
Which is the best image-editing AI in 2025?

Image-editing AI has moved from fun toy to actual workflow tool in months — not years. If you need to remove backgrounds, swap faces, preserve a character across shots, or do multi-step compositing with natural-language prompts, several new models promise to do it faster and with fewer manual fixes.. In this post I compare three of the tools people are talking about right now: OpenAI’s GPT-image-1, Qwen-Image Edit,the viral Nano Banana models (Gemini-2.5-Flash-Image), and Flux Kontext. I’ll walk through what each one is good at, where they fall short, and give a practical recommendation depending on what you want to accomplish.
What are the Core Capabilities Defining Excellence in Image AI?
“Best” depends on what you need. My evaluation uses seven practical criteria,Before we dissect individual models, it’s crucial to understand the fundamental capabilities that define excellence in image generation and editing AI. These can broadly be categorized into:
- Generation Quality and Fidelity: This refers to the AI’s ability to produce highly realistic, aesthetically pleasing, and coherent images from text prompts. Factors include detail, lighting, composition, and the absence of artifacts or distortions.
- Editing Versatility and Precision: Beyond initial generation, a superior AI should offer robust editing functionalities. This includes inpainting (filling missing parts), outpainting (extending images), object removal/addition, style transfer, and precise control over specific elements.
- Speed and Efficiency: For professional workflows, the time taken to generate or edit images is paramount. Faster processing without sacrificing quality is a significant advantage.
- User Experience and Accessibility: An intuitive interface, clear controls, and ease of integration into existing workflows are vital for widespread adoption and user satisfaction.
- Ethical Considerations and Safety Features: As AI becomes more powerful, responsible development and deployment are crucial. This includes safeguards against generating harmful or biased content.
- Cost-Effectiveness and Pricing Models: While some tools offer free tiers, understanding the pricing structure for advanced features and commercial use is essential for budget-conscious users.
- Consistent multi-step edits — preserving identity/objects across multiple edits or images.
I lean practical: a model that produces slightly less “wow-factor” imagery but lets you get reproducible, fast, reliable edits will beat a flashy one that needs lots of cleanup.
What are the models under consideration and what makes them different?
Quick model snapshot
- gpt-image-1 (OpenAI) — a natively multimodal model released to API in April 2025 that directly supports iterative image generation and editing inside the same multimodal Responses/Images API.
- Gemini 2.5 Flash Image (Google) — announced Aug 26, 2025 (“nano-banana”); designed for fast, low-latency generation and rich editing (multi-image fusion, character consistency) ; includes SynthID watermarking for provenance.
- Qwen-Image-Edit (QwenLM / Alibaba group) — an image-editing version of Qwen-Image (20B foundation) emphasizing bilingual, precise text edits and combined semantic + appearance editing.
- FLUX.1 Kontext (Flux / Black Forest Labs / Flux platform variants) — family of models (Dev / Pro / Max) focused on fast, local, context-aware editing with character consistency and iterative workflows.
Why these four?
They cover the most relevant design points practitioners ask about in 2025: multimodal integration (OpenAI), scale + production plus world knowledge (Google), precision editing & open research (Qwen), and UX-first iterative editing (Flux). Each has different trade-offs in cost, latency, and where they shine (text rendering, multi-image fusion, iterative editing, preservation of unchanged areas).
GPT-Image-1 (OpenAI) — the developer’s heavy lifter
What it is: OpenAI’s GPT-Image-1 is a natively multimodal model that accepts both text and image inputs and supports generation and image edits (inpainting, image-to-image) via their Images API. It’s positioned as a production-grade model for integration across apps and services.It’s designed as a native text+image model that can accept image inputs and text prompts and perform edits with fine control.
What are the Strengths of GPT-image-1?
- Exceptional Semantic Understanding: One of GPT-image-1’s primary strengths lies in its ability to interpret nuanced and elaborate text prompts. Users can describe intricate scenes, specific moods, and abstract concepts with remarkable accuracy, and the AI often produces images that faithfully reflect these descriptions.
- High-Quality Photorealism: When prompted for realistic images, GPT-image-1 frequently delivers outputs that are strikingly lifelike, with impressive attention to textures, lighting, and natural compositions. This makes it a formidable tool for photorealistic rendering and concept art.
- Creative Interpretation: Beyond mere literal translation, GPT-image-1 exhibits a degree of creative interpretation, often adding subtle details or stylistic flourishes that enhance the overall artistic appeal of the generated image. This can be particularly beneficial for ideation and exploring diverse visual concepts.
