
What is GPT-5-Codex? Architecture, Feature, Accesss and More

GPT-5-Codex is OpenAI’s new, engineering-focused variant of GPT-5, tuned specifically for agentic software engineering inside the Codex product family. It’s designed to take on large real-world engineering workflows: creating full projects from scratch, adding features and tests, debugging, refactors, and performing code reviews while interacting with external tools and test suites. This release represents a targeted product refinement rather than a brand-new foundational model: OpenAI has integrated GPT-5-Codex into Codex CLI, the Codex IDE extension, Codex Cloud, GitHub workflows, and ChatGPT mobile experiences; API availability is planned but not immediate.
What is GPT-5-Codex — and why does it exist?
GPT-5-Codex is GPT-5 “specialized for coding.”Instead of being a general conversational assistant, it’s tuned and trained with reinforcement learning and engineering-specific datasets to better support iterative, tool-aided coding tasks (think: run tests, iterate on failures, refactor modules, and follow PR conventions). OpenAI frames it as the successor to earlier Codex efforts but built on the GPT-5 backbone to improve depth of reasoning about large codebases and to perform multi-step engineering tasks more reliably.
The motivation is practical: developer workflows increasingly rely on agents that can do more than single-snippet suggestions. By aligning a model specifically to the loop of “generate → run tests → fix → repeat” and to organizational PR norms, OpenAI aims to make an AI that feels like a teammate rather than a source of one-off completions.That shift from “generate a function” to “ship a feature” is the model’s unique value.
How is GPT-5-Codex architected and trained?
High-level architecture
GPT-5-Codex is a variant of the GPT-5 architecture (the broader GPT-5 lineage) rather than a ground-up new architecture. That means it inherits GPT-5’s core transformer-based design, scaling properties, and reasoning improvements, but adds Codex-specific training and RL-based fine-tuning targeted at software engineering tasks. OpenAI’s addendum describes GPT-5-Codex as trained on complex, real-world engineering tasks and emphasizes reinforcement learning on environments where code is executed and validated.
How was it trained and optimized for code?
GPT-5-Codex’s training regimen emphasizes real-world engineering tasks. It uses reinforcement-learning-style fine-tuning on datasets and environments constructed from tangible software development workflows: multi-file refactors, PR diffs, running test suites, debugging sessions, and human review signals. The training objective is to maximize correctness across code edits, pass tests, and produce review comments that carry high precision and relevance. This focus is what differentiates Codex from general chat-oriented fine-tuning: the loss functions, evaluation harnesses, and reward signals are aligned to engineering outcomes (tests passing, correct diffs, fewer spurious comments).
What “agentic” training looks like
- Execution-driven fine-tuning: The model is trained in contexts where generated code is executed, tested, and evaluated. Feedback loops come from test outcomes and human preference signals, encouraging the model to iterate until a test suite passes.
- Reinforcement learning from human feedback (RLHF): Similar in spirit to prior RLHF work, but applied to multi-step coding tasks (create PR, run tests, fix failures), so the model learns temporal credit assignment over a sequence of actions.
- Repository-scale context: Training and evaluation include large repositories and refactors, helping the model learn cross-file reasoning, naming conventions, and codebase-level impacts. ([OpenAI][5])
How does GPT-5-Codex handle tool use and environment interactions?
A key architectural feature is the model’s improved ability to call and coordinate tools. Codex historically combined model outputs with a small runtime/agent system that can run tests, open files, or call search. GPT-5-Codex extends that by learning when to call tools and by better integrating test feedback into subsequent code generation—effectively closing the loop between synthesis and verification. This is achieved by training on trajectories where the model both issues actions (like “run test X”) and conditions later generations on test outputs and diffs.
What can GPT-5-Codex actually do — what are its features?
One of the defining product innovations is adaptive thinking duration. GPT-5-Codex adjusts how much hidden reasoning it performs: trivial requests run fast and cheaply, while complex refactors or long running tasks allow the model to “think” for much longer. At the same time, for small, interactive turns the model consumes far fewer tokens than a general-purpose GPT-5 instance, Saves 93.7% of tokens (including inference and output) compared to GPT-5. This variable reasoning strategy is intended to produce snappy responses when needed and deep, thorough execution when warranted.
