "Authorization: Bearer sk-YOUR_COMETAPI_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-5",
"messages": [{"role":"system","content":"You are a helpful assistant."},
{"role":"user","content":"Summarize the benefits of using a model aggregator."}],
"max_tokens": 500,
"temperature": 0.2
}'
This mirrors OpenAI’s chat API structure, but points to CometAPI’s base URL and uses your Comet token.
Step 4: Python example (requests)
import requests, os
COMET_KEY = os.getenv("COMETAPI_KEY") # set this in your environment
url = "https://api.cometapi.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {COMET_KEY}",
"Content-Type": "application/json",
}
payload = {
"model": "gpt-5",
"messages": [
{"role":"system","content":"You are a helpful assistant."},
{"role":"user","content":"List three concrete steps to reduce model hallucination in production."}
],
"max_tokens": 400,
"temperature": 0.1
}
resp = requests.post(url, json=payload, headers=headers, timeout=60)
resp.raise_for_status()
print(resp.json())
Replace model with gpt-5-nano or the exact alias CometAPI documents for smaller, cheaper variants.
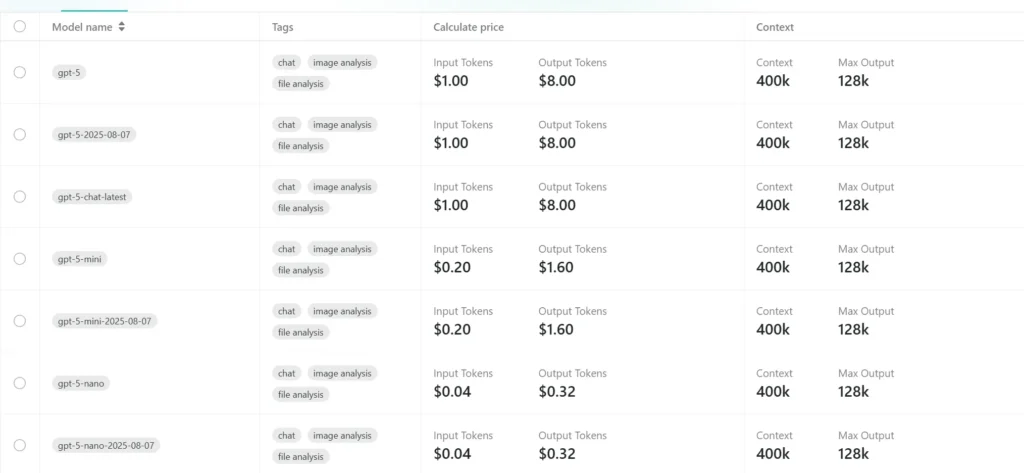
Price in CometAPI
What are practical best practices and mitigations for production use?
Below are concrete patterns to reduce risk and improve reliability when you use an intermediary like CometAPI.
Start with a small pilot and run side-by-side tests
Run identical requests to OpenAI (if you have direct access) and CometAPI to compare outputs, latency, and cost. That reveals any implicit transformations, content filters, or model alias mismatches.
Instrument for observability and QA
Log prompts, returned tokens (obfuscated for PII), latencies, and error codes. Implement automated tests for prompt-drift and hallucination rates. Track model alias usage so migrations are auditable.
Safeguard keys and rotate regularly
Treat CometAPI tokens like any API secret: store in secrets managers, rotate periodically, and scope tokens to environments (dev/stage/prod).
Implement layered safety
Use a combination of:
- Prompt engineering to reduce hallucinations (explicit constraints, structured output).
- Post-processing checks (fact verification, block lists, regex checks for PII).
- Human in the loop for high-risk outputs.
These are standard for GPT-5 deployments that handle critical or legal content.
What are common pitfalls and how do you troubleshoot access problems?
Pitfall: “model does not exist / no access.” Some developers report that model access can be gated by provider verification or org verification steps when using direct provider APIs; similar restrictions can appear when aggregators proxy provider models. If you see a “model does not exist” or permission error, check: (a) whether your CometAPI key is valid and not expired, (b) whether the requested model name exactly matches CometAPI’s supported list, and (c) whether there are additional verification or billing steps required by the underlying provider. Or verification-related access errors and timeout/permission anomalies—be prepared to supply details to Contact staff to resolve(email: support@cometapi.com).
Pitfall: unexpected latency or cost. High-reasoning modes and large contexts cause latency and token spend. Use max_tokens, reduce temperature where appropriate, and prefer mini variants for high throughput workloads. Monitor with logging and alerting.
Closing note
CometAPI gives teams a fast route to experiment with GPT-5 variants while centralizing model access, but production usage demands the same discipline you’d apply to any powerful model: secure keys, careful prompt engineering, monitoring for hallucination, and policy/legal review for sensitive workloads. Start with a small pilot, use CometAPI’s dashboards to measure token spend and latency, and escalate to higher-reasoning variants only after validating accuracy and safety for your domain.
Developers can access GPT-5 , GPT-5 Nano and GPT-5 Mini through CometAPI (CometAPI recommends /v1/responses) , the latest models version listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
See Also How to Use GPT-5’s new parameters and tools
FAQs
1.Which GPT-5 model variant should you choose and what about tokens/pricing?
CometAPI lists multiple GPT-5 variants (default gpt-5, chat snapshots like gpt-5-chat-latest, and smaller versions such as gpt-5-mini/gpt-5-nano). Choose according to your needs:
gpt-5/gpt-5-chat-latest— full capability for general-purpose chat, best for quality and reasoning.gpt-5-mini/gpt-5-nano— lower cost and latency for high-volume or lower-criticality tasks.
2. How should you architect calls for large contexts and high-quality reasoning?
Long context: GPT-5 supports very large context windows. When sending large documents, chunk input deliberately, use retrieval augmentation (vector DB + context windowing), and keep max_tokens for outputs bounded to control cost.
3. What security, privacy, and compliance measures should you apply?
API key hygiene. Keep keys in environment variables, rotate them regularly, and scope them when possible. Do not commit keys to repositories. (Best practice echoed across developer guides.)
Data residency & privacy. Read CometAPI’s privacy policy and terms (and OpenAI’s policy) before sending sensitive personal, health, or regulated data through any third-party aggregator. Some enterprises will require direct vendor contracts or private instances.
Rate limits and quota protections. Implement circuit breakers, exponential backoff, and quota checks in production to prevent runaway costs and cascading failures. CometAPI dashboards expose usage and quotas—use them to enforce programmatic limits.