- Strong Foundation for Iteration: Its ability to generate high-quality initial concepts provides an excellent starting point for further refinement, either within the AI’s editing capabilities (if available) or through traditional graphic design software.
What are the Limitations of GPT-image-1?
- Control over Fine Details: While excellent at broad concepts, achieving absolute pixel-level control or precise manipulation of very small elements can sometimes be challenging. This is a common hurdle for many generative AIs, where the output is somewhat deterministic based on the prompt.
- Availability and Integration: Depending on its specific implementation, GPT-image-1’s direct editing features might be less robust or integrated compared to dedicated image editing platforms. Users might need to export and use other tools for intensive post-generation editing.
- Computational Demands: Generating highly detailed images with complex prompts can be computationally intensive, potentially leading to longer processing times compared to more specialized, lighter models for quick edits.
Nano Banana (Google / Gemini 2.5 Flash Image)
What it is: “Nano Banana” is the playful name given to Google’s recent Gemini image upgrade (Gemini 2.5 Flash Image). It’s been positioned as a next-gen image generator/editor within Google’s Gemini ecosystem, marketed for stronger, more nuanced multi-step edits and superior consistency on photograph edits.
Where Does Gemini-2.5-Flash-Image Shine in the Visual AI Landscape?
Gemini-2.5-Flash-Image, a more recent iteration designed for speed and efficiency, is Google’s contender aiming for a balance between high-quality output and rapid processing. Its “Flash” designation specifically points to its optimized architecture for quicker responses, making it highly suitable for applications where real-time or near real-time generation and editing are crucial.
What Makes Gemini-2.5-Flash-Image a Strong Contender?
- Blazing Fast Generation: As its name suggests, speed is a core advantage. Gemini-2.5-Flash-Image excels at generating images rapidly, which is invaluable for creative professionals on tight deadlines or for interactive applications.
- Solid Image Quality: Despite its speed, the model does not significantly compromise on image quality. It produces coherent, visually appealing images that are generally free from major artifacts, making it competitive with slower, more resource-intensive models for many use cases.
- Multimodal Understanding: Leveraging the broader Gemini framework, it often benefits from advanced multimodal understanding, meaning it can potentially interpret not just text but also other forms of input to guide image generation and editing, though this varies by specific API.
- Integrated Editing Capabilities: Gemini-2.5-Flash-Image typically comes with integrated editing features such as inpainting (filling in missing parts of an image), outpainting (extending an image beyond its original borders), and object manipulation, making it a more complete solution for end-to-end image workflows.
What are the Areas for Improvement for Gemini-2.5-Flash-Image?
- Peak Photorealism: While good, it might not always reach the absolute pinnacle of photorealism seen in some of the slower, larger models for highly intricate and nuanced scenes. There can be a slight trade-off between speed and ultimate fidelity.
- Artistic Nuance for Complex Styles: For highly specific artistic styles or extremely abstract requests, some users might find it slightly less capable of capturing the most subtle artistic nuances compared to models trained on vast art historical datasets.
- Control over Generated Text (within images): Like many generative models, generating perfectly coherent and correctly spelled text within an image can still be a challenge.
What is Qwen-Image-Edit?
What it is: Qwen-Image-Edit (Alibaba / Qwen team) — image editing model built on the Qwen-Image family; claims strong bilingual text editing (Chinese & English), semantic and appearance control, and direct image edit fidelity.
What are the Unique Strengths of Qwen-Image Edit?
- Superior Editing Precision: Qwen-Image Edit often boasts advanced algorithms for inpainting, outpainting, and object manipulation that allow for highly precise and seamless edits. It excels at maintaining visual coherence even when making significant alterations.
- Context-Aware Editing: A key strength is its context-awareness. When removing an object, for instance, it intelligently fills the void with content that logically blends with the surrounding environment, making the edit virtually undetectable.
- Style Transfer and Harmonization: Qwen-Image Edit can be highly effective in transferring styles from one image to another or harmonizing different elements within an image to create a cohesive look. This is invaluable for designers working with diverse visual assets.
- Robust Object Removal/Addition: Its ability to add or remove objects while maintaining lighting, shadows, and perspective is highly impressive, allowing for complex scene reconstructions or decluttering.
- Image Upscaling and Enhancement: Often includes advanced features for upscaling images without losing quality, and enhancing details, colors, and overall visual appeal.
What are the Potential Weaknesses of Qwen-Image Edit?
- Initial Generation Focus: While it can generate images, its primary strength and optimization are often on editing. Its initial text-to-image generation might be good, but potentially not as creatively diverse or photorealistic as models purely focused on generation, depending on the specific version.