Core capabilities
- Project generation & bootstrapping: Create entire project skeletons with CI, tests, and basic documentation from high-level prompts.
- Agentic testing & iteration: Generate code, run tests, analyze failures, patch code, and rerun until tests pass — effectively automating parts of a developer’s edit → test → fix loop.
- Large-scale refactoring: Perform systematic refactors across many files while maintaining behavior and tests. This is a stated optimization area for GPT-5-Codex vs. generic GPT-5.
- Code review and PR generation: Produce PR descriptions, suggested changes with diffs, and review comments that align with project conventions and human review expectations.
- Large-context code reasoning: Better at navigating and reasoning about multi-file codebases, dependency graphs, and API boundaries compared with generic chat models.
- Visual inputs and outputs: When working in the cloud, GPT-5-Codex can accept images/screenshots, visually inspect progress, and attach visual artifacts (screenshots of built UI) to tasks — a practical boon for front-end debugging and visual QA workflows.
Editor and workflow integrations
Codex is deeply integrated into developer workflows:
- Codex CLI — terminal-first interaction, supports screenshots, to-do tracking, and agent approvals. The CLI is open-source and tuned for agentic coding workflows.
- Codex IDE extension — embeds the agent in VS Code (and forks) so you can preview local diffs, create cloud tasks, and move work between cloud and local contexts with preserved state.
- Codex Cloud / GitHub — cloud tasks can be configured to auto-review PRs, spawn temporary containers for testing, and attach task logs and screenshots to PR threads.
Notable limitations and tradeoffs
- Narrow optimization: Some non-coding production evals are slightly lower for GPT-5-Codex than for the general GPT-5 variant — a reminder that specialization can trade off generality.
- Test reliance: Agentic behavior depends on available automated tests. Codebases with poor test coverage will expose limits in automatic verification and may require human oversight.
What kinds of tasks is GPT-5-Codex especially good or bad at?
Good at: complex refactors, creating scaffolding for large projects, writing and fixing tests, following PR expectations, and diagnosing multi-file runtime issues.
Less good at: tasks that require up-to-the-minute or proprietary internal knowledge not provided in the workspace, or those that demand high-assurance correctness without human review (safety-critical systems still need experts). Independent reviews also note a mixed picture on raw code quality compared with other specialized coding models—strengths in agentic workflows do not uniformly translate into best-in-class correctness across every benchmark.
What do benchmarks reveal about GPT-5-Codex’s performance?
SWE-bench / SWE-bench Verified: OpenAI states that GPT-5-Codex outperforms GPT-5 on agentic coding benchmarks such as SWE-bench Verified, and shows gains on code refactor tasks drawn from large repositories.On the SWE-bench Verified dataset, which contains 500 real-world software engineering tasks, GPT-5-Codex achieved a success rate of 74.5%. This outperforms GPT-5’s 72.8% on the same benchmark, highlighting the agent’s improved capabilities. 500 programming tasks from real open source projects. Previously, only 477 tasks could be tested, but now all 500 tasks can be tested → more complete results.
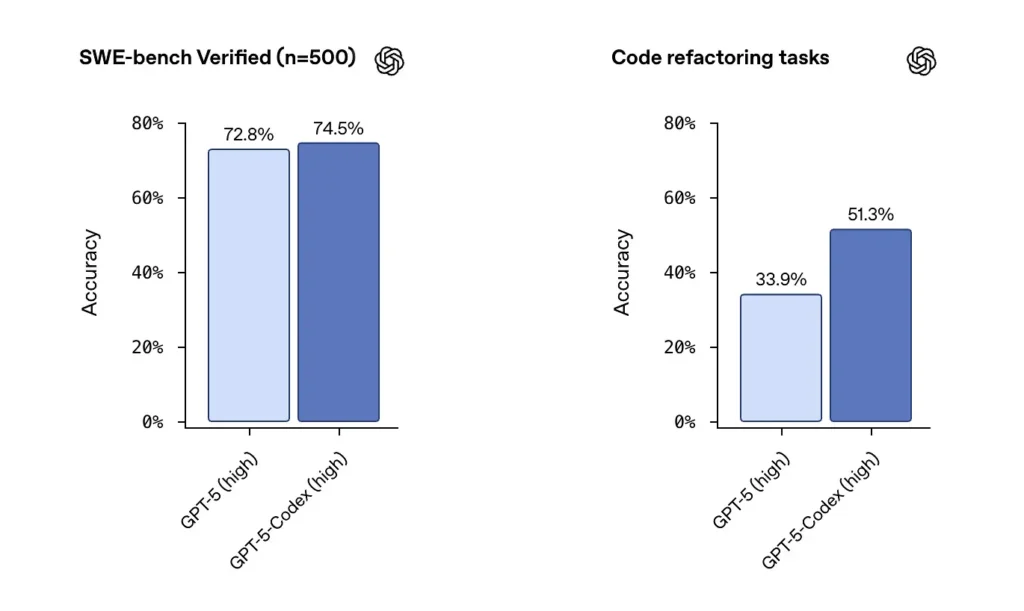
from earlier GPT-5 settings to GPT-5-Codex , code refactoring evaluation scores moved materially upward — numbers like the shift from ~34% to ~51% on a specific high-verbosity refactor metric were highlighted in early analyses). Those gains are meaningful in that they reflect improvement on large, realistic refactors rather than toy examples — but caveats remain about reproducibility and the exact test harness.