- Learning Curve for Advanced Features: The precision and depth of its editing tools might require a slightly steeper learning curve for users unfamiliar with advanced image manipulation concepts.
- Resource Intensity for Complex Edits: Highly complex, multi-layered edits can still be computationally demanding, potentially leading to longer processing times for very large or intricate tasks.
What Innovations Does Flux Kontext Bring to Image AI?
What it is: Flux’s Kontext (sometimes marketed as FLUX.1 Kontext) is an image editing/generation tool positioned for designers and brand teams. It emphasizes context-aware editing, precise typography, style transfers, and tight UI/UX for iterative design work.
What are the Strengths of Flux Kontext?
- Contextual Cohesion: Flux Kontext’s primary strength is its ability to understand and maintain context across multiple image generations or edits. This is invaluable for creating consistent visual narratives, character designs, or product lines where visual harmony is essential.
- Improved Consistency in Series: If you need to generate a series of images that share a common style, character, or environment, Flux Kontext aims to reduce inconsistencies that can plague other models.
- Adaptive Styling: It can adapt its output based on previously generated images or a defined style guide, leading to a more streamlined and less iterative creative process.
- Specialized for Brand and Narrative: Particularly beneficial for marketing, branding, and storytelling, where a unified visual identity is crucial.
- Prompt Understanding in Context: Its prompt understanding is not just about the current image but how it fits into a larger context or instruction set.
What are the Limitations of Flux Kontext?
- Potential for Niche Focus: Its emphasis on context and consistency might mean it’s not always the absolute leader in raw, standalone photorealism or extreme artistic diversity if that’s the sole requirement.
- Less Publicly Documented Benchmarks: As a newer or more specialized player, extensive public benchmark data might be less available compared to more established models.
- Dependent on Clear Contextual Input: To leverage its strengths, users need to provide clear contextual information or define the narrative framework effectively, which might require a different prompting approach.
Which model is best at image editing ?
For single, precise maskless edits and text editing inside images, Qwen-Image-Edit and Gemini 2.5 Flash Image (and specialized models like FLUX.1 Kontext) are among the strongest. For complex multi-step chained edits, combining an instruction-strong LLM front-end (Gemini or GPT variants) with an image model often yields the best result — some benchmark work has shown Chain-of-Thought style prompting (Gemini-CoT) improves multi-step editing success.
local edits, character consistency, text handling
- Qwen-Image-Edit explicitly targets both semantic and appearance edits — e.g., replace object, rotate, precise text replacement —explicitly built as an image editing model with dual pathways (semantic control via Qwen2.5-VL + appearance control via VAE encoder). It advertises robust bilingual (Chinese/English) text edits in images (e.g., change sign text, product labels) while preserving style, which is rare and valuable for localization and packaging work.
- Gemini 2.5 Flash Image supports masked edits, prompt-driven local modifications (blur background, remove person, change pose), and multi-image fusion. Google advertises prompt-based region-aware edits plus world knowledge advantages (e.g., better real-world object semantics). The model also adds an invisible SynthID watermark to generated/edited images to help provenance and detection.
- FLUX.1 Kontext: positions itself as an image-to-image context solver — it’s optimized for precise, context-aware local edits and iterative experimentation. Reviewers praise its ability to preserve context and scene semantics while making local changes.FLUX.1 Kontext and Flux Kontext UI are praised in head-to-head practical tests for iterative editing workflows and text legibility, making it a practical choice for workflows that need many quick iterations (marketing assets, thumbnails).
- GPT-image-1: supports edit operations (text+image prompts for edits), and OpenAI’s tooling integrates chaining and prompt engineering patterns; performance is strong but depends on prompt engineering and may trail specialized edit-first models in fine-grained editing (e.g., exact bilingual text replacement) in some tests.
Benchmarks such as ComplexBench-Edit and CompBench show that many models still fail when edits are chained or interdependent, but that combining an LLM for instruction parsing with a robust image model (LLM→image model orchestration) or using CoT prompts can reduce failures. That’s why some production workflows stitch models together (e.g., a reasoning LLM plus an image generator) for hard edits.
Who is best at editing text within images?
- Qwen-Image-Edit was explicitly designed for bilingual (Chinese + English) precise text editing and reports superior results in text-editing benchmarks (Qwen public technical notes and reported scores). Open-source Qwen artifacts and demos show accurate font/size/style preservation during edits.
- gpt-image-1 and Gemini 2.5 Flash Image both make progress in text rendering, but academic benchmarks and vendor notes indicate remaining challenges for small/detail text and long textual passages—improvements are incremental and vary by prompt and resolution.