How can developers and teams access GPT-5-Codex?
OpenAI has rolled GPT-5-Codex into the Codex product surfaces: it’s live wherever Codex runs today (for example, the Codex CLI and integrated Codex experiences). For developers using Codex via CLI and ChatGPT sign-in, the updated Codex experience will surface the GPT-5-Codex model. OpenAI has said the model will be made available in the broader API “soon” for those using API keys, but as of initial rollout the primary access path is through Codex tools rather than a public API endpoint.
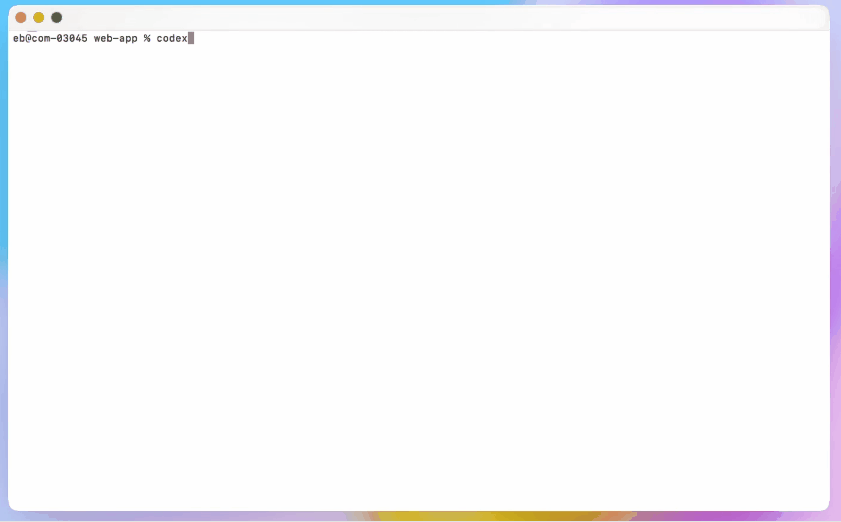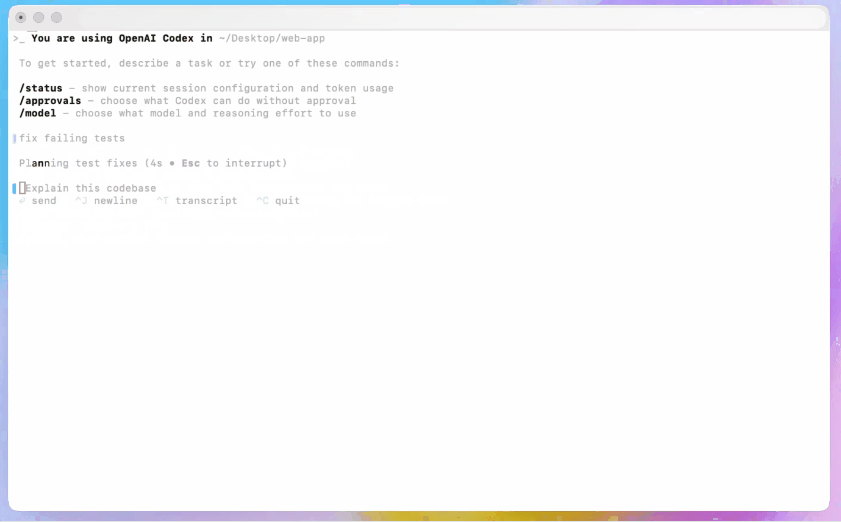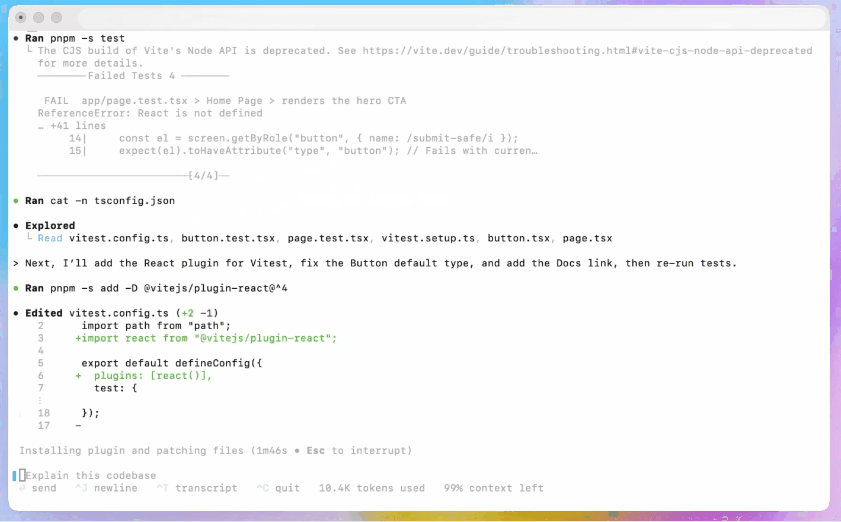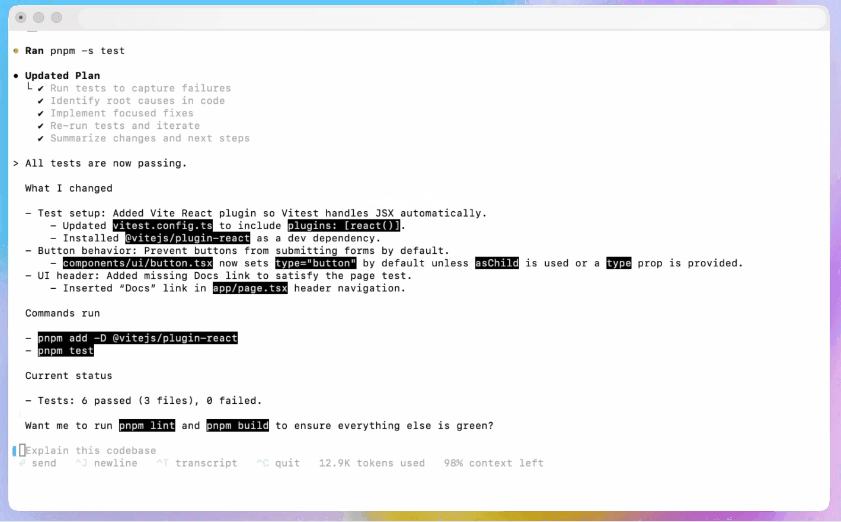
Codex CLI
Enable Codex to review draft PRs in a sandboxed repo so you can assess comment quality without risk. Use the approval modes conservatively.
- Redesigned around an agentic coding workflow.
- Support for attaching images (such as wireframes, designs, and UI bug screenshots) provides context for models.
- Added a task list feature to track the progress of complex tasks.
- Provided external tool support (web search, MCP connection).
- The new terminal interface improves tool invocation and diff formatting, and the permission mode has been simplified to three levels (read-only, automatic, and full access).
IDE Extension
Integrate into IDE workflows: add the Codex IDE extension for developers who want inline previews and quicker iteration. Moving tasks between cloud and local with preserved context can reduce friction on complex features.
- Supports VS Code, Cursor, and more.
- Invoke Codex directly from the editor to leverage the context of the currently opened file and code for more accurate results.
- Seamlessly switch tasks between local and cloud environments, maintaining contextual continuity.
- View and work with cloud task results right in the editor, without switching platforms.