Comparative Analysis: Feature, Editing
To provide a clearer picture, let’s consolidate the key aspects of these leading AI models into a comparative table.
| Feature / Capability | GPT-image-1 (OpenAI) | Gemini-2.5-Flash-Image (Google) | Qwen-Image-Edit (Alibaba) | FLUX.1 Kontext |
|---|---|---|---|---|
| Native generation + edit | Yes. Multimodal text+image in one API. | Yes — native generation & targeted editing; multi-image fusion & character consistency emphasized. | Focused on editing (Qwen-Image-Edit) with semantic + appearance control. | Focused on image-to-image, high-fidelity edits. |
| Editing depth (local adjustments) | High (but generalist) | Very high (targeted prompts + maskless edits) | Very high for semantic/text edits (bilingual text support). | Very high — context-aware edit pipelines. |
| Text-in-image handling | Good, depends on prompt | Improved (vendor shows template and sign editing demos) | Best among these for bilingual readable text changes. | Strong for preserving style; legibility depends on prompt. |
| Character / object consistency | Good with careful prompting | Strong (explicit feature) | Medium (focus is editing rather than multi-image identity) | Strong via iterative editing workflows. |
| Latency / throughput | Moderate | Low latency / high throughput (Flash model) | Varies by hosting (local/HF vs cloud) | Designed for fast iterative edits in hosted SaaS. |
| Provenance / watermarking | No mandatory watermark (policy mechanisms) | SynthID invisible watermark for images. | Depends on host | Depends on host |
Notes: “Editing depth” measures how fine-grained and reliable local edits are in practice; “Text handling” rates ability to place/change readable text inside images
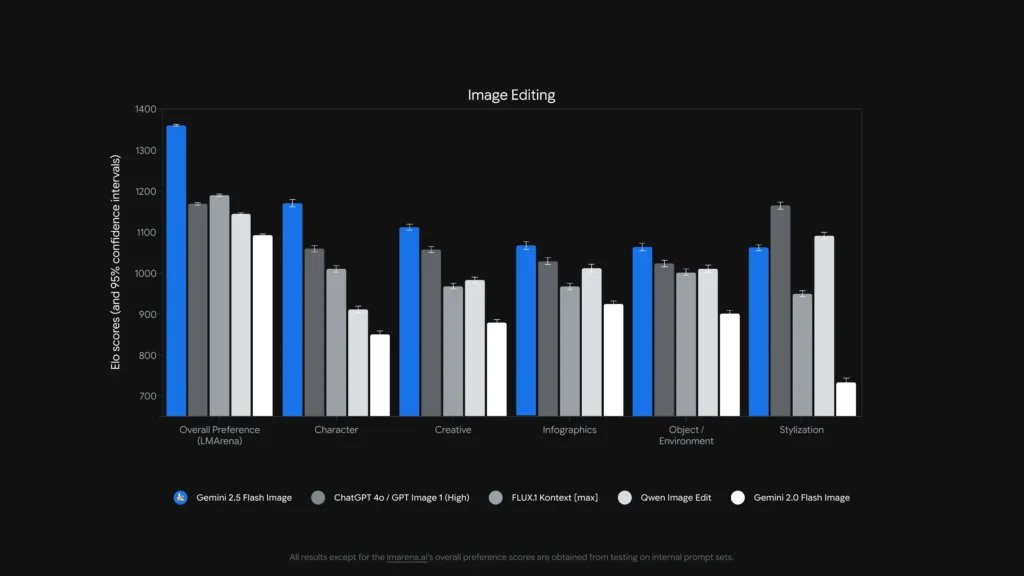
What about latency, developer ergonomics, and enterprise integration?
Latency & deployment options
- Gemini 2.5 Flash Image emphasizes low latency and is available via Gemini API, Google AI Studio, and Vertex AI — a strong pick for enterprise apps that need predictable throughput and cloud integration. Google also reports per-image approximate token pricing (and developer blog includes pricing per image example).
- gpt-image-1 is available via OpenAI Images API and has broad ecosystem integration (Playground, partners like Adobe/Canva). Pricing is tokenized and varies by image quality tier (OpenAI publishes token-to-dollar conversions).
- Flux Kontext is focused on a fast interactive UX and offers credits + low per-edit times in product demos — handy for designers and quick iteration. Qwen provides open artifacts and research access (ideal if you want to self-host or inspect internals).
How much do these services cost — which is better value?
Pricing changes frequently — below are publisher-stated numbers (August 2025) and representative per-image cost calculations where vendors published them.