GitHub Integration and Cloud Functions
- Automated PR Review: Automatically triggers progress from draft to ready.
- Supports developers to request targeted reviews directly in the @codex section of a PR.
- Significantly faster cloud infrastructure: Reduce task response times by 90% through container caching.
- Automated Environment Configuration: Executes setup scripts and installs dependencies (e.g., pip install).
- Automatically runs a browser, checks front-end implementations, and attaches screenshots to tasks or PRs.
What are the safety, security, and limitation considerations?
OpenAI emphasizes multiple layers of mitigation for Codex agents:
- Model-level training: targeted safety training to resist prompt injections and to limit harmful or high-risk behaviors.
- Product-level controls: sandboxed default behavior, configurable network access, approval modes for running commands, terminal logs and citations for traceability, and the ability to require human approvals for sensitive actions. OpenAI has also published a “system card addendum” describing these mitigations and their risk assessments, especially for biological and chemical domain capabilities.
Those controls reflect the fact that an agent capable of running commands and installing dependencies has real-world attack surface and risk — OpenAI’s approach is to combine model training with product constraints to limit misuse.
What are known limitations?
- Not a replacement for human reviewers: OpenAI explicitly recommends Codex as an additional reviewer, not a replacement. Human oversight remains critical, especially for security, licensing, and architecture decisions.
- Benchmarks and claims need careful reading: reviewers have pointed out differences in evaluation subsets, verbosity settings, and cost tradeoffs when comparing models. Early independent testing suggests mixed outcomes: Codex shows strong agentic behavior and refactoring improvements but relative accuracy vs other vendors varies by benchmark and configuration.
- Hallucinations and flaky behavior: like all LLMs, Codex can hallucinate (invent URLs, misstate dependency graphs), and its multi-hour agent runs may still encounter brittleness in edge cases. Expect to validate its outputs with tests and human review.
What are the broader implications for software engineering?
GPT-5-Codex demonstrates a maturing shift in LLM design: instead of only improving naked language capabilities, vendors are optimizing behavior for long, agentic tasks (multi-hour execution, test-driven development, integrated review pipelines). This changes the unit of productivity from a single generated snippet to task completion — the model’s ability to take a ticket, run a suite of tests, and iteratively produce a validated implementation. If these agents become robust and well-governed, they will reshape workflows (fewer manual refactors, quicker PR cycles, developer time focused on design and strategy). But the transition requires careful process design, human oversight, and safety governance.
Conclusion — What should you take away?
GPT-5-Codex is a focused step toward engineer-grade LLMs: a GPT-5 variant trained, tuned, and productized to act as a capable coding agent inside the Codex ecosystem. It brings tangible new behaviors — adaptive reasoning time, long autonomous runs, integrated sandboxed execution, and targeted code-review improvements — while maintaining the familiar caveats of language models (the need for human oversight, evaluation nuances, and occasional hallucinations). For teams, the prudent path is measured experimentation: pilot on safe repos, monitor outcome metrics, and fold the agent into reviewer workflows incrementally. As OpenAI expands API access and third-party benchmarks proliferate, we should expect clearer comparisons and more concrete guidance about cost, accuracy, and best-practice governance.
Getting Started
CometAPI is a unified API platform that aggregates over 500 AI models from leading providers—such as OpenAI’s GPT series, Google Gemini, Anthropic’s Claude, Midjourney, Suno, and more—into a single, developer-friendly interface. By offering consistent authentication, request formatting, and response handling, CometAPI dramatically simplifies the integration of AI capabilities into your applications. Whether you’re building chatbots, image generators, music composers, or data‐driven analytics pipelines, CometAPI lets you iterate faster, control costs, and remain vendor-agnostic—all while tapping into the latest breakthroughs across the AI ecosystem.
CometAPI promises to keep track of the latest model dynamics including GPT-5-Codex API, which will be released simultaneously with the official release. Please look forward to it and continue to pay attention to CometAPI. While waiting, you can pay attention to other models, explore the model’s capabilities in the Playground and consult the API guide for detailed instructions. Developers can access GPT-5 ,GPT-5 Nano and GPT-5 Mini through CometAPI, the cometAPI’s latest models listed are as of the article’s publication date. Before accessing, please make sure you have logged in to CometAPI and obtained the API key.