Published pricing (vendor statements)
| Model / Vendor | Public pricing snapshot (published) | Rough per-image estimate |
|---|---|---|
| gpt-image-1 (OpenAI) | Tokenized pricing (text input $5 / 1M, image input $10 / 1M, image output $40 / 1M). OpenAI notes this maps to roughly $0.02–$0.19 per generated image depending on quality/size. | ~$0.02 (low-quality/thumbnail) → ~$0.19 (high-quality square) |
| Gemini 2.5 Flash Image (Google) | $30 per 1M output tokens and example: each image ≈ 1290 output tokens (~$0.039 per image) according to developer blog. Pricing applied via Gemini API / Vertex. | ~$0.039 per image (Google example) |
| Flux Kontext (Flux) | Free tier with credits; Flux product pages show 10 free credits and typical edits priced at 5 credits; subscription tiers available for heavy users. (Vendor product page). | Very low cost for occasional edits; subscription for heavy use. |
| Qwen-Image-Edit (QwenLM) | Open release and GitHub artifacts—open access for research with free examples; commercial deployments vary by integrator (self-hosted vs cloud). No single canonical per-image price; tends to be lowest if self-hosted. |
Value interpretation: If you need high volume image generation in production and want predictable per-image pricing, Google’s per-image example is extremely competitive. If your costs are dominated by human-in-the-loop editing or iterative designer time, Flux or running Qwen locally may be more economical. OpenAI offers broad SDK ecosystem and many partners, worth the higher tier for integration convenience.
Price in CometAPI
| Model | GPT-image-1 | Gemini-2.5-Flash-Image | FLUX.1 Kontext |
| Price | Input Tokens $8.00; Output Tokens $32.00 | $0.03120 | flux kontext pro: $0.09600 flux-kontext-max: $0.19200 |
Practical quick tips for getting the best results
Prompting & workflow tips (applies to all models)
- Be explicit about composition: camera angle, lighting, mood, focal length, lens, and the spatial relations between objects. Example: “35mm close-up, shallow depth-of-field, subject centered, soft rim light from upper-left.”
- Use iterative refinement for edits: do coarse structural edits first, then follow up with texture/lighting refinements. Models like FLUX and Gemini are built to support multi-step refinement.
- For text in images: supply the exact text you want and add “render as high-contrast legible sign with realistic embossing” — for bilingual edits use Qwen-Image-Edit when you need Chinese/English fidelity.
- Use reference images: for character consistency or product variants, supply high-quality reference images and anchor prompts like “match the character in reference_01: facial features, costume color, and lighting.” Gemini and Flux emphasize multi-image fusion/consistency.
- Masking vs maskless edits: where possible, provide a mask to tightly constrain edits. When maskless is used, expect occasional spillover. Models vary: Flux/Gemini handle maskless edits well, but a mask still helps.
- Use GPT-image / GPT-4o for complex compositional prompts with multiple objects, counts and spatial constraints. Use a single, exact instruction per generation when possible.
Cost & latency tips
Batching: use batch APIs or cloud functions to generate many variants efficiently. Gemini-2.5-Flash is optimized for throughput if you need high volume.
Tune quality vs price: OpenAI exposes low/medium/high image tiers; generate rough drafts at low quality, finalize at high.
Final verdict
- Best for production & integration: GPT-Image-1 — strongest for API needs, compositing, and integration into professional tools.
- Best for consumer photoreal consistency: Nano Banana — Google’s Gemini image upgrade shines at natural, sequential portrait edits and an approachable UX.
- Best mobile/editor experience: Flux Kontext — great conversational edits on phone with low friction.
- If you measure by surgical text edits and bilingual/multilingual editing → Qwen-Image-Edit** is the top specialist, and an excellent choice where text accuracy inside images matters.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google’s Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
Developers can access GPT-image-1, FLUX.1 Kontext and Gemini 2.5 Flash Image through CometAPI, the latest models version listed are as of the article’s publication date. To begin, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Before accessing, please make sure you have logged in to CometAPI and obtained the API key. CometAPI offer a price far lower than the official price to help you integrate.
The latest integration Qwen-Image-Edit will soon appear on CometAPI, so stay tuned!Ready to Get Started editing images? → Sign up for CometAPI today !
Price in CometAPI
| Model | GPT-image-1 | Gemini-2.5-Flash-Image | FLUX.1 Kontext |
| Price | Input Tokens $8.00; Output Tokens $32.00 | $0.03120 | flux kontext pro: $0.09600 flux-kontext-max: $0.19200 |


